This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Kafka has become a ubiquitous technology, offering a simple method for coordinating events and data across different systems. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data.
We know that streaming data is data that is emitted at high volume […] The post Kafka to MongoDB: Building a Streamlined Data Pipeline appeared first on Analytics Vidhya. IT industries rely heavily on real-time insights derived from streaming data sources.
Learn how Kafka Connect and CDC provide real-time database synchronization, bridging data silos between all microservice applications. Microservices have numerous benefits, but data silos are incredibly challenging.
It addresses many of Kafka's challenges in analytical infrastructure. The combination of Kafka and Flink is not a perfect fit for real-time analytics; the integration of Kafka and Lakehouse is very shallow. How do you compare Fluss with Apache Kafka? Fluss and Kafka differ fundamentally in design principles.
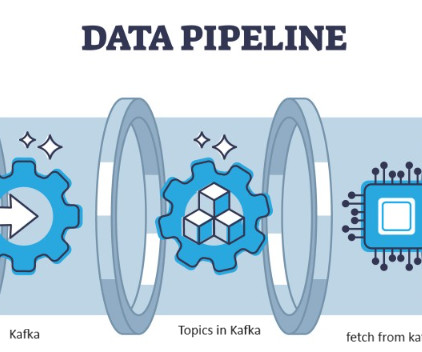
Your search for Apache Kafka interview questions ends right here! Let us now dive directly into the Apache Kafka interview questions and answers and help you get started with your Big Data interview preparation! What are topics in Apache Kafka? A stream of messages that belong to a particular category is called a topic in Kafka.
If you’re looking for everything a beginner needs to know about using Apache Kafka for real-time data streaming, you’ve come to the right place. This blog post explores the basics about Apache Kafka and its uses, the benefits of utilizing real-time data streaming, and how to set up your data pipeline. Let's dive in.
Today, Kafka is used by thousands of companies, including over 80% of the Fortune 100. Kafka's popularity is skyrocketing, and for good reason—it helps organizations manage real-time data streams and build scalable data architectures. As a result, there's a growing demand for highly skilled professionals in Kafka.
Kafka Topics are your trusty companions. Learn how Kafka Topics simplify the complex world of big data processing in this comprehensive blog. More than 80% of all Fortune 100 companies trust, and use Kafka. Apache Kafka The meteoric rise of Apache Kafka's popularity is no accident, as it plays a crucial role in data engineering.
Looking for the ultimate guide on mastering Apache Kafka in 2024? The ultimate hands-on learning guide with secrets on how you can learn Kafka by doing. Discover the key resources to help you master the art of real-time data streaming and building robust data pipelines with Apache Kafka. How Difficult Is It To Learn Kafka?
The volume of data generated in real time from application databases, sensors, and mobile devices continues to grow exponentially. As part of this, we are also supporting Snowpipe Streaming as an ingestion method for our Snowflake Connector for Kafka. How does Snowpipe Streaming work?
Change Data Capture (CDC) is a crucial technology that enables organizations to efficiently track and capture changes in their databases. In this blog post, we’ll explore what CDC is, why it’s important, and our journey of implementing Generic CDC solutions for all online databases at Pinterest. What is Change Data Capture?
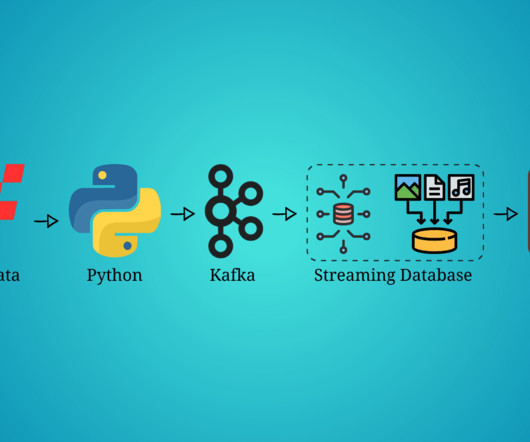
Build a streaming data pipeline using Formula 1 data, Python, Kafka, RisingWave as the streaming database, and visualize all the real-time data in Grafana.
Explore the full potential of AWS Kafka with this ultimate guide. Elevate your data processing skills with Amazon Managed Streaming for Apache Kafka, making real-time data streaming a breeze. According to IDC , the worldwide streaming market for event-streaming software, such as Kafka, is likely to reach $5.3
Explore the world of data analytics with the top AWS databases! Check out this blog to discover your ideal database and uncover the power of scalable and efficient solutions for all your data analytical requirements. Let’s understand more about AWS Databases in the following section.
Unify transactional and analytical workloads in Snowflake for greater simplicity Many businesses must maintain two separate databases: one to handle transactional workloads and another for analytical workloads.
At DoorDash, we rely on message queue systems based on Kafka to handle billions of real-time events. We will delve here into how we set up multi-tenancy with a messaging queue system based on Kafka. While we have achieved this in databases, it also needs to be extended to other infrastructure components.
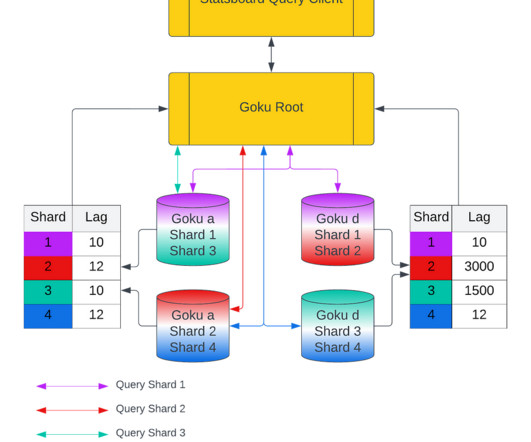
Goku is our in-house time series database providing cost efficient and low latency storage for metrics data. From these kafka topics, an ingestion service would consume the data points and push them into the GokuS cluster(s) with a retry mechanism (via a separate kafka + small ingestion service) to handle failure.
NoSQL databases are the new-age solutions to distributed unstructured data storage and processing. The speed, scalability, and fail-over safety offered by NoSQL databases are needed in the current times in the wake of Big Data Analytics and Data Science technologies. The databases are run on a single instance of 2VCPUs and 8GP memory.
How to use Kafka Streams to aggregate change data capture (CDC) messages from a relational database into transactional messages, powering a scalable microservices architecture.
Change Data Capture (CDC) is an excellent way to introduce streaming analytics into your existing database, and using Debezium enables you to send your change data through Apache Kafka®. Although […].
link] Gunnar Morling: What If We Could Rebuild Kafka From Scratch? KIP-1150 ("Diskless Kafka") is one of my most anticipated releases from Apache Kafka. The blog is an excellent compilation of types of query engines on top of the lakehouse, its internal architecture, and benchmarking against various categories.
Although the Faust library aims to bring Kafka Streaming ideas into the Python ecosystem, it may pose challenges in terms of ease of use. Traditional databases are ill-suited for storing events in high throughput event streams. This document serves as a tutorial and offers best practices for effectively utilizing Faust.
What is stopping you from using Kafka Streams as your data layer for building applications? After all, it comes with fast, embedded RocksDB storage, takes care of redundancy for you, […].
In 2024, the data engineering job market is flourishing, with roles like database administrators and architects projected to grow by 8% and salaries averaging $153,000 annually in the US (as per Glassdoor ). Use Kafka for real-time data ingestion, preprocess with Apache Spark, and store data in Snowflake.
DoorDash’s Engineering teams revamped Kafka Topic creation by replacing a Terraform/Atlantis based approach with an in-house API, Infra Service. DoorDash’s Real-Time Streaming Platform, or RTSP, team is under the Data Platform organization and manages over 2,500 Kafka Topics across five clusters.
Spark Streaming Vs Kafka Stream Now that we have understood high level what these tools mean, it’s obvious to have curiosity around differences between both the tools. Spark Streaming Kafka Streams 1 Data received from live input data streams is Divided into Micro-batched for processing. 6 Spark streaming is a standalone framework.
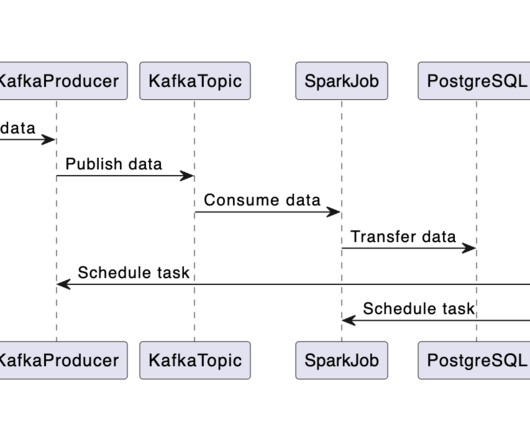
This involves getting data from an API and storing it in a PostgreSQL database. In the second phase, we’ll develop an application that uses a language model to interact with this database. The second article, which will come later, will delve into creating agents using tools like LangChain to communicate with external databases.
Based on a report, Apache Kafka stores and streams more than 7 trillion real-time messages per day. To eradicate such complexities, you can use database connecting tools like Debezium and Kafka […]
Data ingestion systems such as Kafka , for example, offer a seamless and quick data ingestion process while also allowing data engineers to locate appropriate data sources, analyze them, and ingest data for further processing. Database tools/frameworks like SQL, NoSQL , etc.,
Kafka can continue the list of brand names that became generic terms for the entire type of technology. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. What is Kafka?
It is the process of consuming data from multiple sources and transferring it into a destination database or data warehouse where you can perform data transformations and analytics. Prepare for Your Next Big Data Job Interview with Kafka Interview Questions and Answers Types of Data Ingestion 1.
Kafka and Vector Database support According to Databricks’ State of Data and AI report , the number of companies using SaaS LLM APIs has grown more than 1300% since November 2022 with a nearly 411% increase in the number of AI models put into production during that same period.
Cloudera Operational Database is now available in three different form-factors in Cloudera Data Platform (CDP). . If you are new to Cloudera Operational Database, see this blog post. In this blog post, we’ll look at both Apache HBase and Apache Phoenix concepts relevant to developing applications for Cloudera Operational Database.
Data pipelines streamline the movement and transformation of data from various sources to a destination, typically a database or data warehouse. Choose a tool that integrates with existing data sources, storage systems, and analytics platforms, supporting popular databases and formats. How Do Data Pipelines Work?
Summary The Cassandra database is one of the first open source options for globally scalable storage systems. The community recently released a new major version that marks a milestone in its maturity and stability as a project and database. Since its introduction in 2008 it has been powering systems at every scale.
Postgres creator launches DBOS, a transactional serverless computing platform — Mike sees DBOS like a cloud-native OS that runs on-top of the database in order to rethink application development and deployment. Unlocking Kafka's potential: tackling tail latency with eBPF.
TigerGraph is a leading database that offers a highly scalable and performant native graph engine for powering graph analytics and machine learning. How has the ecosystem of graph databases changed in usage and design in recent years? Start trusting your data with Monte Carlo today! Visit [link] to learn more.
For machine learning applications relational models require additional processing to be directly useful, which is why there has been a growth in the use of vector databases. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services.
Some departments used IBM Db2, while others relied on VSAM files or IMS databases creating complex data governance processes and costly data pipeline maintenance. With near real-time data synchronization, the solution ensures that databases stay in sync for reporting, analytics, and data warehousing.
The post IBM Technology Chooses Cloudera as its Preferred Partner for Addressing Real Time Data Movement Using Kafka appeared first on Cloudera Blog. Learn more about how you can benefit from a well-supported data management platform and ecosystem of products, services and support by visiting the IBM and Cloudera partnership page.
Gartner® recognized Cloudera in three recent reports – Magic Quadrant for Cloud Database Management Systems (DBMS), Critical Capabilities for Cloud Database Management Systems for Analytical Use Cases and Critical Capabilities for Cloud Database Management Systems for Operational Use Cases. Get started with CDP.
I’ve always been vocal about ksqlDB’s and Kafka Stream’s limitations. The Future of ksqlDB and Kafka Streams With this announcement, the future of primarily ksqlDB and, to a lesser extent, Kafka Streams comes into view. Since Kafka Streams is part of the Apache project, I don’t see it going away as quickly.
The customer also wanted to utilize the new features in CDP PvC Base like Apache Ranger for dynamic policies, Apache Atlas for lineage, comprehensive Kafka streaming services and Hive 3 features that are not available in legacy CDH versions. Support Kafka connectivity to HDFS, AWS S3 and Kafka Streams. Kafka, SRM, SMM.
ksqlDB, the event streaming database, is becoming one of the most popular ways to work with Apache Kafka®. Every day, we answer many questions about the project, but here’s a […].
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content