This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Jayita Gulati on July 16, 2025 in Machine Learning Image by Editor In data science and machine learning, rawdata is rarely suitable for direct consumption by algorithms. Reduce model complexity : Well-designed features simplify the learning process, helping models train faster and avoid overfitting.
By Josep Ferrer , KDnuggets AI Content Specialist on July 15, 2025 in Data Science Image by Author Delivering the right data at the right time is a primary need for any organization in the data-driven society. But lets be honest: creating a reliable, scalable, and maintainable data pipeline is not an easy task.
By Bala Priya C , KDnuggets Contributing Editor & Technical Content Specialist on July 8, 2025 in Data Science Image by Author | Ideogram You know that feeling when you have data scattered across different formats and sources, and you need to make sense of it all? Thats exactly what were solving today.
By Cornellius Yudha Wijaya , KDnuggets Technical Content Specialist on July 17, 2025 in Data Science Image by Author | Ideogram Data is the asset that drives our work as data professionals. Without proper data, we cannot perform our tasks, and our business will fail to gain a competitive advantage. Let’s get into it.
Speaker: Donna Laquidara-Carr, PhD, LEED AP, Industry Insights Research Director at Dodge Construction Network
However, the sheer volume of tools and the complexity of leveraging their data effectively can be daunting. That’s where data-driven construction comes in. It integrates these digital solutions into everyday workflows, turning rawdata into actionable insights.
The Race For Data Quality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. By systematically moving data through these layers, the Medallion architecture enhances the data structure in a data lakehouse environment.
What is Data Transformation? Data transformation is the process of converting rawdata into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis.
A data engineering architecture is the structural framework that determines how data flows through an organization – from collection and storage to processing and analysis. It’s the big blueprint we data engineers follow in order to transform rawdata into valuable insights.
This blog aims to give you an overview of the data analysis process with a real-world business use case. Table of Contents The Motivation Behind Data Analysis Process What is Data Analysis? What is the goal of the analysis phase of the data analysis process? What is Data Analysis?
Data transformations are the engine room of modern data operations — powering innovations in AI, analytics and applications. As the core building blocks of any effective data strategy, these transformations are crucial for constructing robust and scalable data pipelines. This puts data engineers in a critical position.
This makes it hard to get clean, structured data from them. It will be used to extract the text from PDF files LangChain: A framework to build context-aware applications with language models (we’ll use it to process and chain document tasks). It will be used to process and organize the text properly.
Were sharing how Meta built support for data logs, which provide people with additional data about how they use our products. Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand.
Today, data engineers are constantly dealing with a flood of information and the challenge of turning it into something useful. The journey from rawdata to meaningful insights is no walk in the park. It requires a skillful blend of data engineering expertise and the strategic use of tools designed to streamline this process.
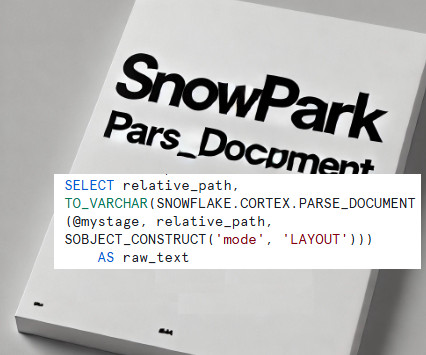
Read Time: 2 Minute, 33 Second Snowflakes PARSE_DOCUMENT function revolutionizes how unstructured data, such as PDF files, is processed within the Snowflake ecosystem. However, Ive taken this a step further, leveraging Snowpark to extend its capabilities and build a complete data extraction process. Why Use PARSE_DOC?
Every day, organizations are inundated with massive volumes of data. Whether tracking user behavior on a website, processing financial transactions, or monitoring smart devices, the need to make sense of this data is growing. What is Batch Processing?
Data engineering is the foundation for data science and analytics by integrating in-depth knowledge of data technology, reliable data governance and security, and a solid grasp of dataprocessing. Data engineers need to meet various requirements to build data pipelines.
These one-liners show how to extract meaningful info from data with minimal code while maintaining readability and efficiency. Calculate Mean, Median, and Mode When analyzing datasets, you often need multiple measures of central tendency to understand your datas distribution. times the IQR from the quartile boundaries.
Separating Substance from Hype In an industry notorious for rebranding existing technologies with shiny new names, the “Data Lakehouse” faces immediate skepticism. The answer, like many things in data engineering, is nuanced. When James Dixon coined “data lake” in 2010, he was responding to Hadoop’s promise of cheap, scalable storage.
Read Time: 2 Minute, 11 Second In today’s data-driven world, organizations demand powerful tools to transform, analyze, and present their data seamlessly. Imagine a rapidly growing e-commerce company, which processes thousands of transactions daily. They need to: Consolidate rawdata from orders, customers, and products.
This blog post provides an overview of the top 10 data engineering tools for building a robust data architecture to support smooth business operations. Table of Contents What are Data Engineering Tools? Dice Tech Jobs report 2020 indicates Data Engineering is one of the highest in-demand jobs worldwide.
ETL is a critical component of success for most data engineering teams, and with teams harnessing it with the power of AWS, the stakes are higher than ever. Data Engineers and Data Scientists require efficient methods for managing large databases, which is why centralized data warehouses are in high demand.
In recent years, you must have seen a significant rise in businesses deploying data engineering projects on cloud platforms. These businesses need data engineers who can use technologies for handling data quickly and effectively since they have to manage potentially profitable real-time data.
Want to process peta-byte scale data with real-time streaming ingestions rates, build 10 times faster data pipelines with 99.999% reliability, witness 20 x improvement in query performance compared to traditional data lakes, enter the world of Databricks Delta Lake now. Delta Lake is a game-changer for big data.
If you are planning to make a career transition into data engineering and want to know how to become a data engineer, this is the perfect place to begin your journey. Beginners will especially find it helpful if they want to know how to become a data engineer from scratch. Table of Contents What is a Data Engineer?
Let’s set the scene: your company collects data, and you need to do something useful with it. Whether it’s customer transactions, IoT sensor readings, or just an endless stream of social media hot takes, you need a reliable way to get that data from point A to point B while doing something clever with it along the way.
This guide is your roadmap to building a data lake from scratch. We'll break down the fundamentals, walk you through the architecture, and share actionable steps to set up a robust and scalable data lake. Traditional data storage systems like data warehouses were designed to handle structured and preprocessed data.
Over the years, individuals and businesses have continuously become data-driven. The urge to implement data-driven insights into business processes has consequently increased the data volumes involved. Open source tools like Apache Airflow have been developed to cope with the challenges of handling voluminous data.
Register now Home Insights Data platform Article How To Use Airbyte, dbt-teradata, Dagster, and Teradata Vantage™ for Seamless Data Integration Build and orchestrate a data pipeline in Teradata Vantage using Airbyte, Dagster, and dbt. In this case, we select Sample Data (Faker). dbt-core dagster==1.7.9
Read Time: 3 Minute, 21 Second Snowflake and DBT (Data Build Tool) are two of the most powerful players in the modern data stack. This combination streamlines ETL processes, increases flexibility, and reduces manual coding. Macro DBT Model: Ingest & Load the Data. But Isnt DBT Just for Transformations?
The total amount of data that was created in 2020 was 64 zettabytes! The volume and the variety of data captured have also rapidly increased, with critical system sources such as smartphones, power grids, stock exchanges, and healthcare adding more data sources as the storage capacity increases.
Pandas, a powerful data manipulation and analysis library in Python, has become a cornerstone of data science and machine learning workflows. In any machine learning project, data preprocessing and exploration are essential steps for building accurate and reliable models. This is where Pandas shines.
At Snowflake BUILD , we are introducing powerful new features designed to accelerate building and deploying generative AI applications on enterprise data, while helping you ensure trust and safety. These scalable models can handle millions of records, enabling you to efficiently build high-performing NLP data pipelines.
The demand for skilled data engineers who can build, maintain, and optimize large data infrastructures does not seem to slow down any sooner. At the heart of these data engineering skills lies SQL that helps data engineers manage and manipulate large amounts of data. of data engineer job postings on Indeed?
Cloud computing is the future, given that the data being produced and processed is increasing exponentially. As per the March 2022 report by statista.com, the volume for global data creation is likely to grow to more than 180 zettabytes over the next five years, whereas it was 64.2 It is a serverless big data analysis tool.
Manager, Technical Marketing Content Get the newsletter Subscribe to get our latest insights and product updates delivered to your inbox once a month As organizations adopt more tools and platforms, their data becomes increasingly fragmented across systems. And as the global data integration market is projected to grow from $17.10
Data preparation for machine learning algorithms is usually the first step in any data science project. It involves various steps like data collection, data quality check, data exploration, data merging, etc. This blog covers all the steps to master data preparation with machine learning datasets.
Quintillion Bytes of data per day. With such a vast amount of data available, dealing with and processingdata has become the main concern for companies. The problem lies in the real-world data. Unclean data usually occurs due to human error, scraping data, or combining multiple data sources.
Data preparation tools are very important in the analytics process. They transform rawdata into a clean and structured format ready for analysis. These tools simplify complex data-wrangling tasks like cleaning, merging, and formatting, thus saving precious time for analysts and data teams.
Unlock the power of your data with this comprehensive guide on how to design a data warehouse that delivers valuable insights to foster business growth! In another survey conducted by SAP, 75% of executives stated that data warehousing and business intelligence were important for their organizations to achieve their strategic goals.
Building data pipelines is a core skill for data engineers and data scientists as it helps them transform rawdata into actionable insights. You’ll walk through each stage of the dataprocessing workflow, similar to what’s used in production-grade systems.
Organizations generate massive amounts of data every day, yet most struggle to extract meaningful insights from their information assets. Despite investing billions in analytics platforms and hiring teams of data scientists, companies report a frustrating reality: critical business decisions still rely on gut instinct rather than evidence.
Discover 50+ Azure Data Factory interview questions and answers for all experience levels. A report by ResearchAndMarkets projects the global data integration market size to grow from USD 12.24 A report by ResearchAndMarkets projects the global data integration market size to grow from USD 12.24 billion in 2020 to USD 24.84
Get ready for your data engineering interview with this essential guide featuring the top DBT interview questions and answers for 2024. The growing demand for data-driven decision-making has made tools like DBT (Data Build Tool) essential in the modern data engineering landscape.
Building a batch pipeline is essential for processing large volumes of data efficiently and reliably. Are you ready to step into the heart of big data projects and take control of data like a pro? Are you ready to step into the heart of big data projects and take control of data like a pro?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content