This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Does the LLM capture all the relevant data and context required for it to deliver useful insights? Not to mention the crazy stories about Gen AI making up answers without the data to back it up!) Are we allowed to use all the data, or are there copyright or privacy concerns? But simply moving the data wasnt enough.
Data engineering is the foundation for data science and analytics by integrating in-depth knowledge of data technology, reliable data governance and security, and a solid grasp of data processing. Data engineers need to meet various requirements to build data pipelines.
Introduction A data lake is a centralized and scalable repository storing structured and unstructured data. The need for a data lake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
At Snowflake BUILD , we are introducing powerful new features designed to accelerate building and deploying generative AI applications on enterprise data, while helping you ensure trust and safety. These scalable models can handle millions of records, enabling you to efficiently build high-performing NLP data pipelines.
This guide is your roadmap to building a data lake from scratch. We'll break down the fundamentals, walk you through the architecture, and share actionable steps to set up a robust and scalable data lake. Traditional data storage systems like data warehouses were designed to handle structured and preprocessed data.
Register now Home Insights Data platform Article How To Use Airbyte, dbt-teradata, Dagster, and Teradata Vantage™ for Seamless Data Integration Build and orchestrate a data pipeline in Teradata Vantage using Airbyte, Dagster, and dbt. In this case, we select Sample Data (Faker). dbt-core dagster==1.7.9
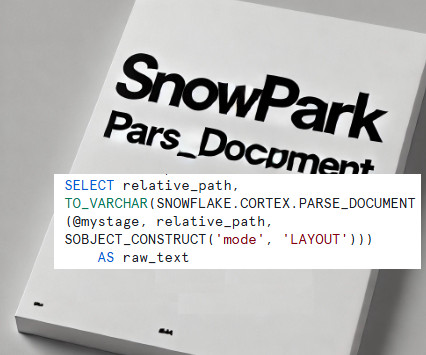
Read Time: 2 Minute, 33 Second Snowflakes PARSE_DOCUMENT function revolutionizes how unstructured data, such as PDF files, is processed within the Snowflake ecosystem. Traditionally, this function is used within SQL to extract structured content from documents. Apply advanced data cleansing and transformation logic using Python.
ETL is a critical component of success for most data engineering teams, and with teams harnessing it with the power of AWS, the stakes are higher than ever. Data Engineers and Data Scientists require efficient methods for managing large databases, which is why centralized data warehouses are in high demand.
Most of us have observed that data scientist is usually labeled the hottest job of the 21st century, but is it the only most desirable job? No, that is not the only job in the data world. These trends underscore the growing demand and significance of data engineering in driving innovation across industries.
The demand for skilled data engineers who can build, maintain, and optimize large data infrastructures does not seem to slow down any sooner. At the heart of these data engineering skills lies SQL that helps data engineers manage and manipulate large amounts of data. of data engineer job postings on Indeed?
Today, businesses use traditional data warehouses to centralize massive amounts of rawdata from business operations. Amazon Redshift is helping over 10000 customers with its unique features and data analytics properties. Table of Contents AWS Redshift Data Warehouse Architecture 1. Client Applications 2.
Data pipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. As data is expanding exponentially, organizations struggle to harness digital information's power for different business use cases. What is a Big Data Pipeline?
Let’s set the scene: your company collects data, and you need to do something useful with it. Whether it’s customer transactions, IoT sensor readings, or just an endless stream of social media hot takes, you need a reliable way to get that data from point A to point B while doing something clever with it along the way.
This makes it hard to get clean, structureddata from them. Args: pages_data: List of dictionaries representing each pages extracted data. Instead, they’re designed to look good, not to be read by programs. The text can be all over the place, split into weird blocks, scattered across the page, or mixed up with tables and images.
In this blog, you will learn all you need to know about using CookieCutter data science project template that streamlines project initiation, ensuring consistency and efficiency. In an era where data reigns supreme, propelling businesses to new heights, the significance of harnessing this digital gold cannot be overstated.
“Data Lake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms data lake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Data lake? Is Hadoop a data lake or data warehouse?
A data science pipeline represents a systematic approach to collecting, processing, analyzing, and visualizing data for informed decision-making. Data science pipelines are essential for streamlining data workflows, efficiently handling large volumes of data, and extracting valuable insights promptly.
This blog aims to give you an overview of the data analysis process with a real-world business use case. Table of Contents The Motivation Behind Data Analysis Process What is Data Analysis? What is the goal of the analysis phase of the data analysis process? What are the steps in the data analysis process?
A 2016 data science report from data enrichment platform CrowdFlower found that data scientists spend around 80% of their time in data preparation (collecting, cleaning, and organizing of data) before they can even begin to build machine learning (ML) models to deliver business value.
Over the past few years, data-related jobs have drastically increased. Previously, the spotlight was on gaining relevant insights from data, but recently, data handling has gained attention. Because of that, data engineer jobs have garnered recognition and popularity.
Microsoft Fabric is a next-generation data platform that combines business intelligence, data warehousing, real-time analytics, and data engineering into a single integrated SaaS framework. The architecture of Microsoft Fabric is based on several essential elements that work together to simplify data processes: 1.
Get ready for your data engineering interview with this essential guide featuring the top DBT interview questions and answers for 2024. The growing demand for data-driven decision-making has made tools like DBT (Data Build Tool) essential in the modern data engineering landscape.
Whether you are a data engineer, BI engineer , data analyst, or an ETL developer , understanding various ETL use cases and applications can help you make the most of your data by unleashing the power and capabilities of ETL in your organization. You have probably heard the saying, "data is the new oil".
You have complex, semi-structureddata—nested JSON or XML, for instance, containing mixed types, sparse fields, and null values. It's messy, you don't understand how it's structured, and new fields appear every so often. Organizations will typically build hard-to-maintain ETL pipelines to feed data into their SQL systems.
Business Intelligence and Artificial Intelligence are popular technologies that help organizations turn rawdata into actionable insights. While both BI and AI provide data-driven insights, they differ in how they help businesses gain a competitive edge in the data-driven marketplace. What is Business Intelligence?
This blog post provides an overview of the top 10 data engineering tools for building a robust data architecture to support smooth business operations. Table of Contents What are Data Engineering Tools? Dice Tech Jobs report 2020 indicates Data Engineering is one of the highest in-demand jobs worldwide.
Scala has been one of the most trusted and reliable programming languages for several tech giants and startups to develop and deploy their big data applications. Table of Contents What is Scala for Data Engineering? Why Should Data Engineers Learn Scala for Data Engineering?
Discover different types of LLM data analysis agents, learn how to build your own, and explore the steps on how to create an LLM-powered data analysis agent that processes market data, analyzes trends, and generates valuable insights for cryptocurrency traders and investors. But how do you build one? Let’s get into it!
Choosing the right data analysis tools is challenging, as no tool fits every need. This blog will help you determine which data analysis tool best fits your organization by exploring the top data analysis tools in the market with their key features, pros, and cons. Which data analysis software is suitable for smaller businesses?
Navigating the complexities of data engineering can be daunting, often leaving data engineers grappling with real-time data ingestion challenges. Our comprehensive guide will explore the real-time data ingestion process, enabling you to overcome these hurdles and transform your data into actionable insights.
If you're looking to break into the exciting field of big data or advance your big data career, being well-prepared for big data interview questions is essential. Get ready to expand your knowledge and take your big data career to the next level! “Data analytics is the future, and the future is NOW!
This blog will help you understand what data engineering is with an exciting data engineering example, why data engineering is becoming the sexier job of the 21st century is, what is data engineering role, and what data engineering skills you need to excel in the industry, Table of Contents What is Data Engineering?
Building data pipelines is a core skill for data engineers and data scientists as it helps them transform rawdata into actionable insights. You’ll walk through each stage of the data processing workflow, similar to what’s used in production-grade systems.
Experts predict that by 2025, the global big data and data engineering market will reach $125.89 With the right tools, mindset, and hands-on experience, you can become a key player in transforming how organizations use data to drive innovation and decision-making. But what does it take to become an ETL Data Engineer?
Becoming a successful aws data engineer demands you to learn AWS for data engineering and leverage its various services for building efficient business applications. million organizations that want to be data-driven choose AWS as their cloud services partner. Table of Contents Why Learn AWS for Data Engineering?
Data pipelines are the backbone of your business’s data architecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. Most importantly, these pipelines enable your team to transform data into actionable insights, demonstrating tangible business value.
We love SQL — our mission is to bring fast, real-time queries to messy, semi-structured real-world data and SQL is a core part of our effort. Datagrip , Jupyter , RStudio ) and data exploration / visualization (e.g. A SQL API allows our product to fit neatly into the stacks of our users without any workflow re-architecting.
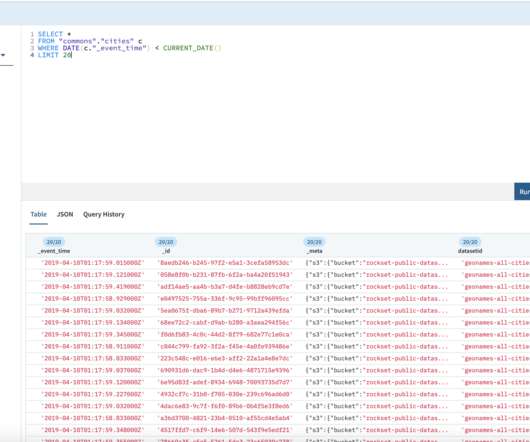
In this blog post, we show how Rockset’s Smart Schema feature lets developers use real-time SQL queries to extract meaningful insights from raw semi-structureddata ingested without a predefined schema. This is particularly true given the nature of real-world data.
According to IDC, 80% of the world’s data, primarily found on the web, will be unstructured." This explosive growth in online content has made web scraping essential for gathering data, but traditional scraping methods face limitations in handling unstructured information. Let's get started!
Managing complex data pipelines is a major challenge for data-driven organizations looking to accelerate analytics initiatives. While AI-powered, self-service BI platforms like ThoughtSpot can fully operationalize insights at scale by delivering visual data exploration and discovery, it still requires robust underlying data management.
If you're looking to revolutionize your data processing and analysis, Python for ETL is the key to unlock the door. Check out this ultimate guide to explore the fascinating world of ETL with Python and discover why it's the top choice for modern data enthusiasts. Python ETL really empowers you to transform data like a pro.
As the demand for big data grows, an increasing number of businesses are turning to cloud data warehouses. The cloud is the only platform to handle today's colossal data volumes because of its flexibility and scalability. Launched in 2014, Snowflake is one of the most popular cloud data solutions on the market.
This blog is your one-stop solution for the top 100+ Data Engineer Interview Questions and Answers. In this blog, we have collated the frequently asked data engineer interview questions based on tools and technologies that are highly useful for a data engineer in the Big Data industry. Why is Data Engineering In Demand?
In today’s data-driven landscape, organizations need robust solutions for managing, analyzing, and visualizing information. Microsoft offers two standout platforms that fulfill these needs, each addressing different stages of the data lifecycle. Its purpose is to simplify data exploration for users across skill levels.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content