This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Apache Cassandra is a NoSQL database management system that is open-source and distributed. It is meant to handle massive volumes of data across many commodity servers while maintaining high availability with no single point of failure.
Introduction Cassandra is an Apache-developed free and open-source distributed NoSQL database management system. It manages huge volumes of data across many commodity servers, ensures fault tolerance with the swift transfer of data, and provides high availability with no single point of failure.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management This episode is brought to you by Datafold – a testing automation platform for data engineers that prevents data quality issues from entering every part of your data workflow, from migration to dbt deployment.
Data drives the business world, and a significant amount of that data is unstructured. This implies that traditional relational databases can not cater to the needs of organizations seeking to store and manipulate this unstructured data. NoSQL Databases […]
Introduction Data replication is also known as database replication, which is copying data to ensure that all information remains consistent across all data resources in real-time. data replication is like a safety net that keeps your information safe from disappearing or falling through the cracks.
Making decisions in the database space requires deciding between RDBMS (Relational Database Management System) and NoSQL, each of which has unique features. RDBMS uses SQL to organize data into structured tables, whereas NoSQL is more flexible and can handle a wider range of data types because of its dynamic schemas.
A substantial amount of the data that is being managed in these systems is related to customers and their interactions with an organization. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex. Data projects are notoriously complex.
Last week, Rockset hosted a conversation with a few seasoned data architects and data practitioners steeped in NoSQL databases to talk about the current state of NoSQL in 2022 and how data teams should think about it. NoSQL is great for well understood access patterns. Much was discussed.
From Oracle, to NoSQL databases, and beyond, read about data management solutions from the early days of the RBDMS to those supporting AI applications.
The rise of AI and GenAI has brought about the rise of new questions in the data ecosystem – and new roles. One job that has become increasingly popular across enterprise data teams is the role of the AI data engineer. Demand for AI data engineers has grown rapidly in data-driven organizations.
Read my dbt multi-project guide 📺 On the content side I'll also present next week the Fancy Data Stack project at the Data Engineering And Machine Learning Summit 2023 organised by Seattle Data Guy. This post gives great insights about the impact on the data platform team. What are the main differences?
Big data in information technology is used to improve operations, provide better customer service, develop customized marketing campaigns, and take other actions to increase revenue and profits. It is especially true in the world of big data. It is especially true in the world of big data. What Are Big Data T echnologies?
This is the fifth post in a series by Rockset's CTO and Co-founder Dhruba Borthakur on Designing the Next Generation of Data Systems for Real-Time Analytics. So are schemaless NoSQL databases, which capably ingest firehoses of data but are poor at extracting complex insights from that data.
At Citus Data they have built an extension to support running it in a distributed fashion across large volumes of data with parallelized queries for improved performance. For someone who is interested in migrating to Citus, what is involved in getting it deployed and moving the data out of an existing system?
Jeremy Evans, Co-founder and CTO, Savvy At Savvy , we have a lot of responsibility when it comes to data. However, delivering rich and timely insights was a challenge for us from the start, as our original platform was great at ingesting data, but not so great at analyzing and reporting. Rockset was incredibly easy to get started.
My personal take on justifying the existence of Data Mesh A senior stakeholder at one my projects mentioned that they wanted to decentralise their data platform architecture and democratise data across the organisation. When I heard the words ‘decentralised data architecture’, I was left utterly confused at first!
Summary Designing the structure for your data warehouse is a complex and challenging process. As businesses deal with a growing number of sources and types of information that they need to integrate, they need a data modeling strategy that provides them with flexibility and speed.
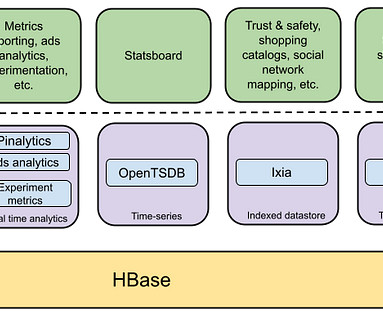
Overview of HBase at Pinterest Introduced in 2013, HBase was Pinterest’s first NoSQL datastore. Along with the rising popularity of NoSQL, HBase quickly became one of the most widely used storage backends at Pinterest. At its peak usage, we had around 50 clusters, 9000 AWS EC2 instances, and over 6 PBs of data.
Summary As communications between machines become more commonplace the need to store the generated data in a time-oriented manner increases. The market for timeseries data stores has many contenders, but they are not all built to solve the same problems or to scale in the same manner.
Summary Finding connections between data and the entities that they represent is a complex problem. Graph data models and the applications built on top of them are perfect for representing relationships and finding emergent structures in your information. If you hand a book to a new data engineer, what wisdom would you add to it?
The same principles of these systems can be adopted to filter out malformed data from datastores. This blog post deep dives into how we rebuilt one of our Cassandra(C*) clusters by removing malformed data using Yelp’s Data Pipeline. Many different features on Yelp are powered by Cassandra.
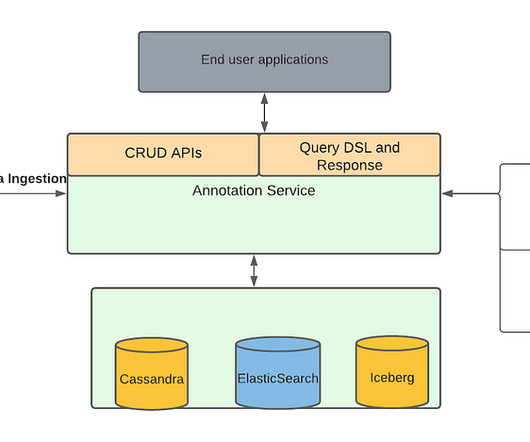
These media focused machine learning algorithms as well as other teams generate a lot of data from the media files, which we described in our previous blog , are stored as annotations in Marken. Similarly, client teams don’t have to worry about when or how the data is written. in a video file.
Big Data enjoys the hype around it and for a reason. But the understanding of the essence of Big Data and ways to analyze it is still blurred. And that’s the most important thing: Big Data analytics helps companies deal with business problems that couldn’t be solved with the help of traditional approaches and tools.
Summary There is a wealth of tools and systems available for processing data, but the user experience of integrating them and building workflows is still lacking. Raj Bains founded Prophecy to address this need by creating a UI first platform for building and executing data engineering workflows that orchestrates Airflow and Spark.
In this episode Philipp Krenn describes the various pieces of the stack, how they fit together, and how you can use them in your infrastructure to store, search, and analyze your data. What are the common scaling bottlenecks that users should be aware of when they are dealing with large volumes of data?
The concept of streaming data was born of necessity. But insights derived from day-old data don’t cut it. Business success is based on how we use continuously changing data. That’s where streaming data pipelines come into play. What is a streaming data pipeline? How do streaming data pipelines work?
Practices such as version controlled migration scripts and iterative schema evolution provide the necessary mechanisms to ensure that your data layer is as agile as your application. How has the prevalence of data abstractions such as ORMs or ODMs impacted the practice of schema design and evolution?
Summary With the increased ease of gaining access to servers in data centers across the world has come the need for supporting globally distributed data storage. What are some of the tradeoffs that are necessary to allow for georeplicated data with distributed transactions?
Data is the fuel that drives government, enables transparency, and powers citizen services. That should be easy, but when agencies don’t share data or applications, they don’t have a unified view of people. Legacy data sharing involves proliferating copies of data, creating data management, and security challenges.
Operational Database is a relational and non-relational database built on Apache HBase and is designed to support OLTP applications, which use big data. The operational database in Cloudera Data Platform has the following components: . Shared Data Experience (SDX) is used for security and governance capabilities.
Hadoop and Spark are the two most popular platforms for Big Data processing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Which Big Data tasks does Spark solve most effectively? How does it work? cost-effectiveness.
Have you ever wondered how the biggest brands in the world falter when it comes to data security? Their breach transformed personal customer data into a commodity traded on dark web forums. They react too slowly, too rigidly, and cant keep pace with the dynamic, sophisticated attacks occurring today, leaving hackable data exposed.
According to the World Economic Forum, the amount of data generated per day will reach 463 exabytes (1 exabyte = 10 9 gigabytes) globally by the year 2025. Thus, almost every organization has access to large volumes of rich data and needs “experts” who can generate insights from this rich data.
Reading Time: 8 minutes Databases are essential in web development for organizing data in various forms and shapes (both structured and unstructured). With these GUIs, we can get a bird’s-eye view of all the data in our database for easy analysis of the schema or data types, as well as general ease of administration.
Explaining the difference, especially when they both work with something intangible such as data , is difficult. If you’re an executive who has a hard time understanding the underlying processes of data science and get confused with terminology, keep reading. Data science vs data engineering.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. Second, developers had to constantly re-learn new data modeling practices and common yet critical data access patterns.
Data Engineering is typically a software engineering role that focuses deeply on data – namely, data workflows, data pipelines, and the ETL (Extract, Transform, Load) process. What is Data Science? What are the roles and responsibilities of a Data Engineer? What is the need for Data Science?
With the rise of modern data tools, real-time data processing is no longer a dream. The ability to react and process data has become critical for many systems. Over the past few years, MongoDB has become a popular choice for NoSQL Databases.
Learn the most important data engineering concepts that data scientists should be aware of. As the field of data science and machine learning continues to evolve, it is increasingly evident that data engineering cannot be separated from it.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Summary The way that you store your data can have a huge impact on the ways that it can be practically used. Preamble Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline you’ll need somewhere to deploy it, so check out Linode.
Introduction Data Engineer is responsible for managing the flow of data to be used to make better business decisions. A solid understanding of relational databases and SQL language is a must-have skill, as an ability to manipulate large amounts of data effectively. In 2022, data engineering will hold a share of 29.8%
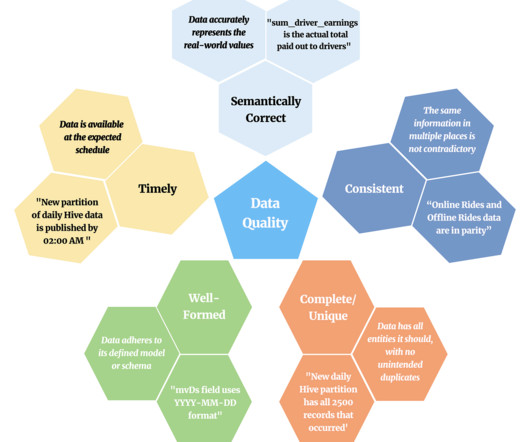
High-quality data is necessary for the success of every data-driven company. It is now the norm for tech companies to have a well-developed data platform. This makes it easy for engineers to generate, transform, store, and analyze data at the petabyte scale. What and Where is Data Quality?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content