This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Many data engineers and analysts start their journey with Postgres. It’s the Swiss Army knife of databases, and for many applications, it’s more than sufficient. But data volumes grow, analytical demands become more complex, and Postgres stops being enough.
What makes the Azure SQL database so popular for OLTP applications? What features of Microsoft Azure SQL database give it an edge over its competitors? To get answers to all these questions, read our ultimate guide on Azure SQL Database! Table of Contents What is Azure SQL Database? How To Connect To Azure SQL Database?
Planning out your data infrastructure in 2025 can feel wildly different than it did even five years ago. Everyone is talking about AI, chatbots, LLMs, vector databases, and whether your data stack is “AI-ready.” The ecosystem is louder, flashier, and more fragmented.
The Data News are here to stay, the format might vary during the year, but here we are for another year. We published videos about the Forward Data Conference, you can watch Hannes, DuckDB co-creator, keynote about Changing Large Tables. HNY 2025 ( credits ) Happy new year ✨ I wish you the best for 2025. Not really digest.
Think your customers will pay more for data visualizations in your application? Five years ago they may have. But today, dashboards and visualizations have become table stakes. Discover which features will differentiate your application and maximize the ROI of your embedded analytics. Brought to you by Logi Analytics.
Data Engineering is gradually becoming a popular career option for young enthusiasts. That's why we've created a comprehensive data engineering roadmap for 2023 to guide you through the essential skills and tools needed to become a successful data engineer. Let's dive into ProjectPro's Data Engineer Roadmap!
Imagine solving a complex puzzle where each piece represents a unique data point, and their connections form a vast network. Traditional databases often need help to capture these intricate relationships, leaving you with a fragmented view of your data. Table of Contents What is a Graph Database? Why Graph Databases?
The database landscape has reached 394 ranked systems across multiple categoriesrelational, document, key-value, graph, search engine, time series, and the rapidly emerging vector databases. As AI applications multiply quickly, vector technologies have become a frontier that data engineers must explore.
Until now, sharing data between enterprise systems often meant complex pipelines, duplication, and lock-in. With Oracles support for Delta Sharing, thats no longer the case.
Why do some embedded analytics projects succeed while others fail? We surveyed 500+ application teams embedding analytics to find out which analytics features actually move the needle. Read the 6th annual State of Embedded Analytics Report to discover new best practices. Brought to you by Logi Analytics.
In today's data-driven world, the ability to efficiently manage and manipulate data is a skill that transcends industries. Whether you're a data analyst, a web developer, or a business professional, Structured Query Language, or SQL, is a fundamental tool in your arsenal. This is where our SQLCheat Sheet comes to the rescue.
Explore the world of data analytics with the top AWS databases! Check out this blog to discover your ideal database and uncover the power of scalable and efficient solutions for all your data analytical requirements. Let’s understand more about AWS Databases in the following section.
Data lineage is an instrumental part of Metas Privacy Aware Infrastructure (PAI) initiative, a suite of technologies that efficiently protect user privacy. It is a critical and powerful tool for scalable discovery of relevant data and data flows, which supports privacy controls across Metas systems.
With a CAGR of 30%, the NoSQL Database Market is likely to surpass USD 36.50 Businesses worldwide are inclining towards analytical solutions to optimize their decision-making abilities based on data-driven techniques. Two of the most popular NoSQL database services available in the industry are AWS DynamoDB and MongoDB.
Every data-driven project calls for a review of your data architecture—and that includes embedded analytics. Before you add new dashboards and reports to your application, you need to evaluate your data architecture with analytics in mind. Expert guidelines for a high-performance, analytics-ready modern data architecture.
Traditional search methods face computational bottlenecks, especially when dealing with high-dimensional data, leading to slow query times and high resource usage. Want to find similar images in a massive database? This blog explores the FAISS Vector Database, a versatile tool applicable to various applications.
” This blog will align with that vision by exploring what Pinecone Vector Database is, how to use Pinecone Vector Database, and explore a comprehensive Pinecone Vector Database tutorial with a simple example. Table of Contents What is a Pinecone Vector Database? Pinecone is helpful in this situation.
Imagine you're a detective trying to identify a suspect from a database of millions of mugshots. Embeddings are numerical representations of data, like images, text, or audio. Each movie in your database has a description or review. Embedding Function: A function that calculates embeddings from raw data.
By Josep Ferrer , KDnuggets AI Content Specialist on June 10, 2025 in Python Image by Author DuckDB is a fast, in-process analytical database designed for modern data analysis. DuckDB is a free, open-source, in-process OLAP database built for fast, local analytics. Let’s dive in! What Is DuckDB? What Are DuckDB’s Main Features?
Many organizations today are unlocking the power of their data by using graph databases to feed downstream analytics, enahance visualizations, and more. Watch this essential video with Senzing CEO Jeff Jonas on how adding entity resolution to a graph database condenses network graphs to improve analytics and save your analysts time.
Does the LLM capture all the relevant data and context required for it to deliver useful insights? Not to mention the crazy stories about Gen AI making up answers without the data to back it up!) Are we allowed to use all the data, or are there copyright or privacy concerns? But simply moving the data wasnt enough.
Saying mainly that " Sora is a tool to extend creativity " Last point Mira has been mocked and criticised online because as a CTO she wasn't able to say on which public / licensed data Sora has been trained on. Pandera, a data validation library for dataframes, now supports Polars.
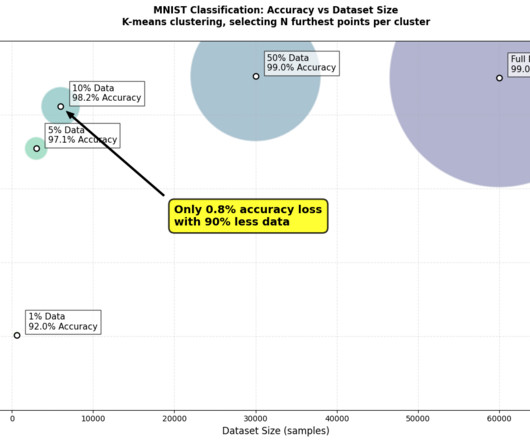
Building more efficient AI TLDR : Data-centric AI can create more efficient and accurate models. I experimented with data pruning on MNIST to classify handwritten digits. What if I told you that using just 50% of your training data could achieve better results than using the fulldataset? Image byauthor.
How CDC tools use MySQL Binlog and PostgreSQL WAL with logical decoding for real-time data streaming Photo by Matoo.Studio on Unsplash CDC (Change Data Capture) is a term that has been gaining significant attention over the past few years. Log-based CDC : This method utilizes the databases transaction log to capture every change made.
Here’s where leading futurist and investor Tomasz Tunguz thinks data and AI stands at the end of 2024—plus a few predictions of my own. 2025 data engineering trends incoming. Small data is the future of AI (Tomasz) 7. The lines are blurring for analysts and data engineers (Barr) 8. Table of Contents 1.
As we turn the corner into 2025, were excited to announce that for the 7th quarter in a row, Monte Carlo has been named G2s #1 Data Observability Platform, as well as #1 in the Data Quality category. Knowing our products are helping our customers achieve their data goals means everything to us. Image courtesy of G2.
Data storage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Three Zero-Cost Solutions That Take Hours, NotMonths A data quality certified pipeline. Source: unsplash.com In my career, data quality initiatives have usually meant big changes. Whats more, fixing the data quality issues this way often leads to new problems. Create a custom dashboard for your specific data qualityproblem.
Many of our customers — from Marriott to AT&T — start their journey with the Snowflake AI Data Cloud by migrating their data warehousing workloads to the platform. Today we’re focusing on customers who migrated from a cloud data warehouse to Snowflake and some of the benefits they saw. million in cost savings annually.
It’s easy these days for an organization’s data infrastructure to begin looking like a maze, with an accumulation of point solutions here and there. Snowflake is committed to doing just that by continually adding features to help our customers simplify how they architect their data infrastructure. Here’s a closer look.
Today, businesses use traditional data warehouses to centralize massive amounts of raw data from business operations. Since data needs to be accessible easily, organizations use Amazon Redshift as it offers seamless integration with business intelligence tools and helps you train and deploy machine learning models using SQL commands.
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data! REGISTER Ready to get started?
Data transformations are the engine room of modern data operations — powering innovations in AI, analytics and applications. As the core building blocks of any effective data strategy, these transformations are crucial for constructing robust and scalable data pipelines. This puts data engineers in a critical position.
The current database includes 2,000 server types in 130 regions and 340 zones. Storing data: data collected is stored to allow for historical comparisons. Results are stored in git and their database, together with benchmarking metadata. Visualizing the data: the frontend that allows querying of live and historic data.
Over the last three geospatial-centric blog posts, weve covered the basics of what geospatial data is, how it works in the broader world of data and how it specifically works in Snowflake based on our native support for GEOGRAPHY , GEOMETRY and H3. But there is so much more you can do with geospatial data in your Snowflake account!
Data modeling is a crucial skill for every big data professional, but it can be challenging to master. So, if you are preparing for a data modelling interview, you have landed on the right page. We have compiled the top 50 data modelling interview questions and answers from beginner to advanced levels. billion by 2028.
Discover 50+ Azure Data Factory interview questions and answers for all experience levels. A report by ResearchAndMarkets projects the global data integration market size to grow from USD 12.24 A report by ResearchAndMarkets projects the global data integration market size to grow from USD 12.24 billion in 2020 to USD 24.84
Agentic AI, small data, and the search for value in the age of the unstructured datastack. Heres where leading futurist and investor Tomasz Tunguz thinks data and AI stands at the end of 2024plus a few predictions of myown. 2025 data engineering trends incoming. Search: tools that leverage a corpus of data to answer questions 3.
Dagster Components is now here Components provides a modular architecture that enables data practitioners to self-serve while maintaining engineering quality. Understanding this fact will help data tools break new ground with the advancement of AI agents. and Lite 2.0) to pinpoint drop-offs and high retention sections.
Semih is a researcher and entrepreneur with a background in distributed systems and databases. He then pursued his doctoral studies at Stanford University, delving into the complexities of database systems. Dont forget to subscribe to my YouTube channel to get the latest on Unapologetically Technical!
Data is often referred to as the new oil, and just like oil requires refining to become useful fuel, data also needs a similar transformation to unlock its true value. This transformation is where data warehousing tools come into play, acting as the refining process for your data. Why Choose a Data Warehousing Tool?
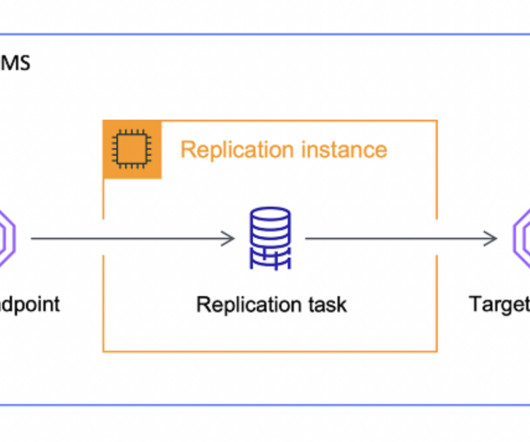
Whether it was moving data from a local database instance to S3 or some other data storage layer. As… Read more The post What Is AWS DMS And Why You Shouldn’t Use It As An ELT appeared first on Seattle Data Guy. It was interesting to see AWS DMS used in this manner. But it’s not what DMS was built for.
In the thought process of making a career transition from ETL developer to data engineer job roles? Read this blog to know how various data-specific roles, such as data engineer, data scientist, etc., differ from ETL developer and the additional skills you need to transition from ETL developer to data engineer job roles.
Are you a data science enthusiast looking to enhance your Python Flask skills? Check out these exciting python flask projects that will help you apply your Flask knowledge to solve real-world data science challenges. Here is the list of the best Python Flask projects ideal for data experts. This is where Python Flask comes in.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content