This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
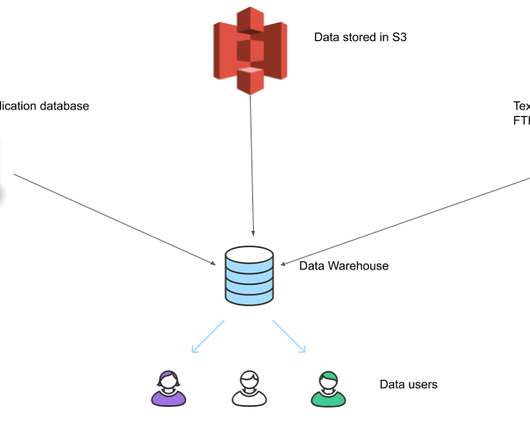
Intro A very common use case in data engineering is to build a ETLsystem for a data warehouse, to have data loaded in from multiple separate databases to enable data analysts/scientists to be able to run queries on this data, since the source databases are used by your applications and we do not want these analytic queries to affect our application (..)
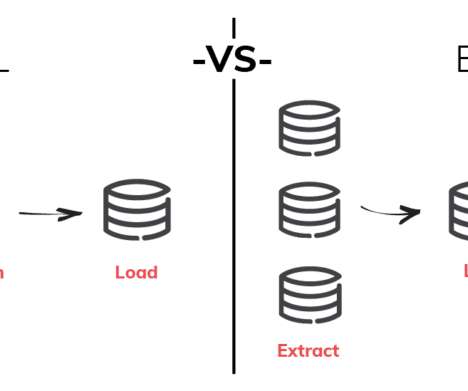
ETL is an abbreviation for extract-transform-load. These three database functions have been combined into a single tool to enable data extraction from one database and to store or maintain it in another. ETL is considered to be an essential part of data warehousing architecture in business processes worldwide.
This includes the different possible sources of data such as application APIs, social media, relational databases, IoT device sensors, and data lakes. This may include a data warehouse when it’s necessary to pipeline data from your warehouse to various destinations as in the case of a reverse ETL pipeline. featured image via unsplash
There are three layers in the ETL cycle: Staging layer: This layer stores the extracted data from multiple data sources. Data Integration layer: This layer performs data transformation from staging layer to database layer. What is the difference between OLAP tools and ETL tools? What do you mean by an ETL Pipeline?
ETL testing can be challenging since most ETLsystems process large volumes of heterogeneous data. However, establishing clear requirements from the start can make it easier for ETL testers to perform the required tests. Stages of the ETL Testing Process The ETL testing process can be broken down into 8 different stages.
How to Fit Reverse ETL Into Your Data Architecture Once businesses comprehend the advantages of reverse ETL, the question often is whether you should buy a reverse ETL solution or use your data team to build one for your company. First, building your custom reverse ETLsystem is more expensive than you think.
Two different systems are required for creating a kappa architecture: one for streaming data and another for batch processing. Stream processors, storage layers, message brokers, and databases make up the basic components of this architecture.
The Long Road from Batch to Real-Time Traditional “extract, transform, load” (ETL) systems were built under certain constraints, stemming from the cost of technology and implementation resources, as well as the inherent limits of computational power. Today’s world calls for a streaming-first approach.
To store and process even only a fraction of this amount of data, we need Big Data frameworks as traditional Databases would not be able to store so much data nor traditional processing systems would be able to process this data quickly. By 2020, it’s estimated that 1.7MB of data will be created every second for every person on earth.
Cloud Data engineering is all about designing, programming, and testing software, which is required for modern database solutions. Kafka is great for ETL and provides memory buffers that provide process reliability and resilience. SQL Today, more and more cloud-based systems add SQL-like interfaces that allow you to use SQL.
In a use case like online ticketing, it may seem obvious that the transactional side of the system is well suited to an event processing architecture, but certain of the analytical requirements demand the same architecture.
Another common breaking schema change scenario is when data teams sync their production database with their data warehouse as is the case with Freshly. When there is a schema change in our production database, Fivetran automatically rebuilds or materializes the new piece of data in a new table.
Another common breaking schema change scenario is when data teams sync their production database with their data warehouse as is the case with Freshly. When there is a schema change in our production database, Fivetran automatically rebuilds or materializes the new piece of data in a new table.
ETL (Extract, Transform, and Load) Pipeline involves data extraction from multiple sources like transaction databases, APIs, or other business systems, transforming it, and loading it into a cloud-hosted database or a cloud data warehouse for deeper analytics and business intelligence.
ETL (Extract, Transform, and Load) Pipeline involves data extraction from multiple sources like transaction databases, APIs, or other business systems, transforming it, and loading it into a cloud-hosted database or a cloud data warehouse for deeper analytics and business intelligence.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content