This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As AI applications multiply quickly, vector technologies have become a frontier that data engineers must explore. The essential questions to be answered are: When should you choose specialized vector solutions like Pinecone, Weaviate, or Qdrant over adding vector extensions to established databases like PostgreSQL or MySQL?
Introduction In this constantly growing technical era, big data is at its peak, with the need for a tool to import and export the data between RDBMS and Hadoop. Apache Sqoop stands for “SQL to Hadoop,” and is one such tool that transfers data between Hadoop(HIVE, HBASE, HDFS, etc.)
Summary There is a lot of attention on the database market and cloud data warehouses. While they provide a measure of convenience, they also require you to sacrifice a certain amount of control over your data. Firebolt is the fastest cloud data warehouse. Visit dataengineeringpodcast.com/firebolt to get started.
Introduction Why Change Data Capture Setup Prerequisites Source setup Destination setup Source, MySQL CDC, MySQL => PostgreSQL Pros and Cons Pros Cons Conclusion References Introduction Change data capture is a software design pattern used to track every change(update, insert, delete) to the data in a database.
Summary One of the longest running and most popular open source database projects is PostgreSQL. Because of its extensibility and a community focus on stability it has stayed relevant as the ecosystem of development environments and data requirements have changed and evolved over its lifetime.
PostgreSQL and MySQL are among the most popular open-source relational database management systems (RDMS) worldwide. Both RDMS enable businesses to organize and interlink large amounts of data, allowing for effective data management. That’s because MySQL isn’t fully SQL-compliant, while PostgreSQL is.
The journey toward achieving a robust data platform that secures all your data in one place can seem like a daunting one. But at Snowflake, we’re committed to making the first step the easiest — with seamless, cost-effective data ingestion to help bring your workloads into the AI Data Cloud with ease.
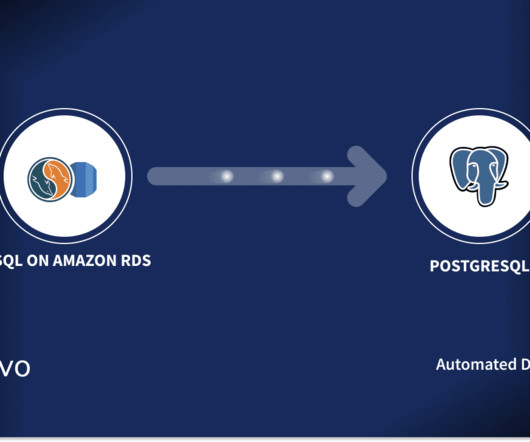
Are you struggling to migrate your data from MySQL on Amazon RDS to PostgreSQL? One of the common challenges with Amazon RDS MySQL is its data analytical and scalability capabilities, particularly when dealing with large datasets and high-traffic workloads. You’re not alone.
Amazon RDS supports PostgreSQL as one of its database engines, while MySQL continues to be a popular choice for many applications and organizations. Seamlessly connecting PostgreSQL on Amazon RDS to MySQL opens up new possibilities for data consolidation, analysis, and business intelligence.
Summary The most interesting and challenging bugs always happen in production, but recreating them is a constant challenge due to differences in the data that you are working with. Building your own scripts to replicate data from production is time consuming and error-prone. Can you describe what Tonic is and the story behind it?
This blog will demonstrate to you how Hasura and PostgreSQL can help you accelerate app development and easily launch backends. In this blog, we will cover: GraphQL Hasura PostgreSQL Hands-on Conclusion GraphQL GraphQL is an API query language and runtime for answering queries with existing data. Why Hasura is Fast?
MySQL has remained the most popularly used open-source relational database for many years and continues to maintain its dominant position in the industry. Migrating data from PostgreSQL on Google Cloud SQL to MySQL […] Migrating data from PostgreSQL on Google Cloud SQL to MySQL […]
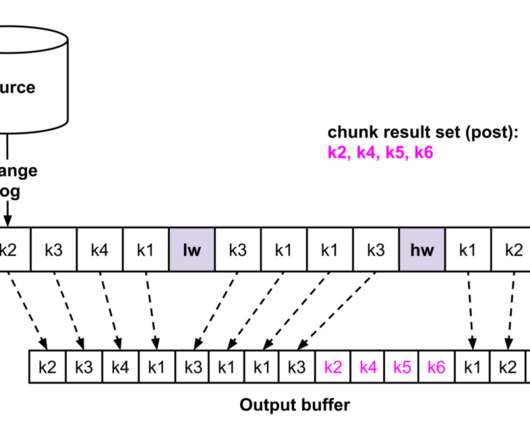
Andreas Andreakis , Ioannis Papapanagiotou Overview Change-Data-Capture (CDC) allows capturing committed changes from a database in real-time and propagating those changes to downstream consumers [1][2]. In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events.
Tallinn ( credits ) Dear members, it's Summer Data News, the only news you can consume by the pool, the beach or at the office—if you're not lucky. Joe is a great speaker, he wrote Fundamentals of Data Engineering , which is one of the bibles in data engineering and I can't wait to hear him at Forward Data.
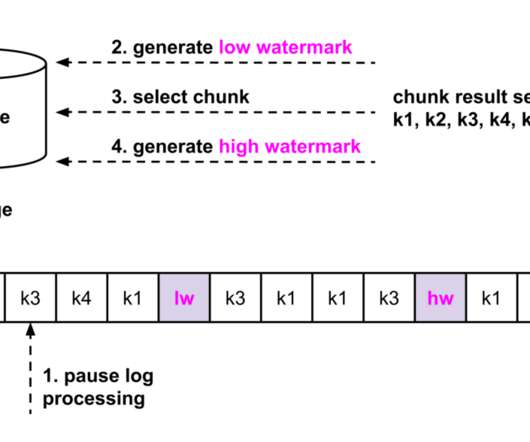
Andreas Andreakis , Ioannis Papapanagiotou Overview Change-Data-Capture (CDC) allows capturing committed changes from a database in real-time and propagating those changes to downstream consumers [1][2]. In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events.
Relational databases today are widely known to be suboptimal for supporting high-scale analytical use cases, and are all but certain to run into issues as your production data size and query volume grow. Rockset also has first-class query performance on a variety of complex queries and, most importantly, is horizontally scalable.
In the database ecosystem, Postgres is one of the top open-source databases, and one of the most widely used PSQL tools for managing PostgreSQL is pgAdmin. To run PostgreSQL instances on the Azure cloud, Azure offers Azure Database for PostgreSQL. What are PostgreSQL Tools? Why Use a GUI Tool?
Swiftly understanding the information is important in today's data-driven world. When managing massive amounts of data, having the right tools is vital. That is why we have compiled a MySQL tools list to consider in 2024. These advances help you improve your process and easily extract useful insights from your data.
The prospect of migrating data from one database to another can be very tricky and challenging, but the benefits of having a seamless transfer of data across different platforms is an enormous way of increasing the efficiency of any enterprise as well as increasing the productivity level of the outfit as downtime is significantly reduced. […] (..)
One of the main hindrances to getting value from our data is that we have to get data into a form that’s ready for analysis. Consider the hoops we have to jump through when working with semi-structured data, like JSON, in relational databases such as PostgreSQL and MySQL. Other data types require more thought.
Summary Databases are useful for inspecting the current state of your application, but inspecting the history of that data can get messy without a way to track changes as they happen. If you have ever struggled with implementing your own change data capture pipeline, or understanding when it would be useful then this episode is for you.
Summary The database is the core of any system because it holds the data that drives your entire experience. We spend countless hours designing the data model, updating engine versions, and tuning performance. RudderStack’s smart customer data pipeline is warehouse-first. How does it relate to your work with NoisePage?
Did you know Cloudera customers, such as SMG and Geisinger , offloaded their legacy DW environment to Cloudera Data Warehouse (CDW) to take advantage of CDW’s modern architecture and best-in-class performance? The Data Warehouse on Cloudera Data Platform provides easy to use self-service and advanced analytics use cases at scale.
We knew we’d be deploying a Docker container to Fargate as well as using an Amazon Aurora PostgreSQL database and Terraform to model our infrastructure as code. Set up a locally running containerized PostgreSQL database. No chance of accidentally touching any production data or systems. No infrastructure required in the cloud.
Summary A large fraction of data engineering work involves moving data from one storage location to another in order to support different access and query patterns. With simple pricing, fast networking, object storage, and worldwide data centers, you’ve got everything you need to run a bulletproof data platform.
Summary The optimal format for storage and retrieval of data is dependent on how it is going to be used. For analytical systems there are decades of investment in data warehouses and various modeling techniques. Data stacks are becoming more and more complex.
Summary Data lineage is something that has grown from a convenient feature to a critical need as data systems have grown in scale, complexity, and centrality to business. Alvin is a platform that aims to provide a low effort solution for data lineage capabilities focused on simplifying the work of data engineers.
Snowflake provides a strong data foundation anchored on unified data, optimal TCO and universal governance. The Snowflake platform eliminates silos to enable any architectural pattern, while supporting all data types and workloads. These capabilities can even be extended to Iceberg tables created by other engines.
In this post, I will demonstrate how to use the Cloudera Data Platform (CDP) and its streaming solutions to set up reliable data exchange in modern applications between high-scale microservices, and ensure that the internal state will stay consistent even under the highest load. It is implemented in Java using the Spring framework.
CSP allows developers, data analysts, and data scientists to build hybrid streaming data pipelines where time is a crucial factor, such as fraud detection, network threat analysis, instantaneous loan approvals, and so on. Kafka Connect : Service that makes it really easy to get large data sets in and out of Kafka.
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. How do we build data products ? How can we interoperate between the data domains ?
MySQL and PostgreSQL are widely used as transactional databases. Some challenges when doing analytics on MySQL and Postgres include: running a large number of concurrent queries/users working with large data sizes needing to define and manage tons of indexes. we did an integration with RDS MySQL on Rockset.
In this episode Michael Drogalis, product manager for ksqlDB at Confluent, explains how the system is implemented, how you can use it for building your own stream processing applications, and how it fits into the lifecycle of your data infrastructure. Are you spending too much time maintaining your data pipeline?
Summary The way that you store your data can have a huge impact on the ways that it can be practically used. Preamble Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline you’ll need somewhere to deploy it, so check out Linode.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Reading Time: 8 minutes Databases are essential in web development for organizing data in various forms and shapes (both structured and unstructured). With these GUIs, we can get a bird’s-eye view of all the data in our database for easy analysis of the schema or data types, as well as general ease of administration.
Introduction: Encryption of Data at Rest is a highly desirable or sometimes mandatory requirement for data platforms in a range of industry verticals including HealthCare, Financial & Government organizations. HDFS Encryption prevents access to clear text data. Each HDFS file is encrypted using an encryption key.
It is easy to use for MySQL and PostgreSQL. Amazon Aurora is a relational database engine compatible with MySQL and PostgreSQL. Aurora is five times faster than MySQL and three times faster than PostgreSQL. It achieves this by splitting its architecture into two planes: the Data Plane and the Control Plane.
One of the most common integrations that people want to do with Apache Kafka ® is getting data in from a database. The existing data in a database, and any changes to that data, can be streamed into a Kafka topic. Why is there no data? Resetting the point from which JDBC source connector reads data. JDBC drivers.
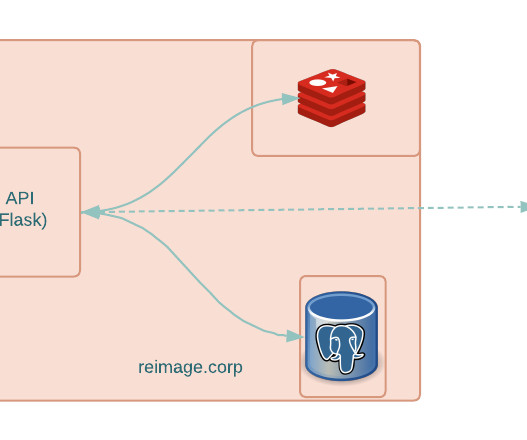
Often, unexpected delays crept in due to working through communications over a ticket; some issues often required a more hands-on approach and data-center technicians to intercede to take things forward. There was no redundancy for data stored in Redis; any data corruption would halt the cache layer, causing API response times to spike.
Adding to the Google Cloud Ready – BigQuery designation, Hevo Data has now also achieved the Google Cloud Ready – Cloud SQL designation for Cloud SQL, Google Cloud’s fully managed relational database service for MySQL, PostgreSQL, and SQL Server.
The former is an object storage service, and the latter is a relational database designed to be compatible with MySQL and PostgreSQL. While Amazon S3 offers robust features for managing and organizing your data, Aurora provides advanced querying capabilities. […]
Data Structures and Algorithms In simple terms, the way to organize and store data can be referred to as data structures. Create data storage and acceptance solutions for websites, especially those that take payments. The applicant will be familiar with Linux, MySQL, and Apache, in addition to Flask and SQLAlchemy.
Bringing together machine learning and data science For ML models and data science projects, Flask can be used as a front end or be wrapped around an API. Define and Access the Database in Flask Flask supports databases like SQLite, MySQL, and PostgreSQL. RESTful APIs : Build APIs to serve data for frontend apps.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content