This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A list to make evaluating ELT/ETLtools a bit less daunting Photo by Volodymyr Hryshchenko on Unsplash We’ve all been there: you’ve attended (many!) meetings with sales reps from all of the SaaS data integration tooling companies and are granted 14 day access to try their wares.
Thinking about and contemplating life and data engineering … something flitted across my […] The post Datafusion SQL CLI – Look Ma, I made a new ETLtool. appeared first on Confessions of a Data Guy.
The same, however triggers a sound ETL solution to handle the data correctly. This blog REST API ETLTools will talk about the various tools that will help you fetch data from Public APIs and […]
Are you confused about What is ETLTool? Do you want to gain a clear idea about how ETLTools work and how they come in handy for a business? This article aims at providing you with an in-depth guide about ETLTools. Well, look no further! It will help you gain knowledge about what […]
Are you trying to better understand the plethora of ETLtools available in the market to see if any of them fits your bill? Are you a Snowflake customer (or planning on becoming one) looking to extract and load data from a variety of sources? If any of the above questions apply to you, then […]
ETLtools have become important in efficiently handling integrated data. In this blog, we will discuss Fivetran vs AWS Glue, two influential ETLtools on the market. Overview of Fivetran G2 […]
Apache Hadoop is synonymous with big data for its cost-effectiveness and its attribute of scalability for processing petabytes of data. Data analysis using hadoop is just half the battle won. Getting data into the Hadoop cluster plays a critical role in any big data deployment. then you are on the right page.
By the time I left in 2013, I was a data engineer. We were developing new skills, new ways of doing things, new tools, and — more often than not — turning our backs to traditional methods. We were data engineers! Data Engineering? Like data scientists, data engineers write code. We were pioneers.
As data continues to grow in volume and complexity, the need for an efficient ETLtool becomes increasingly critical for a data professional. ETLtools not only streamline the process of extracting data from various sources but also transform it into a usable format and load it into a system of your choice.
Also: 6 Predictive Models Every Beginner Data Scientist Should Master; The Best ETLTools in 2021; Write Clean Python Code Using Pipes; Three R Libraries Every Data Scientist Should Know (Even if You Use Python).
What is Data Transformation? Data transformation is the process of converting raw data into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis. This understanding forms the basis for effective data transformation.
Amazon Redshift is a serverless, fully managed leading data warehouse in the market, and many organizations are migrating their legacy data to Redshift for better analytics. In this blog, we will discuss the best Redshift ETLtools that you can use to load data into Redshift.
What’s the best way to execute your data integration tasks: writing manual code or using ETLtool? Find out the approach that best fits your organization’s needs and the factors that influence it.
Tableau is a robust Business Intelligence tool that helps users visualize data simply and elegantly. Tableau has helped numerous organizations understand their customer data better through their Visual Analytics platform.
As data continues to grow at an unprecedented rate, the need for an efficient and scalable open-source ETL solution becomes increasingly pressing. However, with every organisation’s varying needs and the cluttered market for ETLtools, finding and choosing the right tool can be strenuous.
Its how you integrate AI with your first-party data to deliver new business value that sets you apart. And its not sufficient to simply build these data + AI applications – as in any other technological discipline, you have to do it reliably, too. So, what does it mean to achieve trusted data + AI?
In the data engineering industry, managing your data is critical for driving business. Data is gathered from various sources in all shapes and forms, and without the right set of tools, it is impossible to use this data for meaning analysis.
Did you know that data is now an essential component of modern business operations? With companies increasingly relying on data-driven insights to make informed decisions, there has never been a greater need for skilled specialists who can manage and evaluate vast amounts of data.
Modern businesses are data-driven – they use data in daily operations and decision-making. Data is collected from a variety of data storage systems, formats, and locations, and data engineers have a hefty job structuring, cleaning, and integrating this data.
If you are a data-driven business, then you must know how crucial it is to extract meaningful insights from your data. That’s where Reverse ETL comes into play. I’m guessing you might know what ETL (Extract, Transform, Load) is. It is the process of bringing data into your warehouses.
Business leaders use business intelligence (BI) to turn data into valuable insights and make strategic decisions within the company. And this strategy starts with data aggregation and integration. Realising the importance of ETL many businesses […]
Every enterprise is trying to collect and analyze data to get better insights into their business. Whether it is consuming log files, sensor metrics, and other unstructured data, most enterprises manage and deliver data to the data lake and leverage various applications like ETLtools, search engines, and databases for analysis.
Summary Applications of data have grown well beyond the venerable business intelligence dashboards that organizations have relied on for decades. Given this increased level of importance it has become necessary for everyone in the business to treat data as a product in the same way that software applications have driven the early 2000s.
ETL stands for Extract, Transform, and Load. ETL is a process of transferring data from various sources to target destinations/data warehouses and performing transformations in between to make data analysis ready. Managing data is a tedious task if done manually and leads to no guarantee of accuracy.
Red Pill Analytics was hired to first design and th en implement all the necessary data integration processes required to connect Oracle WMS Cloud with their on-premises systems. This left us with only two data integration requirements to solve: relational tables and REST APIs. Streaming data into Oracle WMS Cloud.
AWS Glue is a serverless ETL solution that helps organizations move data into enterprise-class data warehouses. It provides close integration with other AWS services, which appeals to businesses already invested significantly in AWS.
Platform Specific Tools and Advanced Techniques Photo by Christopher Burns on Unsplash The modern data ecosystem keeps evolving and new datatools emerge now and then. In this article, I want to talk about crucial things that affect data engineers. Are your data pipelines efficient? Data warehouse exmaple.
How to Identify Your Business-Critical Data Practical steps to identifying business-critical data models and dashboards and drive confidence in your data Source: synq.io This article has been co-written with Lindsay Murphy Not all data is created equal. There’s a good reason for this. Source: synq.io
According to the World Economic Forum, the amount of data generated per day will reach 463 exabytes (1 exabyte = 10 9 gigabytes) globally by the year 2025. Thus, almost every organization has access to large volumes of rich data and needs “experts” who can generate insights from this rich data.
As far as data pipeline construction and maintenance are concerned, ETL (Extract, Transform, Load) tools play a crucial role, and their selection determines success. When considering the market offerings, AWS Glue vs Matillion frequently stands out. In this blog, we […]
Explaining the difference, especially when they both work with something intangible such as data , is difficult. If you’re an executive who has a hard time understanding the underlying processes of data science and get confused with terminology, keep reading. Data science vs data engineering.
Need a better way to handle all that customer and marketing data in HubSpot. This article will explain how you can transfer your HubSpot data into Google BigQuery through various means, be it HubSpot’s API or an automated ETLtool like Hevo Data, which does it […] Transfer it to BigQuery.
In the modern world of data engineering, two concepts often find themselves in a semantic tug-of-war: data pipeline and ETL. Fast forward to the present day, and we now have data pipelines. However, they are not just an upgraded version of ETL. The data sources themselves are not built to perform analytics.
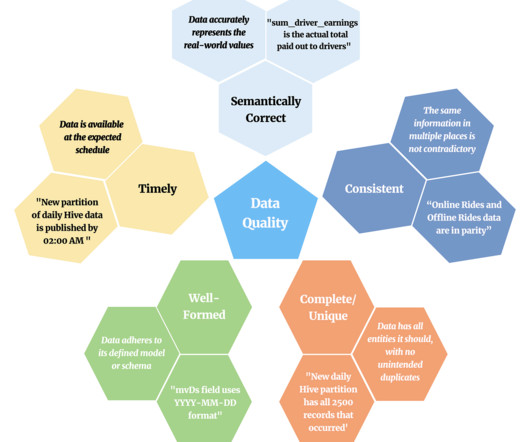
High-quality data is necessary for the success of every data-driven company. It is now the norm for tech companies to have a well-developed data platform. This makes it easy for engineers to generate, transform, store, and analyze data at the petabyte scale. What and Where is Data Quality?
Data Engineers of Netflix?—?Interview Interview with Kevin Wylie This post is part of our “Data Engineers of Netflix” series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Kevin Wylie is a Data Engineer on the Content Data Science and Engineering team.
RudderStack is the Warehouse Native CDP, built to help data teams deliver value across the entire data activation lifecycle, from collection to unification and activation. I included this post because I often see high-pitched LinkedIn posts stating it is the human fault, especially around data quality issues.
Data lineage can be a tremendously useful tool for data engineering and analytics, but is often treated as an afterthought both because of the challenges in implementation and the fact that it has not been broadly available within organizations. Lineage is dependencies – What is upstream of the final data that we are accessing?
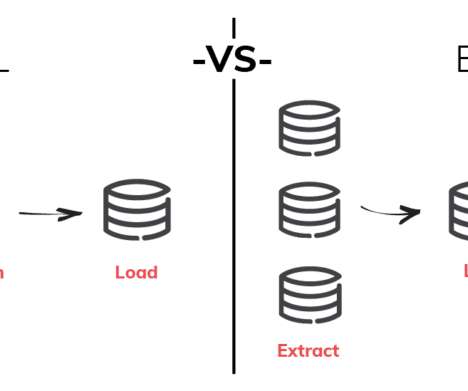
The last three years have seen a remarkable change in data infrastructure. ETL changed towards ELT. Now, data teams are embracing a new approach: reverse ETL. Cloud data warehouses, such as Snowflake and BigQuery, have made it simpler than ever to combine all of your data into one location. Let’s dive in!
All the cool kids are talking about Data Products and Data Mesh. The data companies have gotten ahold of terms and started to say their twenty-year-old ETLtools are the perfect tools to do that fashionable product-meshy stuff. What is going on?
ETL is a critical component of success for most data engineering teams, and with teams harnessing it with the power of AWS, the stakes are higher than ever. Data Engineers and Data Scientists require efficient methods for managing large databases, which is why centralized data warehouses are in high demand.
Businesses are increasingly depending on cloud platforms to manage and analyze their data in today's data-driven environment. Two of the most well-known cloud service providers, Amazon Web Services (AWS) and Microsoft Azure, provide reliable data engineering solutions. Azure Data Factory, Databricks, etc.
A 2016 data science report from data enrichment platform CrowdFlower found that data scientists spend around 80% of their time in data preparation (collecting, cleaning, and organizing of data) before they can even begin to build machine learning (ML) models to deliver business value.
Data integration is central to making informed business decisions for any organization in this data-driven world. ETLtools are central to this since they enable organizations to manage their data from different sources effectively and integrate it efficiently.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content