This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
What used to be entirely managed by the database engine is now a composition of multiple systems that need to be properly configured to work in concert. What used to be entirely managed by the database engine is now a composition of multiple systems that need to be properly configured to work in concert.
Instead of Kafka's topics, Fluss organizes data into database tables with partitions and buckets. Tableflow is a LambdaArchitecture that uses two separate systems (streaming and batch), leading to challenges like data inconsistency, dual storage costs, and complex governance. The second difference is the Storage Model.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Just connect it to your database/data warehouse/data lakehouse/whatever you’re using and let them do the rest.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs.
With real time alerts for problems in your databases, ETL pipelines, or data warehouse, and integrations with Slack, Pagerduty, and custom webhooks you can fix the errors before they become a problem. You monitor your website to make sure that you’re the first to know when something goes wrong, but what about your data?
LinkedIn team decided to migrate to a lambdaarchitecture and got 94% uplift in performance. I don't have a lot to say except the fact that we are going in a future with a lot of databases choices. How fast is DuckDB really? — Georges, Fivetran CEO, ran a performance test to have metrics on DuckDB performance.
Whereas bounded data refers to data that can be defined by clear start and end boundaries, e.g., daily data export from the operation database. Here is an illustration to provide you with a similar idea between the trigger and the semantics in LambdaArchitecture Image created by the author.
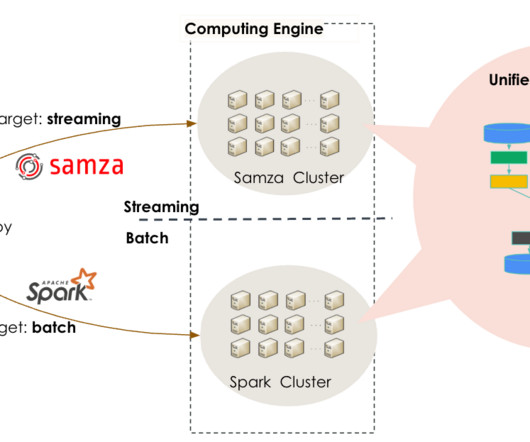
In the past, we often used lambdaarchitecture for processing jobs, meaning that our developers used two different systems for batch and stream processing. This pipeline reads ProfileData; joins the data with sideTable and then applies a user defined function called Standardizer(); finally, writes the standardized result to databases.
You listen to this show to learn and stay up to date with what’s happening in databases, streaming platforms, big data, and everything else you need to know about modern data management. The Lambdaarchitecture was popular in the early days of Hadoop but seems to have fallen out of favor.
This framework, along with Apache Spark for batch processing, formed the basis of LinkedIn’s lambdaarchitecture for data processing jobs. The lambdaarchitecture approach led to operational complexity and inefficiencies, because it required maintaining two different codebases and two different engines for batch and streaming data.
He was an engineer on the database team at Facebook, where he was the founding engineer of the RocksDB data store. Earlier at Yahoo, he was one of the founding engineers of the Hadoop Distributed File System.
Lambdaarchitecture: A combination of both batch and real-time processing, the lambdaarchitecture has three layers. The lambdaarchitecture ensures completeness of data with minimal latency. Streaming data to Elasticsearch server from different databases. How Data Ingestion Helps Businesses?
Databases could just buffer, ingest and query data on a regular schedule. Finally, you could always plan ahead for bursty traffic and overprovision your database clusters and pipelines. Many databases claim to deliver scalability on demand so that you can avoid expensive overprovisioning and keep your data-driven operations humming.
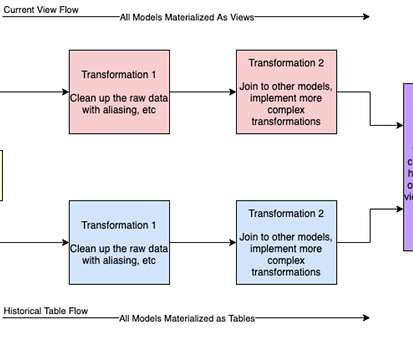
So they needed a data warehouse that could keep up with the scale of modern big data systems , but provide the semantics and query performance of a traditional relational database. Data streamed in is queryable in conjunction with historical data, avoiding need for LambdaArchitecture. They chose to build their RTDW on Cloudera.
You don’t want to hit your production database unless you want to frighten and likely anger your DBA. Lambda views are a simple and readily available solution that is tool agnostic and SQL based. What are lambda views? The idea of lambda views comes from lambdaarchitecture.
Now, you might ask, “How is this different from data stack architecture, or data architecture?” ” Data Stack Architecture : Your data stack architecture defines the technology and tools used to handle data, like databases, data processing platforms, analytic tools, and programming languages.
a new transaction, an updated stock price, a power outage alert) to the destination data cloud without disrupting the database workload. Also worth noting is lambdaarchitecture-based data ingestion which is a hybrid model that combines features of both streaming and batch data ingestion.
Architectural patterns like LambdaArchitecture and Kappa Architecture emerged to bridge the gap between real-time and batch data processing. Each architectural pattern has its limitation.
It is also friendly for database developers as it provides Spark SQL which supports most of the ANSI SQL functionality. It can solve problems related to batch processing, near real-time processing, can be used to apply lambdaarchitecture, can be used for Structured streaming.
This data engineering project uses the following big data stack - Azure Structured Query Language (SQL) Database instance for persistent storage; to store forecasts and historical distribution data. The current architecture is called Lambdaarchitecture, where you can handle both real-time streaming data and batch data.
This project is a LambdaArchitecture program that tracks Chicago's streets' traffic conditions, including congestion and safety. For obtaining data from various Hadoop-integrated databases and file systems, Hive has a SQL-like interface. Simulating real-time traffic has successfully been modeled.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content