This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Does the LLM capture all the relevant data and context required for it to deliver useful insights? Not to mention the crazy stories about Gen AI making up answers without the data to back it up!) Are we allowed to use all the data, or are there copyright or privacy concerns? But simply moving the data wasnt enough.
At Snowflake BUILD , we are introducing powerful new features designed to accelerate building and deploying generative AI applications on enterprise data, while helping you ensure trust and safety. These scalable models can handle millions of records, enabling you to efficiently build high-performing NLP data pipelines.
Data transformations are the engine room of modern data operations — powering innovations in AI, analytics and applications. As the core building blocks of any effective data strategy, these transformations are crucial for constructing robust and scalable data pipelines. This puts data engineers in a critical position.
Introduction A data lake is a centralized and scalable repository storing structured and unstructureddata. The need for a data lake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Want to process peta-byte scale data with real-time streaming ingestions rates, build 10 times faster data pipelines with 99.999% reliability, witness 20 x improvement in query performance compared to traditional data lakes, enter the world of Databricks Delta Lake now. It's a sobering thought - all that data, driving no value.
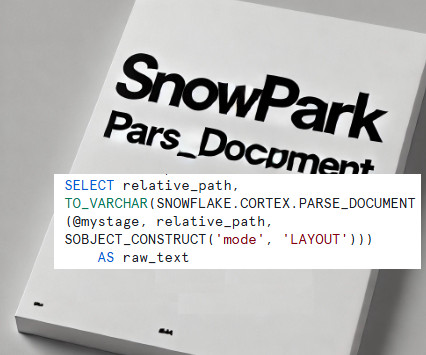
Read Time: 2 Minute, 33 Second Snowflakes PARSE_DOCUMENT function revolutionizes how unstructureddata, such as PDF files, is processed within the Snowflake ecosystem. However, Ive taken this a step further, leveraging Snowpark to extend its capabilities and build a complete data extraction process. Why Use PARSE_DOC?
The total amount of data that was created in 2020 was 64 zettabytes! The volume and the variety of data captured have also rapidly increased, with critical system sources such as smartphones, power grids, stock exchanges, and healthcare adding more data sources as the storage capacity increases.
If you are planning to make a career transition into data engineering and want to know how to become a data engineer, this is the perfect place to begin your journey. Beginners will especially find it helpful if they want to know how to become a data engineer from scratch. Table of Contents What is a Data Engineer?
This guide is your roadmap to building a data lake from scratch. We'll break down the fundamentals, walk you through the architecture, and share actionable steps to set up a robust and scalable data lake. Traditional data storage systems like data warehouses were designed to handle structured and preprocessed data.
In the thought process of making a career transition from ETL developer to data engineer job roles? Read this blog to know how various data-specific roles, such as data engineer, data scientist, etc., differ from ETL developer and the additional skills you need to transition from ETL developer to data engineer job roles.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
In recent years, you must have seen a significant rise in businesses deploying data engineering projects on cloud platforms. These businesses need data engineers who can use technologies for handling data quickly and effectively since they have to manage potentially profitable real-time data.
Data preparation for machine learning algorithms is usually the first step in any data science project. It involves various steps like data collection, data quality check, data exploration, data merging, etc. This blog covers all the steps to master data preparation with machine learning datasets.
Today, businesses use traditional data warehouses to centralize massive amounts of rawdata from business operations. Amazon Redshift is helping over 10000 customers with its unique features and data analytics properties. Table of Contents AWS Redshift Data Warehouse Architecture 1. Client Applications 2.
Cloud computing is the future, given that the data being produced and processed is increasing exponentially. As per the March 2022 report by statista.com, the volume for global data creation is likely to grow to more than 180 zettabytes over the next five years, whereas it was 64.2 Is AWS Athena a Good Choice for your Big Data Project?
Data pipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. As data is expanding exponentially, organizations struggle to harness digital information's power for different business use cases. What is a Big Data Pipeline?
Organizations generate tons of data every second, yet 80% of enterprise data remains unstructured and unleveraged (UnstructuredData). Organizations need data ingestion and integration to realize the complete value of their data assets.
Over a decade after the inception of the Hadoop project, the amount of unstructureddata available to modern applications continues to increase. This longevity is a testament to the community of analysts and data practitioners who are familiar with SQL as well as the mature ecosystem of tools around the language.
Organizations generate tons of data every second, yet 80% of enterprise data remains unstructured and unleveraged (UnstructuredData). Organizations need data ingestion and integration to realize the complete value of their data assets.
Do ETL and data integration activities seem complex to you? Read this blog to understand everything about AWS Glue that makes it one of the most popular data integration solutions in the industry. Did you know the global big data market will likely reach $268.4 Businesses are leveraging big data now more than ever.
Ready to ride the data wave from “ big data ” to “big data developer”? This blog is your ultimate gateway to transforming yourself into a skilled and successful Big Data Developer, where your analytical skills will refine rawdata into strategic gems. Is big data developer in demand?
Traditional ETL processes have long been a bottleneck for businesses looking to turn rawdata into actionable insights. Amazon, which generates massive volumes of data daily, faced this exact challenge. Zero ETL enables direct data querying in systems like Amazon Aurora, bypassing the need for time-consuming data preparation.
The global data analytics market is expected to reach 68.09 Businesses are finding new methods to benefit from data. Data engineering entails building data pipelines for ingesting, modifying, supplying, and sharing data for analysis. Table of Contents ETL vs ELT for Data Engineers What is ETL? What is ELT?
A data science pipeline represents a systematic approach to collecting, processing, analyzing, and visualizing data for informed decision-making. Data science pipelines are essential for streamlining data workflows, efficiently handling large volumes of data, and extracting valuable insights promptly.
This blog will help you understand what data engineering is with an exciting data engineering example, why data engineering is becoming the sexier job of the 21st century is, what is data engineering role, and what data engineering skills you need to excel in the industry, Table of Contents What is Data Engineering?
Building a batch pipeline is essential for processing large volumes of data efficiently and reliably. Are you ready to step into the heart of big data projects and take control of data like a pro? Are you ready to step into the heart of big data projects and take control of data like a pro?
Most of us have observed that data scientist is usually labeled the hottest job of the 21st century, but is it the only most desirable job? No, that is not the only job in the data world. These trends underscore the growing demand and significance of data engineering in driving innovation across industries.
These are the ways that data engineering improves our lives in the real world. The field of data engineering turns unstructureddata into ideas that can be used to change businesses and our lives. Data engineering can be used in any way we can think of in the real world because we live in a data-driven age.
Business Intelligence and Artificial Intelligence are popular technologies that help organizations turn rawdata into actionable insights. While both BI and AI provide data-driven insights, they differ in how they help businesses gain a competitive edge in the data-driven marketplace. What is Business Intelligence?
The Big Data industry will be $77 billion worth by 2023. According to a survey, big data engineering job interviews increased by 40% in 2020 compared to only a 10% rise in Data science job interviews. Table of Contents Big Data Engineer - The Market Demand Who is a Big Data Engineer? Who is a Big Data Engineer?
According to IDC, 80% of the world’s data, primarily found on the web, will be unstructured." This explosive growth in online content has made web scraping essential for gathering data, but traditional scraping methods face limitations in handling unstructured information. Let's get started!
Whether you are a data engineer, BI engineer , data analyst, or an ETL developer , understanding various ETL use cases and applications can help you make the most of your data by unleashing the power and capabilities of ETL in your organization. You have probably heard the saying, "data is the new oil".
If you're looking to break into the exciting field of big data or advance your big data career, being well-prepared for big data interview questions is essential. Get ready to expand your knowledge and take your big data career to the next level! “Data analytics is the future, and the future is NOW!
Struggling to handle messy data silos? Fear not, data engineers! This blog is your roadmap to building a data integration bridge out of chaos, leading to a world of streamlined insights. That's where data integration comes in, like the master blacksmith transforming scattered data into gleaming insights.
This blog is your one-stop solution for the top 100+ Data Engineer Interview Questions and Answers. In this blog, we have collated the frequently asked data engineer interview questions based on tools and technologies that are highly useful for a data engineer in the Big Data industry. Why is Data Engineering In Demand?
This blog post provides an overview of the top 10 data engineering tools for building a robust data architecture to support smooth business operations. Table of Contents What are Data Engineering Tools? Dice Tech Jobs report 2020 indicates Data Engineering is one of the highest in-demand jobs worldwide.
A 2016 data science report from data enrichment platform CrowdFlower found that data scientists spend around 80% of their time in data preparation (collecting, cleaning, and organizing of data) before they can even begin to build machine learning (ML) models to deliver business value.
Discover different types of LLM data analysis agents, learn how to build your own, and explore the steps on how to create an LLM-powered data analysis agent that processes market data, analyzes trends, and generates valuable insights for cryptocurrency traders and investors. But how do you build one? Let’s get into it!
Data Engineering Learn about slow change dimensions (SCD) and how to implement SCD Type 2 in VDK Photo by Joshua Sortino on Unsplash Data is the backbone of any organization, and in today’s fast-paced world, it is crucial to keep track of its versions. They store and manage current and historical data in a data warehouse.
Data wrangling is as essential to the data science process as the sun is important for plants to complete the process of photosynthesis. Data wrangling involves extracting the most valuable information from the data per a business's objectives and requirements. Table of Contents What is Data Wrangling in Data Science?
“Data Lake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms data lake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Data lake? Is Hadoop a data lake or data warehouse?
Speaking of job vacancies, the two careers have high demands till date and in upcoming years are Data Scientist and a Software Engineer. Per the BLS, the expected growth rate of job vacancies for data scientists and software engineers is around 22% by 2030. What is Data Science? Get to know more about SQL for data science.
Navigating the complexities of data engineering can be daunting, often leaving data engineers grappling with real-time data ingestion challenges. Our comprehensive guide will explore the real-time data ingestion process, enabling you to overcome these hurdles and transform your data into actionable insights.
Becoming a data engineer can be challenging, but we are here to make the journey easier. In this blog, we have curated a list of the best data engineering courses so you can master this challenging field with confidence. Say goodbye to confusion and hello to a clear path to data engineering expertise!
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content