This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Data is the new oil in this century. The database is the major element of a data science project. To generate actionable insights, the database must be centralized and organized efficiently. So, we are […] The post How to Normalize RelationalDatabases With SQL Code?
In this episode Oren Eini, CEO and creator of RavenDB, explores the nuances of relational vs. non-relational engines, and the strategies for designing a non-relationaldatabase. Datafold has recently launched data replication testing, providing ongoing validation for source-to-target replication.
Does the LLM capture all the relevant data and context required for it to deliver useful insights? Not to mention the crazy stories about Gen AI making up answers without the data to back it up!) Are we allowed to use all the data, or are there copyright or privacy concerns? But simply moving the data wasnt enough.
Data storage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Introduction Data normalization is the process of building a database according to what is known as a canonical form, where the final product is a relationaldatabase with no data redundancy. More specifically, normalization involves organizing data according to attributes assigned as part of a larger data model.
Introduction Structured Query Language is a powerful language to manage and manipulate data stored in databases. SQL is widely used in the field of data science and is considered an essential skill to have if you work with data.
Introduction In this constantly growing technical era, big data is at its peak, with the need for a tool to import and export the data between RDBMS and Hadoop. Apache Sqoop stands for “SQL to Hadoop,” and is one such tool that transfers data between Hadoop(HIVE, HBASE, HDFS, etc.)
It’s easy these days for an organization’s data infrastructure to begin looking like a maze, with an accumulation of point solutions here and there. Snowflake is committed to doing just that by continually adding features to help our customers simplify how they architect their data infrastructure. Here’s a closer look.
Introduction SQL is a database programming language created for managing and retrieving data from Relationaldatabases like MySQL, Oracle, and SQL Server. SQL(Structured Query Language) is the common language for all databases. In other terms, SQL is a language that communicates with databases.
Anyone who’s been roaming around the forest of Data Engineering has probably run into many of the newish tools that have been growing rapidly around the concepts of Data Warehouses, Data Lakes, and Lake Houses … the merging of the old relationaldatabase functionality with TB and PB level cloud-based file storage systems.
Relationaldatabases like Postgres have been the backbone of enterprise data management for years. However, as data volumes grow and the need for flexibility, scalability, and advanced analytics increases, modern solutions like Apache Iceberg are becoming essential.
Big Data has become the dominant innovation in all high-performing companies. Notable businesses today focus their decision-making capabilities on knowledge gained from the study of big data. Big Data gives you an advantage in competition as true for businesses as it is for professionals working in the area of analytics.
Business transactions captured in relationaldatabases are critical to understanding the state of business operations. Since the value of data quickly drops over time, organizations need a way to analyze data as it is generated. What is Change Data Capture?
My personal take on justifying the existence of Data Mesh A senior stakeholder at one my projects mentioned that they wanted to decentralise their data platform architecture and democratise data across the organisation. When I heard the words ‘decentralised data architecture’, I was left utterly confused at first!
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms.
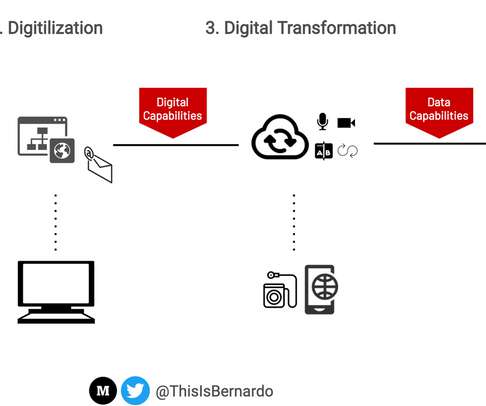
Companies can now make data useful to elevate decision making and to optimise products and processes. It's currently easy to acquire data strategically. If you ever have to explain to friends or colleagues why data capabilities are crucial to navigating the future of work and innovation, try this storytelling tactic. .
Experience Enterprise-Grade Apache Airflow Astro augments Airflow with enterprise-grade features to enhance productivity, meet scalability and availability demands across your data pipelines, and more. Databricks and Snowflake offer a data warehouse on top of cloud providers like AWS, Google Cloud, and Azure.
Relationaldatabases like Oracle have been the backbone of enterprise data management for years. However, as data volumes grow and the need for flexibility, scalability, and advanced analytics increases, modern solutions like Apache Iceberg are becoming essential.
What will the next important category of databases look like? For decades, relationaldatabases were the undisputed home of data. They powered everything: from websites to analytics, from customer data […].
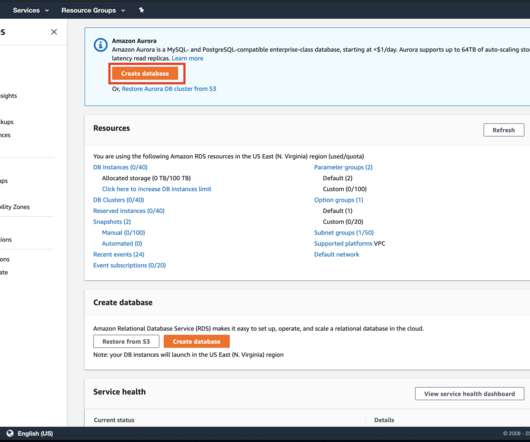
RDS AWS RDS is a managed service provided by AWS to run a relationaldatabase. Go to Services -> RDS Click on Create Database, In the Create Database prompt, choose Standard Create option with PostgreSQL as engine type. We will see how to setup a postgres instance using AWS RDS. Log in to your AWS account.
Data can be your organization’s most valuable asset, but only if it’s data you can trust. When companies work with data that is untrustworthy for any reason, it can result in incorrect insights, skewed analysis, and reckless recommendations to become data integrity vs data quality.
Summary Building a data platform is a complex journey that requires a significant amount of planning to do well. In this episode Tobias Macey, the host of the show, reflects on his plans for building a data platform and what he has learned from running the podcast that is influencing his choices. That’s Timescale.
How to use Kafka Streams to aggregate change data capture (CDC) messages from a relationaldatabase into transactional messages, powering a scalable microservices architecture.
Summary Data warehouses have gone through many transformations, from standard relationaldatabases on powerful hardware, to column oriented storage engines, to the current generation of cloud-native analytical engines. How does it compare to the other available platforms for data warehousing?
Traditional relationaldatabase systems are ubiquitous in software systems. They are surrounded by a strong ecosystem of tools, such as object-relational mappers and schema migration helpers. Today’s businesses, however, want to process ever-increasing amounts of data. All of these are enforced by relationaldatabases.
PostgreSQL is one of the most popular open-source choices for relationaldatabases. It is loved by engineers for its powerful features, flexibility, efficient data retrieval mechanism, and on top of all its overall performance. There are several […]
Introduction Data Engineer is responsible for managing the flow of data to be used to make better business decisions. A solid understanding of relationaldatabases and SQL language is a must-have skill, as an ability to manipulate large amounts of data effectively. What is a data warehouse?
Hadoop and Spark are the two most popular platforms for Big Data processing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Which Big Data tasks does Spark solve most effectively? How does it work? cost-effectiveness.
The journey toward achieving a robust data platform that secures all your data in one place can seem like a daunting one. But at Snowflake, we’re committed to making the first step the easiest — with seamless, cost-effective data ingestion to help bring your workloads into the AI Data Cloud with ease.
Summary Database indexes are critical to ensure fast lookups of your data, but they are inherently tied to the database engine. Pilosa is rewriting that equation by providing a flexible, scalable, performant engine for building an index of your data to enable high-speed aggregate analysis.
Summary Data observability is a term that has been co-opted by numerous vendors with varying ideas of what it should mean. With simple pricing, fast networking, object storage, and worldwide data centers, you’ve got everything you need to run a bulletproof data platform.
Summary Finding connections between data and the entities that they represent is a complex problem. Graph data models and the applications built on top of them are perfect for representing relationships and finding emergent structures in your information. If you hand a book to a new data engineer, what wisdom would you add to it?
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. How do we build data products ? How can we interoperate between the data domains ?
As a business grows, the demand to efficiently handle and process the exponentially growing data also rises. A popular open-source relationaldatabase used by several organizations across the world is PostgreSQL.
Summary A large fraction of data engineering work involves moving data from one storage location to another in order to support different access and query patterns. Singlestore aims to cut down on the number of database engines that you need to run so that you can reduce the amount of copying that is required.
For more than 40 years, relationaldatabases have been managed and modified using the programming language SQL (Structured Query Language). Given that it lets organizations efficiently store, retrieve, and analyze massive volumes of data, it has become an essential tool in their daily operations.
As long as there is ‘data’ in data scientist, Structured Query Language (or see-quel as we call it) will remain an important part of it. In this blog, let us explore data science and its relationship with SQL.
Data science is a field of study that works with large amounts of facts and uses splitting tools and methods to uncover hidden patterns, extract useful data, and make business choices. Data scientists use complex machine learning techniques to develop prediction models. Why Should You Learn Data Science?
ntroduction Data Analytics is an extremely important field in today’s business world, and it will only become more so as time goes on. By 2023, Data Analytics is projected to be worth USD 240.56 The Data Analyst interview questions are very competitive and difficult. How to track changes in databases?
What is Cloudera Operational Database (COD)? Operational Database is a relational and non-relationaldatabase built on Apache HBase and is designed to support OLTP applications, which use big data. The operational database in Cloudera Data Platform has the following components: .
Lior drove straight into the three reasons why data downtime happens: The three root causes of data downtime. Lior drove straight into the three reasons why data downtime happens: The three root causes of data downtime. For us, data quality monitoring is just the first step, something we all must move beyond.
Hum is harnessing frontier AI to transform content and audience data into actionable insights and personalized experiences. What problem does Hum aim to solve, and how are you using data to address the issue? To do that, they need rich data and powerful AI. Hum’s fast data store is built on Elasticsearch.
Being a data scientist means constantly growing, enabling businesses to become more data-propelled, and learning newer trends and tools. There are various excellent resources in data science that can help you to develop your skillset. So, having the right knowledge of tools and technology is important for handling such data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content