This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
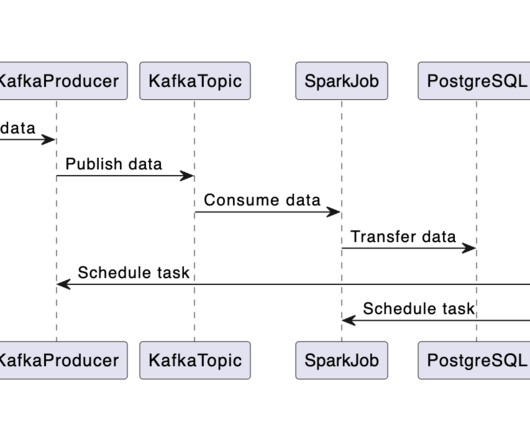
This involves getting data from an API and storing it in a PostgreSQLdatabase. In the second phase, we’ll develop an application that uses a language model to interact with this database. The second article, which will come later, will delve into creating agents using tools like LangChain to communicate with external databases.
The ksqlDB project was created to address this state of affairs by building a unified layer on top of the Kafka ecosystem for stream processing. Developers can work with the SQL constructs that they are familiar with while automatically getting the durability and reliability that Kafka offers. How is ksqlDB architected?
How has the market for timeseries databases changed since we last spoke? How have the improvements and new features in the recent releases of PostgreSQL impacted the Timescale product? How has the market for timeseries databases changed since we last spoke? Can you refresh our memory about what TimescaleDB is?
Summary Databases are useful for inspecting the current state of your application, but inspecting the history of that data can get messy without a way to track changes as they happen. How has the tight coupling with Kafka impacted the direction and capabilities of Debezium? What, if any, other substrates does Debezium support (e.g.
However, not all databases can be in the […]. Building a Cloud ETL Pipeline on Confluent Cloud shows you how to build and deploy a data pipeline entirely in the cloud.
We’ll also take a look at some performance tests to see if Rust might be a viable alternative for Java applications using Apache Kafka ®. In this case, that means a command is created for a particular action, which will be assigned to a Kafka topic specific for that action. On May 15, 2015, the Core Kafka team released version 1.0
One of the most common integrations that people want to do with Apache Kafka ® is getting data in from a database. That is because relational databases are a rich source of events. The existing data in a database, and any changes to that data, can be streamed into a Kafka topic. Setting the Kafka message key.
Following part 1 and part 2 of the Spring for Apache Kafka Deep Dive blog series, here in part 3 we will discuss another project from the Spring team: Spring Cloud Data Flow , which focuses on enabling developers to easily develop, deploy, and orchestrate event streaming pipelines based on Apache Kafka ®.
Learn more about Datafold by visiting dataengineeringpodcast.com/datafold You shouldn't have to throw away the database to build with fast-changing data. It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. With Materialize, you can! With Materialize, you can!
For machine learning applications relational models require additional processing to be directly useful, which is why there has been a growth in the use of vector databases. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services.
Snowflake is launching native integrations with some of the most popular databases, including PostgreSQL and MySQL. With other ingestion improvements and our new database connectors, we are smoothing out the data ingestion process, making it radically simple and efficient to bring data to Snowflake. In case of errors (e.g.,
For transactional databases, it’s mostly the Microsoft SQL Server, but also other databases like PostgreSQL, ScyllaDB and Couchbase. queries per second as total load, spread across its managed database-as-a-service (DBAAS.) It uses Spark for the data platform. At peak load, Agoda sees around 7.5M
The landscape of time series databases is extensive and oftentimes difficult to navigate. release of PostGreSQL had on the design of the project? Which came first, Timescale the business or Timescale the database, and what is your strategy for ensuring that the open source project and the company around it both maintain their health?
Writing to a database and sending messages to a message bus is not atomic, which means that if one of these operations fails, the state of the application can become inconsistent. It uses a Postgres database as a local storage, and Spring Data to handle persistence. The service and the database run in docker containers.
Using this data, Apache Kafka ® and Confluent Platform can provide the foundations for both event-driven applications as well as an analytical platform. With tools like KSQL and Kafka Connect, the concept of streaming ETL is made accessible to a much wider audience of developers and data engineers. Ingesting the data.
Cloudera Stream Processing (CSP), powered by Apache Flink and Apache Kafka, provides a complete stream management and stateful processing solution. In CSP, Kafka serves as the storage streaming substrate, and Flink as the core in-stream processing engine that supports SQL and REST interfaces. Apache Kafka and SMM.
As the databases professor at my university used to say, it depends. Using SQL to run your search might be enough for your use case, but as your project requirements grow and more advanced features are needed—for example, enabling synonyms, multilingual search, or even machine learning—your relational database might not be enough.
Summary One of the most complex aspects of managing data for analytical workloads is moving it from a transactional database into the data warehouse. MemSQL is a distributed database built to support concurrent use by transactional, application oriented, and analytical, high volume, workloads on the same hardware.
Andreas Andreakis , Ioannis Papapanagiotou Overview Change-Data-Capture (CDC) allows capturing committed changes from a database in real-time and propagating those changes to downstream consumers [1][2]. In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events. Triggering repairs at any time.
Change Data Capture (CDC) with PostgreSQL and ClickHouse — This is a nice vendor post about CDC with Kafka as movement layer (using Debezium). From databases introduction to SQL writing. — Marie wrote best practices for establishing complete and reliable data documentation. This is neat. but I missed it).
How would you characterize Yellowbrick’s position in the database/DWH market? How would you characterize Yellowbrick’s position in the database/DWH market? Can you start by describing what Yellowbrick is and some of the story behind it? How is Yellowbrick architected? How is Yellowbrick architected?
Andreas Andreakis , Ioannis Papapanagiotou Overview Change-Data-Capture (CDC) allows capturing committed changes from a database in real-time and propagating those changes to downstream consumers [1][2]. In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events. Triggering repairs at any time.
You listen to this show to learn and stay up to date with what’s happening in databases, streaming platforms, big data, and everything else you need to know about modern data management. Go to dataengineeringpodcast.com/linode today to get a $20 credit and launch a new server in under a minute.
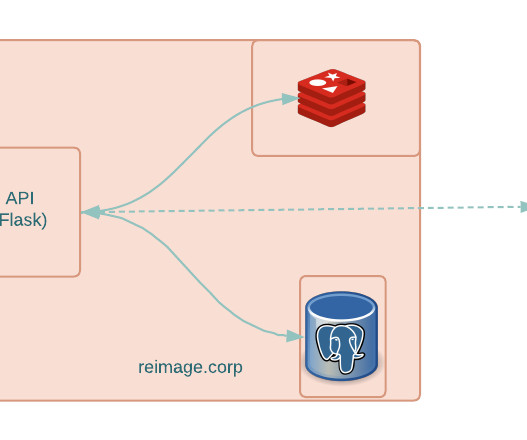
For MaaS, the starting point was co-hosting the web service, relational database ( Postgres ), and Redis -based caching layer on a server. In the extant deployment model, multiple API workers functioned in tandem without sharing common memory or database connectors. We decided to leverage Kafka as a distributed messaging queue.
You listen to this show to learn and stay up to date with what’s happening in databases, streaming platforms, big data, and everything else you need to know about modern data management. Which database engines do you support and how do you reduce the maintenance burden for supporting different dialects and capabilities?
You listen to this show to learn and stay up to date with what’s happening in databases, streaming platforms, big data, and everything else you need to know about modern data management. What are the benefits of using PostgreSQL as the system of record for Marquez? How is the metadata itself stored and managed in Marquez?
Relational databases today are widely known to be suboptimal for supporting high-scale analytical use cases, and are all but certain to run into issues as your production data size and query volume grow.
An MV is a special type of sink that allows us to output data from our query into a tabular format persisted in a PostgreSQLdatabase. Primary key Every MV requires a primary key, as this will be our primary key in the underlying relational database as well. Why use a materialized view? It is set to five minutes by default.
We started with PostgreSQL, laying the foundation for structured analytics early on. At the same time, demand for data surged, but our database technology lacked the ability to efficiently isolate workloads, creating performance bottlenecks as more teams relied on the system for insights.
Breaking Bad… Data Silos We haven’t quite figured out how to avoid using relational databases. Folks have definitely tried, and while Apache Kafka® has become the standard for event-driven architectures, it still struggles to replace your everyday PostgreSQLdatabase instance in the modern application stack.
Initially, we built a quick prototype of the data services - primitive CRUD-type services, with synchronous HTTP APIs, each interacting directly with a simple (dedicated) PostgreSQLdatabase as the operational store for the data. Outbound events were generated after completion of DB updates.
Introduction Managing streaming data from a source system, like PostgreSQL, MongoDB or DynamoDB, into a downstream system for real-time analytics is a challenge for many teams. Rockset, on the other hand, is a cloud-native database, removing a lot of the tooling and overhead required to get data into the system.
Open Source Support: Many Azure services support popular open-source frameworks like Apache Spark, Kafka, and Hadoop, providing flexibility for data engineering tasks. Microsoft Azure SQL Database The SQL database is Microsoft's premier database offering.
Extraction ChatGPT ETL prompts can be used to help write scripts to extract data from different sources, including: Databases I have a SQL database with a table named employees. Filtering In my SQL database, I have a table named orders with columns order_id, customer_name, order_date, and total_amount.
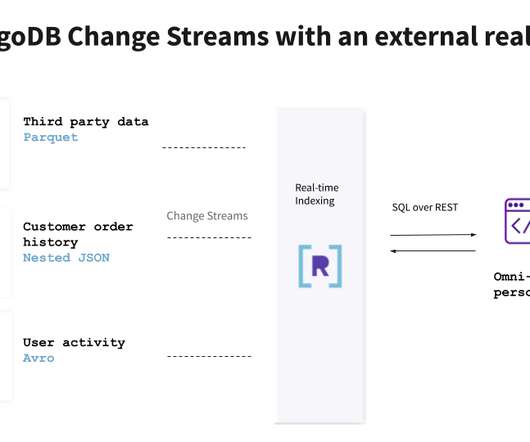
Applications of today often operate on data from multiple sources—databases like MongoDB, streaming platforms, and data lakes. An omni-channel retail personalization application, as an example, may require order data from MongoDB, user activity streams from Kafka, and third-party data from a data lake.
For example, if you want to analyze yesterday’s sales you can — at least in principle — simply query your operational database. Article as well as order data is horizontally sharded over eight PostgreSQLdatabases, so there is no way to simply fire up some ad hoc SQL to do a quick analysis.
Added support for standalone NiFi/Kafka clusters. Operational Database. Support for complex x-row/x-table distributed transactions that runs TPC-C benchmarks alongside support for ANSI SQL makes it easy to migrate from MySQL databases to Operational Database. Operational Database – Apache Phoenix 5.1.
Kafka 3.0.0 – The Apache Software Foundation needed less than one month to go from Kafka version 3.0.0-rc0 Druid 0.22.0 – Apache Druid is claimed to be a high-performance analytical database competing with ClickHouse. And of course, PostgreSQL is one of the most popular databases. rc0 to the release of 3.0.0.
Kafka 3.0.0 – The Apache Software Foundation needed less than one month to go from Kafka version 3.0.0-rc0 Druid 0.22.0 – Apache Druid is claimed to be a high-performance analytical database competing with ClickHouse. And of course, PostgreSQL is one of the most popular databases. rc0 to the release of 3.0.0.
This language is used to interact with databases and perform data manipulations and querying. It offers an interactive and user-friendly interface for creating dashboards, reports, and charts from a variety of data sources such as spreadsheets, databases, and cloud-based sources. SQL is also an essential skill for Azure Data Engineers.
PostgreSQL 10, 11 and 12 and OracleDB 12c, 19c and 19.9. Add Kafka Service – Required for Atlas if it’s not already installed. Backup Cluster Metadata and Databases for CM, Hive and Oozie. Step 4b: Upgrading the RDBMS. CDP supports MariaDB 10.2-10.4, Step 5: Upgrading Cloudera Manager. Add Atlas Service. Run Upgrade.
Apache Kafka has made acquiring real-time data more mainstream, but only a small sliver are turning batch analytics, run nightly, into real-time analytical dashboards with alerts and automatic anomaly detection. Rockset is a real-time analytics database in the cloud that uses an indexing approach to deliver low-latency analytics at scale.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content