This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Data is the new oil in this century. The database is the major element of a data science project. To generate actionable insights, the database must be centralized and organized efficiently. So, we are […] The post How to Normalize Relational Databases With SQL Code?
Introduction SQL injection is an attack in which a malicious user can insert arbitrary SQL code into a web application’s query, allowing them to gain unauthorized access to a database. We can use this to steal sensitive information or make unauthorized changes to the data stored in the database.
Introduction In the bustling arena of database management systems, two heavyweight contenders emerge, each carrying its arsenal of features and capabilities. In one corner, we have the suave and sophisticated Microsoft SQL Server (MSSQL), donned in the elegance of enterprise-level prowess.
Introduction Structured Query Language is a powerful language to manage and manipulate data stored in databases. SQL is widely used in the field of data science and is considered an essential skill to have if you work with data.
This results in the generation of so much data daily. This generated data is stored in the database and will maintain it. SQL is a structured query language used to read and write these databases. Introduction In today’s world, technology has increased tremendously, and many people are using the internet.
SQL2Fabric Mirroring is a new fully managed service offered by Striim to mirror on premise SQLDatabases. It’s a collaborative service between Striim and Microsoft based on Fabric Open Mirroring that enables real-time data replication from on-premise SQL Server databases to Azure Fabric OneLake.
Introduction Data normalization is the process of building a database according to what is known as a canonical form, where the final product is a relational database with no data redundancy. More specifically, normalization involves organizing data according to attributes assigned as part of a larger data model.
Looking to learn SQL and databases to level up your data science skills? Learn SQL, database internals, and much more with these free university courses.
Summary Databases are the core of most applications, whether transactional or analytical. In recent years the selection of database products has exploded, making the critical decision of which engine(s) to use even more difficult. With Materialize, you can! Go to dataengineeringpodcast.com/materialize today to get 2 weeks free!
Introduction SQL is a database programming language created for managing and retrieving data from Relational databases like MySQL, Oracle, and SQL Server. SQL(Structured Query Language) is the common language for all databases. In other terms, SQL is a language that communicates with databases.
This week, we delve into the vital world of Databases, SQL, Data Management, and Statistical Concepts in Data Science. Welcome back to Week 2 of KDnuggets’ "Back to Basics" series.
The Data News are here to stay, the format might vary during the year, but here we are for another year. We published videos about the Forward Data Conference, you can watch Hannes, DuckDB co-creator, keynote about Changing Large Tables. HNY 2025 ( credits ) Happy new year ✨ I wish you the best for 2025. Not really digest.
Summary Stream processing systems have long been built with a code-first design, adding SQL as a layer on top of the existing framework. RisingWave is a database engine that was created specifically for stream processing, with S3 as the storage layer. Want to see Starburst in action?
The main thing I knew going in was "SDF understands SQL". For the next era of Analytics Engineering to be as transformative as the last, dbt needs to move beyond being a string preprocessor and into fully comprehending SQL. Today we're going to dig into what SQL comprehension actually means, since it's so critical to what comes next.
Summary A significant portion of data workflows involve storing and processing information in database engines. Validating that the information is stored and processed correctly can be complex and time-consuming, especially when the source and destination speak different dialects of SQL. Data lakes are notoriously complex.
Data lineage is an instrumental part of Metas Privacy Aware Infrastructure (PAI) initiative, a suite of technologies that efficiently protect user privacy. It is a critical and powerful tool for scalable discovery of relevant data and data flows, which supports privacy controls across Metas systems.
SQL is the essential data science language due to its universal database accessibility, efficient data cleaning capabilities, seamless integration with other languages, and requirement for most data science jobs.
Summary Databases come in a variety of formats for different use cases. The default association with the term "database" is relational engines, but non-relational engines are also used quite widely. Datafold has recently launched data replication testing, providing ongoing validation for source-to-target replication.
With yato you give a folder with SQL queries and it guesses the DAG and runs the queries in the right order. Saying mainly that " Sora is a tool to extend creativity " Last point Mira has been mocked and criticised online because as a CTO she wasn't able to say on which public / licensed data Sora has been trained on.
Introduction Data replication is also known as database replication, which is copying data to ensure that all information remains consistent across all data resources in real-time. data replication is like a safety net that keeps your information safe from disappearing or falling through the cracks.
Summary Data systems are inherently complex and often require integration of multiple technologies. This offers a single location for managing visibility and error handling so that data platform engineers can manage complexity. With Materialize, you can!
Summary Building a database engine requires a substantial amount of engineering effort and time investment. In this episode he explains how he used the combination of Apache Arrow, Flight, Datafusion, and Parquet to lay the foundation of the newest version of his time-series database. Data lakes are notoriously complex.
Summary Data persistence is one of the most challenging aspects of computer systems. In the era of the cloud most developers rely on hosted services to manage their databases, but what if you are a cloud service? It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products.
Three Zero-Cost Solutions That Take Hours, NotMonths A data quality certified pipeline. Source: unsplash.com In my career, data quality initiatives have usually meant big changes. Whats more, fixing the data quality issues this way often leads to new problems. Create a custom dashboard for your specific data qualityproblem.
The current database includes 2,000 server types in 130 regions and 340 zones. Storing data: data collected is stored to allow for historical comparisons. Results are stored in git and their database, together with benchmarking metadata. Visualizing the data: the frontend that allows querying of live and historic data.
Summary Kafka has become a ubiquitous technology, offering a simple method for coordinating events and data across different systems. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. Data lakes are notoriously complex.
Many of our customers — from Marriott to AT&T — start their journey with the Snowflake AI Data Cloud by migrating their data warehousing workloads to the platform. Today we’re focusing on customers who migrated from a cloud data warehouse to Snowflake and some of the benefits they saw. million in cost savings annually.
Graph databases are quickly becoming a core part of the analytics toolset for enterprise IT organizations. If you know SQL, you can easily learn Cypher and open up a huge opportunity for data analysis.
Summary A significant amount of time in data engineering is dedicated to building connections and semantic meaning around pieces of information. Linked data technologies provide a means of tightly coupling metadata with raw information. With Materialize, you can! Go to dataengineeringpodcast.com/materialize today to get 2 weeks free!
It’s easy these days for an organization’s data infrastructure to begin looking like a maze, with an accumulation of point solutions here and there. Snowflake is committed to doing just that by continually adding features to help our customers simplify how they architect their data infrastructure. Here’s a closer look.
Introduction In this constantly growing technical era, big data is at its peak, with the need for a tool to import and export the data between RDBMS and Hadoop. Apache Sqoop stands for “SQL to Hadoop,” and is one such tool that transfers data between Hadoop(HIVE, HBASE, HDFS, etc.)
cross-project dependencies ( credits ) Over the last few years, dbt has become a de facto standard enabling companies to collaborate easily on data transformations. With dbt, you can apply software engineering practices to SQL development. Managing your SQL patrimony has never been easier. See the doc. You can try it yourself.
dbt Core is an open-source framework that helps you organise data warehouse SQL transformation. dbt was born out of the analysis that more and more companies were switching from on-premise Hadoop data infrastructure to cloud data warehouses. This switch has been lead by modern data stack vision. Enter the ELT.
At Snowflake BUILD , we are introducing powerful new features designed to accelerate building and deploying generative AI applications on enterprise data, while helping you ensure trust and safety. These scalable models can handle millions of records, enabling you to efficiently build high-performing NLP data pipelines.
Summary The primary application of data has moved beyond analytics. With the broader audience comes the need to present data in a more approachable format. This has led to the broad adoption of data products being the delivery mechanism for information. With Materialize, you can!
In this episode he shares his journey of data collection and analysis and the challenges of automating an intentionally manual industry. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. With Materialize, you can!
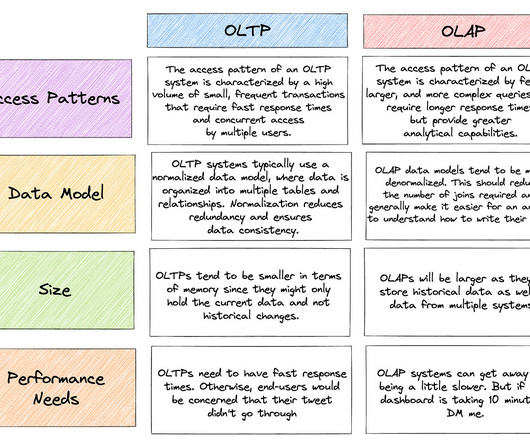
Adding databases like MongoDB and CassandraDB only makes matters worse, since they’re not SQL-friendly – the language most analysts and data practitioners are used to.… … Read more The post OLTP Vs OLAP – What Is The Difference appeared first on Seattle Data Guy.
Summary Cloud data warehouses and the introduction of the ELT paradigm has led to the creation of multiple options for flexible data integration, with a roughly equal distribution of commercial and open source options. It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products.
Before Hoptimator, Pinot ingestion often required data producers to create and manage separate, Pinot-specific preprocessing jobs to optimize data, such as re-keying, filtering, and pre-aggregating. reducing user friction, operator toil, and resource consumption on Pinot servers, while automating pipeline management.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content