This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
dbt is the standard for creating governed, trustworthy datasets on top of your structureddata. We expect that over the coming years, structureddata is going to become heavily integrated into AI workflows and that dbt will play a key role in building and provisioning this data. What is MCP? Why does this matter?
Does the LLM capture all the relevant data and context required for it to deliver useful insights? Not to mention the crazy stories about Gen AI making up answers without the data to back it up!) Are we allowed to use all the data, or are there copyright or privacy concerns? But simply moving the data wasnt enough.
Retrieval Augmented Generation (RAG) is an efficient mechanism to provide relevant data as context in Gen AI applications. Most RAG applications typically use.
Much of the data we have used for analysis in traditional enterprises has been structureddata. However, much of the data that is being created and will be created comes in some form of unstructured format. However, the digital era… Read more The post What is Unstructured Data?
Snowflake Cortex AI now features native multimodal AI capabilities, eliminating data silos and the need for separate, expensive tools. This major enhancement brings the power to analyze images and other unstructured data directly into Snowflakes query engine, using familiar SQL at scale.
Agents need to access an organization's ever-growing structured and unstructured data to be effective and reliable. As data connections expand, managing access controls and efficiently retrieving accurate informationwhile maintaining strict privacy protocolsbecomes increasingly complex. text, audio) and structured (e.g.,
Together with a dozen experts and leaders at Snowflake, I have done exactly that, and today we debut the result: the “ Snowflake Data + AI Predictions 2024 ” report. When you’re running a large language model, you need observability into how the model may change as it ingests new data. The next evolution in data is making it AI ready.
Summary The process of exposing your data through a SQL interface has many possible pathways, each with their own complications and tradeoffs. One of the recent options is Rockset, a serverless platform for fast SQL analytics on semi-structured and structureddata. Visit Datacoral.com today to find out more.
Learn how to use large language models to extract insights from documents for analytics and ML at scale. Join this webinar and live tutorial to learn how to get started.
The article highlights various use cases of synthetic data, including generating confidential data, rebalancing imbalanced data, and imputing missing data points. It also provides information on popular synthetic data generation tools such as MOSTLY AI, SDV, and YData.
Here’s where leading futurist and investor Tomasz Tunguz thinks data and AI stands at the end of 2024—plus a few predictions of my own. 2025 data engineering trends incoming. Small data is the future of AI (Tomasz) 7. The lines are blurring for analysts and data engineers (Barr) 8. Table of Contents 1.
In this edition, we talk to Richard Meng, co-founder and CEO of ROE AI , a startup that empowers data teams to extract insights from unstructured, multimodal data including documents, images and web pages using familiar SQL queries. I experienced the thrilling pace of AI data innovation firsthand.
Data storage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structureddata and transactional workloads but struggled with performance at scale as data volumes grew.
Being able to leverage unstructured data is a critical part of an effective data strategy for 2025 and beyond. Even though its such a huge proportion of an enterprises data, many financial services organizations still dont know how to effectively use it. Parse data: What does analyzing unstructured data look like?
Use cases range from getting immediate insights from unstructured data such as images, documents and videos, to automating routine tasks so you can focus on higher-value work. Gen AI makes this all easy and accessible because anyone in an enterprise can simply interact with data by using natural language.
Agentic AI, small data, and the search for value in the age of the unstructured datastack. Heres where leading futurist and investor Tomasz Tunguz thinks data and AI stands at the end of 2024plus a few predictions of myown. 2025 data engineering trends incoming. Search: tools that leverage a corpus of data to answer questions 3.
Introduction In this constantly growing era, the volume of data is increasing rapidly, and tons of data points are produced every second. Now, businesses are looking for different types of data storage to store and manage their data effectively.
Large language models (LLMs) are transforming how we extract value from this data by running tasks from categorization to summarization and more. While AI has proved that real-time conversations in natural language are possible with LLMs, extracting insights from millions of unstructured data records using these LLMs can be a game changer.
We are excited to announce a new data type called variant for semi-structureddata. Variant provides an order of magnitude performance improvements compared.
At Snowflake BUILD , we are introducing powerful new features designed to accelerate building and deploying generative AI applications on enterprise data, while helping you ensure trust and safety. These scalable models can handle millions of records, enabling you to efficiently build high-performing NLP data pipelines.
In case you missed Part 1, An Introduction to Data Modeling, make sure to check first, where we discussed the importance of data modeling in data engineering, the history, and the increasing complexity of data. We have also touched upon the significance of understanding the data landscape, its challenges, and much more.
In case you missed Part 1, An Introduction to Data Modeling, make sure to check first, where we discussed the importance of data modeling in data engineering, the history, and the increasing complexity of data. We have also touched upon the significance of understanding the data landscape, its challenges, and much more.
The modern data stack constantly evolves, with new technologies promising to solve age-old problems like scalability, cost, and data silos. It promised to address key pain points: Scaling: Handling ever-increasing data volumes. Speed: Accelerating data insights. Data Silos: Breaking down barriers between data sources.
When it comes to transforming structureddata, (e.g., The Stored Procedure Activity in Data Factory provides and simple and convenient way to execute Stored Procedures. The Stored Procedure Activity in Data Factory provides and simple and convenient way to execute Stored Procedures.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like data warehouse , data lake and data lakehouse , and distributed patterns such as data mesh.
link] QuantumBlack: Solving data quality for gen AI applications Unstructured data processing is a top priority for enterprises that want to harness the power of GenAI. It brings challenges in data processing and quality, but what data quality means in unstructured data is a top question for every organization.
Let’s set the scene: your company collects data, and you need to do something useful with it. Whether it’s customer transactions, IoT sensor readings, or just an endless stream of social media hot takes, you need a reliable way to get that data from point A to point B while doing something clever with it along the way.
The real disruption lies with data + AI. In other words, when organizations combine their first-party data with LLMs to unlock unique insights, automate processes, or accelerate specialized workflows. We saw this with software and application observability; data and data observability; and soon data + AI and data + AI observability.
Selecting the appropriate data platform becomes crucial as businesses depend more and more on data to inform their decisions. Although they take quite different approaches, Microsoft Fabric and Snowflake, two of the top players in the current data landscape, both provide strong capabilities. What do you mean by Microsoft Fabric?
The rise of AI and GenAI has brought about the rise of new questions in the data ecosystem – and new roles. One job that has become increasingly popular across enterprise data teams is the role of the AI data engineer. Demand for AI data engineers has grown rapidly in data-driven organizations.
With Astro, you can build, run, and observe your data pipelines in one place, ensuring your mission critical data is delivered on time. link] Sponsored: Apache Airflow® Best Practices: Running Airflow at Scale The scalability of Airflow is why data teams at companies like Uber, Ford, and LinkedIn choose it to power their data ops.
We do not share data with the model provider. To address these issues the DeepSeek team describes how they incorporated cold-start data before RL for enhanced reasoning performance. Governance controls can be implemented consistently across data and AI. To request access during preview please reach out to your sales team.
Back to the usual Data News—with a little delay, I'm sorry. It's a subject close to my heart and I was very happy to share it with you, because I never thought that Data News would become such a big part of my life. I actually cover data engineering and how to put data stuff into production.
Introduction A data lake is a centralized and scalable repository storing structured and unstructured data. The need for a data lake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
link] Discord: How Discord Uses Open-Source Tools for Scalable Data Orchestration & Transformation Discord writes about its migration journey from a homegrown orchestration engine to Dagster. Techniques for turning text data and documents into vector embeddings and structureddata.
Even though Apache Spark SQL provides an API for structureddata, the framework sometimes behaves unexpectedly. It's the case of an insertInto operation that can even lead to some data quality issues. Let's try to understand in this short article.
Summary Data warehouse technology has been around for decades and has gone through several generational shifts in that time. The current trends in data warehousing are oriented around cloud native architectures that take advantage of dynamic scaling and the separation of compute and storage.
A 2016 data science report from data enrichment platform CrowdFlower found that data scientists spend around 80% of their time in data preparation (collecting, cleaning, and organizing of data) before they can even begin to build machine learning (ML) models to deliver business value.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Data integration and Democratization fabric. Introduction to the Data Mesh Architecture and its Required Capabilities. Components of a Data Mesh.
Summary Designing the structure for your data warehouse is a complex and challenging process. As businesses deal with a growing number of sources and types of information that they need to integrate, they need a data modeling strategy that provides them with flexibility and speed.
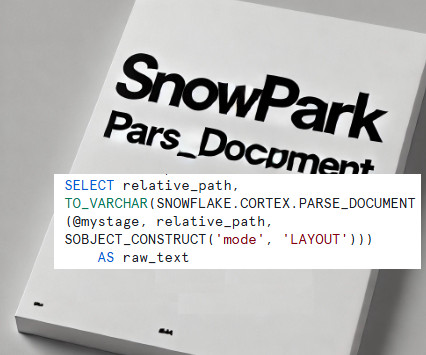
Read Time: 2 Minute, 33 Second Snowflakes PARSE_DOCUMENT function revolutionizes how unstructured data, such as PDF files, is processed within the Snowflake ecosystem. Traditionally, this function is used within SQL to extract structured content from documents. Apply advanced data cleansing and transformation logic using Python.
My personal take on justifying the existence of Data Mesh A senior stakeholder at one my projects mentioned that they wanted to decentralise their data platform architecture and democratise data across the organisation. When I heard the words ‘decentralised data architecture’, I was left utterly confused at first!
As a cohesive ERP solution, SAP is often one of the largest data resources in an organization, containing everything from financial and transactional data to master information about customers, vendors, materials, facilities, planning and even HR. What’s the challenge with unlocking SAP data?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content