This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It addresses many of Kafka's challenges in analytical infrastructure. The combination of Kafka and Flink is not a perfect fit for real-time analytics; the integration of Kafka and Lakehouse is very shallow. How do you compare Fluss with Apache Kafka? Fluss and Kafka differ fundamentally in design principles.
What used to be entirely managed by the database engine is now a composition of multiple systems that need to be properly configured to work in concert. What used to be entirely managed by the database engine is now a composition of multiple systems that need to be properly configured to work in concert.
With real time alerts for problems in your databases, ETL pipelines, or data warehouse, and integrations with Slack, Pagerduty, and custom webhooks you can fix the errors before they become a problem. How have projects such as Kafka and Pulsar impacted the broader software and data landscape? When is Pulsar the wrong choice?
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Just connect it to your database/data warehouse/data lakehouse/whatever you’re using and let them do the rest.
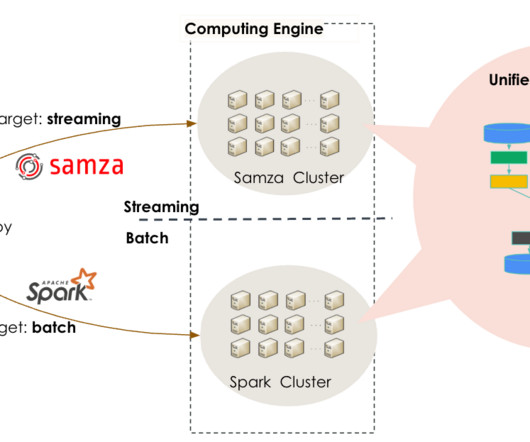
In 2010, they introduced Apache Kafka , a pivotal Big Data ingestion backbone for LinkedIn’s real-time infrastructure. To transition from batch-oriented processing and respond to Kafka events within minutes or seconds, they built an in-house distributed event streaming framework, Apache Samza.
In the past, we often used lambdaarchitecture for processing jobs, meaning that our developers used two different systems for batch and stream processing. This pipeline reads ProfileData; joins the data with sideTable and then applies a user defined function called Standardizer(); finally, writes the standardized result to databases.
So they needed a data warehouse that could keep up with the scale of modern big data systems , but provide the semantics and query performance of a traditional relational database. Data streamed in is queryable in conjunction with historical data, avoiding need for LambdaArchitecture. They chose to build their RTDW on Cloudera.
Lambdaarchitecture: A combination of both batch and real-time processing, the lambdaarchitecture has three layers. The lambdaarchitecture ensures completeness of data with minimal latency. Streaming data to Elasticsearch server from different databases. It is useful for Big Data ingestion.
Architectural patterns like LambdaArchitecture and Kappa Architecture emerged to bridge the gap between real-time and batch data processing. Each architectural pattern has its limitation. link] Grab: Zero traffic cost for Kafka consumers. This opens the door to a more cost-efficient design.
a new transaction, an updated stock price, a power outage alert) to the destination data cloud without disrupting the database workload. Also worth noting is lambdaarchitecture-based data ingestion which is a hybrid model that combines features of both streaming and batch data ingestion.
This architecture shows that simulated sensor data is ingested from MQTT to Kafka. The data in Kafka is analyzed with Spark Streaming API, and the data is stored in a column store called HBase. Learn how to use various big data tools like Kafka, Zookeeper, Spark, HBase, and Hadoop for real-time data aggregation.
It is also friendly for database developers as it provides Spark SQL which supports most of the ANSI SQL functionality. Spark streaming also has in-built connectors for Apache Kafka which comes very handy while developing Streaming applications. Spark streaming also supports Structure Streaming.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content