This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The database is the major element of a data science project. To generate actionable insights, the database must be centralized and organized efficiently. If a corrupted, unorganized, or redundant database is used, the results of the analysis may become inconsistent and highly misleading. appeared first on Analytics Vidhya.
It’s the Swiss Army knife of databases, and for many applications, it’s more than sufficient. Therefore, you’ve probably come across terms like OLAP (Online Analytical Processing) systems, data warehouses, and, more recently, real-time analytical databases.
Introduction Data normalization is the process of building a database according to what is known as a canonical form, where the final product is a relational database with no data redundancy. More specifically, normalization involves organizing data according to attributes assigned as part of a larger data model.
Introduction In the bustling arena of database management systems, two heavyweight contenders emerge, each carrying its arsenal of features and capabilities. In one corner, we have the suave and sophisticated Microsoft SQL Server (MSSQL), donned in the elegance of enterprise-level prowess.
Why do some embedded analytics projects succeed while others fail? We surveyed 500+ application teams embedding analytics to find out which analytics features actually move the needle. Read the 6th annual State of Embedded Analytics Report to discover new best practices. Brought to you by Logi Analytics.
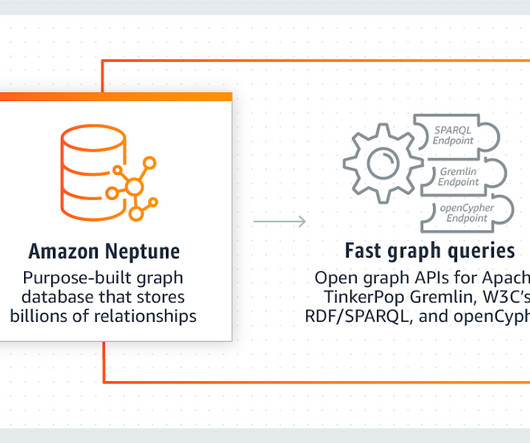
Traditional databases, while still valuable, often falter when it comes to handling highly connected data. Enter the unsung heroes of the data world: graph databases. This article discusses […] The post Neo4j vs. Amazon Neptune: Graph Databases in Data Engineering appeared first on Analytics Vidhya.
Introduction SQL injection is an attack in which a malicious user can insert arbitrary SQL code into a web application’s query, allowing them to gain unauthorized access to a database. We can use this to steal sensitive information or make unauthorized changes to the data stored in the database.
Summary Databases are the core of most applications, whether transactional or analytical. In recent years the selection of database products has exploded, making the critical decision of which engine(s) to use even more difficult. What are the aspects of the database market that keep you interested as a VP of product?
Summary Databases come in a variety of formats for different use cases. The default association with the term "database" is relational engines, but non-relational engines are also used quite widely. Can you describe what constitutes a NoSQL database? If you were to start from scratch today, what database would you build?
Think your customers will pay more for data visualizations in your application? Five years ago they may have. But today, dashboards and visualizations have become table stakes. Discover which features will differentiate your application and maximize the ROI of your embedded analytics. Brought to you by Logi Analytics.
Cloud databases have made it easier and cheaper to develop enterprise-level applications, offering flexibility, convenience, and standard database functionality. See what KDnuggets recommends.
Summary A significant portion of data workflows involve storing and processing information in database engines. Your host is Tobias Macey and today I'm welcoming back Gleb Mezhanskiy to talk about how to reconcile data in database environments Interview Introduction How did you get involved in the area of data management?
SQL2Fabric Mirroring is a new fully managed service offered by Striim to mirror on premise SQL Databases. It’s a collaborative service between Striim and Microsoft based on Fabric Open Mirroring that enables real-time data replication from on-premise SQL Server databases to Azure Fabric OneLake.
Many organizations today are unlocking the power of their data by using graph databases to feed downstream analytics, enahance visualizations, and more. Watch this essential video with Senzing CEO Jeff Jonas on how adding entity resolution to a graph database condenses network graphs to improve analytics and save your analysts time.
Looking to learn SQL and databases to level up your data science skills? Learn SQL, database internals, and much more with these free university courses.
Summary Building a database engine requires a substantial amount of engineering effort and time investment. In this episode he explains how he used the combination of Apache Arrow, Flight, Datafusion, and Parquet to lay the foundation of the newest version of his time-series database.
We will explore their use cases, key features, performance metrics, supported programming languages, and more to provide a comprehensive and unbiased overview of each database.
You’ll learn: 7 approaches to data architecture for embedded analytics—from a transactional database to a columnar or in memory database. Discover the pros and cons of each approach, plus how to choose the right architecture for your business priorities, timeline, and customers.
The top vector databases are known for their versatility, performance, scalability, consistency, and efficient algorithms in storing, indexing, and querying vector embeddings for AI applications.
The database landscape has reached 394 ranked systems across multiple categoriesrelational, document, key-value, graph, search engine, time series, and the rapidly emerging vector databases. What fundamental differences exist between AI-focused vector databases and analytical vector engines like DuckDB or DataFusion?
Introduction Data replication is also known as database replication, which is copying data to ensure that all information remains consistent across all data resources in real-time. data replication is like a safety net that keeps your information safe from disappearing or falling through the cracks. In most cases, data alters.
Semih is a researcher and entrepreneur with a background in distributed systems and databases. He then pursued his doctoral studies at Stanford University, delving into the complexities of database systems. Dont forget to subscribe to my YouTube channel to get the latest on Unapologetically Technical!
The current database includes 2,000 server types in 130 regions and 340 zones. Results are stored in git and their database, together with benchmarking metadata. Databases: SQLite files used to publish data Duck DB to query these files in the public APIs Cockroach DB : used to collect and store historical data.
Introduction Apache Cassandra is a NoSQL database management system that is open-source and distributed. It is meant to handle massive volumes of data across many commodity servers while maintaining high availability with no single point of failure. Facebook created Cassandra, which ultimately became an Apache Software Foundation project.
Everyone is talking about AI, chatbots, LLMs, vector databases, and whether your data stack is “AI-ready.” Planning out your data infrastructure in 2025 can feel wildly different than it did even five years ago. The ecosystem is louder, flashier, and more fragmented.
We didn’t build our applications in neat containers, but in bulky monoliths which commingled business, database, backend, and frontend logic. We dabbled in network engineering, database management, and system administration. Our deployments were initially manual. were in english only.
Whether we are analyzing IoT data streams, managing scheduled events, processing document uploads, responding to database changes, etc. Azure functions allow developers […] The post How to Develop Serverless Code Using Azure Functions? appeared first on Analytics Vidhya.
Traditionally, answering this question would require expensive GIS (Geographic Information Systems) software or complex database setups. ” This seemingly simple question requires analyzing competitor locations, population density, traffic patterns, and demographicsall spatial data.
Data storage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Introduction Cassandra is an Apache-developed free and open-source distributed NoSQL database management system. It manages huge volumes of data across many commodity servers, ensures fault tolerance with the swift transfer of data, and provides high availability with no single point of failure.
Especially while working with databases, it is often considered a good practice to follow a design pattern. Introduction A design pattern is simply a repeatable solution for problems that keep on reoccurring. The pattern is not an actual code but a template that can be used to solve problems in different situations.
This generated data is stored in the database and will maintain it. SQL is a structured query language used to read and write these databases. Introduction In today’s world, technology has increased tremendously, and many people are using the internet. This results in the generation of so much data daily.
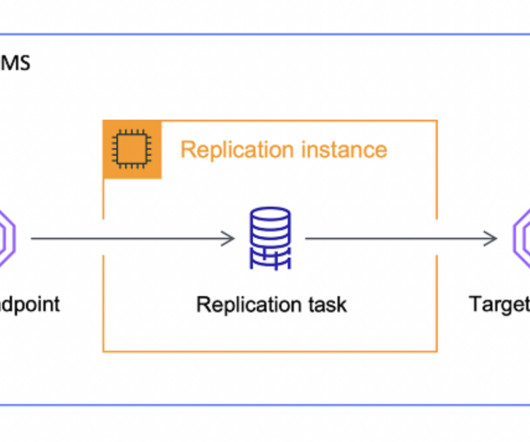
Whether it was moving data from a local database instance to S3 or some other data storage layer. Recently, I’ve encountered a few projects that used AWS DMS, which is almost like an ELT solution. It was interesting to see AWS DMS used in this manner. But it’s not what DMS was built for.
Materialization of data warehouse layers — What are the consideration for every materialisation you should pick in your data warehouse layer: view, tables, schema vs. databases, etc. The best code is the code you never wrote — Every line of code is a form of debt—a liability that must be maintained and understood.
As a new developer, a robust data modeling foundation is crucial for effectively working with databases. Introduction In the era of data-driven decision-making, having accurate data modeling tools is essential for businesses aiming to stay competitive.
Introduction SQL is a database programming language created for managing and retrieving data from Relational databases like MySQL, Oracle, and SQL Server. SQL(Structured Query Language) is the common language for all databases. In other terms, SQL is a language that communicates with databases.
In the Winter 2025 awards, we were recognized as #1 across the entire Data Observability, Data Quality, and Database Monitoring categories , as well as #1 in the Enterprise Relationship Index. All told, we’re featured in 71 reports, including the #1 spot in 31 reports, and we received 44 badges, including eight Leader badges!
Introduction Structured Query Language is a powerful language to manage and manipulate data stored in databases. After being introduced in the 70s, it has become the standard querying language for relational databases. […] The post Step-by-Step Roadmap to Learn SQL in 2023 appeared first on Analytics Vidhya.
Change Data Capture (CDC) is a crucial technology that enables organizations to efficiently track and capture changes in their databases. In this blog post, we’ll explore what CDC is, why it’s important, and our journey of implementing Generic CDC solutions for all online databases at Pinterest. What is Change Data Capture?
Microsoft’s open-source tool, Drasi, addresses this need by effortlessly detecting, monitoring, and responding to data changes across platforms, including relational and graph databases.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content