This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Unlocking Data Team Success: Are You Process-Centric or Data-Centric? We’ve identified two distinct types of data teams: process-centric and data-centric. We’ve identified two distinct types of data teams: process-centric and data-centric.
The major strategies in use today were created decades ago when the software and hardware for warehouse databases were far more constrained. In this episode Maxime Beauchemin of Airflow and Superset fame shares his vision for the entity-centric data model and how you can incorporate it into your own warehouse design.
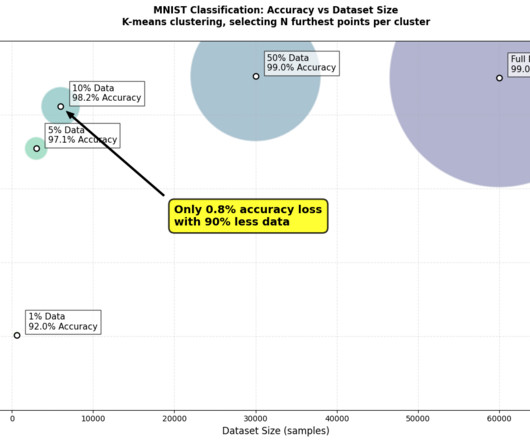
Building more efficient AI TLDR : Data-centric AI can create more efficient and accurate models. MNIST handwritten digit database. I experimented with data pruning on MNIST to classify handwritten digits. Best runs for furthest-from-centroid selection compared to full dataset. Image byauthor. References LeCun, Y., ATT Labs [Online].
Some departments used IBM Db2, while others relied on VSAM files or IMS databases creating complex data governance processes and costly data pipeline maintenance. With near real-time data synchronization, the solution ensures that databases stay in sync for reporting, analytics, and data warehousing.
The blog emphasizes the importance of starting with a clear client focus to avoid over-engineering and ensure user-centric development. impactdatasummit.com Thumbtack: What we learned building an ML infrastructure team at Thumbtack Thumbtack shares valuable insights from building its ML infrastructure team.
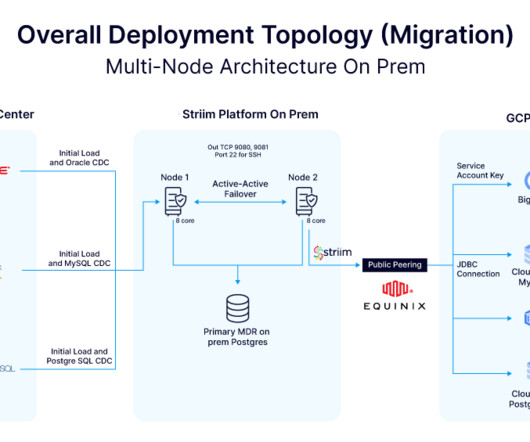
Known for its customer-centric approach and expansive product offerings, the company has maintained its leadership position in the industry for decades. Striim’s platform enabled the migration of data from legacy Oracle and PostgreSQL databases to Google BigQuery.
Adopting LLM in SQL-centric workflow is particularly interesting since companies increasingly try text-2-SQL to boost data usage. link] Murat Demirbas: Understanding the Performance Implications of Storage-Disaggregated Databases Serverless of anything (Postgres, Kafka, Redis) is the hot trend in infrastructure development.
Part 2: Types of graph intelligence for combating fraud To gain intelligence for combating fraud via graph, there are two graph algorithms. -> Type 1: Vertex-centric intelligence Vertex-centric graph intelligence helps us quantify the likelihood that the user is a bad actor.
Of course, this is not to imply that companies will become only software (there are still plenty of people in even the most software-centric companies), just that the full scope of the business is captured in an integrated software defined process. Here, the bank loan business division has essentially become software.
A decade ago, Picnic set out to reinvent grocery shopping with a tech-first, customer-centric approach. For instance, we built self-service tools for all our engineers that allow them to handle tasks like environment setup, database management, or feature deployment effectively.
Bronze layers can also be the raw database tables. In that case, a practical approach is to set up periodic polling of the Silver layer database to run data quality tests and check for anomalies at scheduled intervals. Bronze layers should be immutable. Alternatively, suppose you do not control the ingestion code.
Becoming a data-centric company is not optional — it’s essential to remain competitive, profitable and a desirable workplace. A strong data foundation helps companies ensure compliance with regulations and maintain data security, which are top priorities for handling sensitive customer information.
For those reasons, it is not surprising that it has taken over most of the modern data stack: infrastructure, databases, orchestration, data processing, AI/ML and beyond. That’s without mentioning the fact that for a cloud-native company, Tableau’s Windows-centric approach at the time didn’t work well for the team.
Managing and auditing access to your servers and databases is a problem that grows in difficulty alongside the growth of your teams. You listen to this show to learn and stay up to date with what’s happening in databases, streaming platforms, big data, and everything else you need to know about modern data management.
Storage and compute is cheaper than ever, and with the advent of distributed databases that scale out linearly, the scarcer resource is engineering time. The use of natural, human readable keys and dimension attributes in fact tables is becoming more common, reducing the need for costly joins that can be heavy on distributed databases.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Just connect it to your database/data warehouse/data lakehouse/whatever you’re using and let them do the rest.
link] Sponsored: DoubleCloud - More than just ClickHouse ClickHouse is the fastest, most resource-efficient OLAP database, which queries billions of rows in milliseconds and is trusted by thousands of companies for real-time analytics. The author highlights the structured approach to building data infrastructure, data management, and metrics.
At the same time Maxime Beauchemin wrote a post about Entity-Centric data modeling. If you want to go deeper to me Dozer looks like Materialize or Popsink but with a different vision, offering more an API as a serving layer than a database. I hope he will fill the gaps. When it comes to modeling it's hard not to mention dbt.
At the same time Maxime Beauchemin wrote a post about Entity-Centric data modeling. If you want to go deeper to me Dozer looks like Materialize or Popsink but with a different vision, offering more an API as a serving layer than a database. I hope he will fill the gaps. When it comes to modeling it's hard not to mention dbt.
The example we’ll walk you through will mirror a typical LLM application workflow you’d run to populate a vector database with some text knowledge. This data will move through different services (LLM, vector database, document store, etc.) Store embeddings in a vector database, either LanceDB , Pinecone , or Weaviate.
As the databases professor at my university used to say, it depends. Using SQL to run your search might be enough for your use case, but as your project requirements grow and more advanced features are needed—for example, enabling synonyms, multilingual search, or even machine learning—your relational database might not be enough.
Our customers are some of the most innovative, engineering-centric businesses on the planet, and helping them do great work will continue to be our focus.” On that same day, the threat actor downloaded data from another database that stores pipeline-level config vars for Review Apps and Heroku CI.
Most companies store their data in variety of formats across databases and text files. You’ll have a few different data stores: The database that backs your main app. Ride database. Customer service database. You’ll then need to store the parsed logs in a database, so they can easily be queried by the API.
Structured data can be defined as data that can be stored in relational databases, and unstructured data as everything else. Related to the neglect of data quality, it has been observed that much of the efforts in AI have been model-centric, that is, mostly devoted to developing and improving models , given fixed data sets.
[link] Murat: Understanding the Performance Implications of Storage-Disaggregated Databases The separation of storage and computing certainly brings a lot of flexibility in operating data stores. The author writes an overview of the performance implication of disaggregated systems compared to traditional monolithic databases.
Benefit #3: Ease of use With the Snowflake Native App Framework, everything needed to resolve or translate identifiers is loaded into the customer’s environment, appropriate permissions are granted so the app knows what database and tables it is allowed to access, and the customer is ready to go.
In the modern data-centric world, efficient data transfer and management are essential to staying competitive. AWS offers robust tools to facilitate this, including the AWS Database Migration Service (DMS).Most In 2024, over 11441 companies1 […]
Data Engineers are skilled professionals who lay the foundation of databases and architecture. Using database tools, they create a robust architecture and later implement the process to develop the database from zero. Data engineers who focus on databases work with data warehouses and develop different table schemas.
But this article is not about the pricing which can be very subjective depending on the context—what is 1200$ for dev tooling when you pay them more than $150k per year, yes it's US-centric but relevant. In my opinion sources have to be at schema/database level and YAML models have to be at the model level.
The database for Process Mining is also establishing itself as an important hub for Data Science and AI applications, as process traces are very granular and informative about what is really going on in the business processes. Note from the author: Although object-centric process mining was introduced by Wil M.P.
In this dynamic partnership, the fusion of Striim’s real-time data integration and streaming analytics capabilities with Yugabyte ‘s distributed SQL database, YugabyteDB, promises businesses unprecedented scalability, resilience, and global reach. “At Striim, we believe in the transformative potential of data.
At DareData Engineering, we believe in a human-centric approach, where AI agents work together with humans to achieve faster and more efficient results. At its core, RAG harnesses the power of large language models and vector databases to augment pre-trained models (such as GPT 3.5 ).
SQL – A database may be used to build data warehousing, combine it with other technologies, and analyze the data for commercial reasons with the help of strong SQL abilities. Pipeline-centric: Pipeline-centric Data Engineers collaborate with data researchers to maximize the use of the info they gather.
Their core value proposition is that streaming databases are inherently faster than Flink due to in-memory processing and state management. Kafka-centric approaches leave a lot to be desired, most notably operational complexity and difficulty integrating batch data, so there is certainly a gap to be filled. What about data lock-in?
The DataKitchen Platform serves as a process hub that builds temporary analytic databases for daily and weekly ad hoc analytics work. These limited-term databases can be generated as needed from automated recipes (orchestrated pipelines and qualification tests) stored and managed within the process hub. .
Data engineers who previously worked only with relational database management systems and SQL queries need training to take advantage of Hadoop. Apache HBase , a noSQL database on top of HDFS, is designed to store huge tables, with millions of columns and billions of rows. Complex programming environment. Data storage options.
The National Association of REALTORS ® clearly understands this challenge, which is why it built RPR (Realtors Property Resource), the nation’s largest parcel-centricdatabase, exclusively for REALTORS ®. To learn more about RPR and access its database for yourself, visit us online. While RPR can now offer high accuracy for U.S.
Kubernetes is a container-centric management software that allows the creation and deployment of containerized applications with ease. Here is a sample YAML file used to create a pod with the postgres database. To read more about Kubernetes and deployment, you can refer to the Best Kubernetes Course Online.
To illustrate that, let’s take Cloud SQL from the Google Cloud Platform that is a “Fully managed relational database service for MySQL, PostgreSQL, and SQL Server” It looks like this when you want to create an instance. You are starting to be an operation or technology centric data team.
2) Why High-Quality Data Products Beats Complexity in Building LLM Apps - Ananth Packildurai I will walk through the evolution of model-centric to data-centric AI and how data products and DPLM (Data Product Lifecycle Management) systems are vital for an organization's system.
Retrieval augmented generation (RAG) is an architecture framework introduced by Meta in 2020 that connects your large language model (LLM) to a curated, dynamic database. Data retrieval: Based on the query, the RAG system searches the database to find relevant data.
With One Lake serving as a primary multi-cloud repository, Fabric is designed with an open, lake-centric architecture. Mirroring (a data replication capability) : Access and manage any database or warehouse from Fabric without switching database clients; Mirroring will be available for Azure Cosmos DB, Azure SQL DB, Snowflake, and Mongo DB.
Data is centric in testing of several applications because data is critical to organizations. The tool successfully adheres to the importance of keeping test-data centric in Automation Test solutions. The test-data involved in both Manual/Automation testing encompasses the test-data inputs, test-data outputs, and the test-data flow.
This documentation is brand new and represents some of the most informative, developer-centric documentation on writing a connector to date. Kinetica develops an in-memory database accelerated by GPUs that can simultaneously ingest, analyze, and visualize event streaming data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content