This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The current database includes 2,000 server types in 130 regions and 340 zones. Storing data: data collected is stored to allow for historical comparisons. Results are stored in git and their database, together with benchmarking metadata. Visualizing the data: the frontend that allows querying of live and historic data.
Introduction Meet Tajinder, a seasoned Senior Data Scientist and ML Engineer who has excelled in the rapidly evolving field of data science. Tajinder’s passion for unraveling hidden patterns in complex datasets has driven impactful outcomes, transforming rawdata into actionable intelligence.
It sounds great, but how do you prove the data is correct at each layer? How do you ensure data quality in every layer ? Bronze, Silver, and Gold – The Data Architecture Olympics? The Bronze layer is the initial landing zone for all incoming rawdata, capturing it in its unprocessed, original form.
In the ELT, the load is done before the transform part without any alteration of the data leaving the rawdata ready to be transformed in the data warehouse. In a simple words dbt sits on top of your rawdata to organise all your SQL queries that are defining your data assets.
The demand for higher data velocity, faster access and analysis of data as its created and modified without waiting for slow, time-consuming bulk movement, became critical to business agility. Which turned into data lakes and data lakehouses Poor data quality turned Hadoop into a data swamp, and what sounds better than a data swamp?
However, Strobelight has several safeguards in place to prevent users from causing performance degradation for the targeted workloads and retention issues for the databases Strobelight writes to. Strobelight also delays symbolization until after profiling and stores rawdata to disk to prevent memory thrash on the host.
Introduction Meet Tajinder, a seasoned Senior Data Scientist and ML Engineer who has excelled in the rapidly evolving field of data science. Tajinder’s passion for unraveling hidden patterns in complex datasets has driven impactful outcomes, transforming rawdata into actionable intelligence.
Setting the Stage: We need E&L practices, because “copying rawdata” is more complex than it sounds. For instance, how would you know which orders got “canceled”, an operation that usually takes place in the same data record and just “modifies” it in place. But not at the ingestion level.
What is Data Transformation? Data transformation is the process of converting rawdata into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis.
Agoda co-locates in all data centers, leasing space for its racks and the largest data center consumes about 1 MW of power. It uses Spark for the data platform. For transactional databases, it’s mostly the Microsoft SQL Server, but also other databases like PostgreSQL, ScyllaDB and Couchbase.
Deliver multimodal analytics with familiar SQL syntax Database queries are the underlying force that runs the insights across organizations and powers data-driven experiences for users. Traditionally, SQL has been limited to structured data neatly organized in tables.
Then you begin researching database objects and find a couple of views, but there are some inconsistencies between them so you do not know which one to use. As you do not want to start your development with uncertainty, you decide to go for the operational rawdata directly. Does it sound familiar?
While business rules evolve constantly, and while corrections and adjustments to the process are more the rule than the exception, it’s important to insulate compute logic changes from data changes and have control over all of the moving parts. Results may vary depending on how smart your database optimizer is.
Hum’s fast data store is built on Elasticsearch. Snowflake’s relational database, especially when paired with Snowpark , enables much quicker use of data for ML model training and testing. Snowflake makes it easy and cheap for them to pull in their data.
One of the complexities of real-life business questions is that the information required to do the analysis or calculation doesnt always exist as a simple database column. This requires multiple layers of computational intelligence to transform rawdata into meaningful business insights which no other tool on the market can do.
We work with organizations around the globe that have diverse needs but can only achieve their objectives with expertly curated data sets containing thousands of different attributes. We assign a PreciselyID to every address in our database, linking each location to our portfolio’s vast array of data.
When created, Snowflake materializes query results into a persistent table structure that refreshes whenever underlying data changes. These tables provide a centralized location to host both your rawdata and transformed datasets optimized for AI-powered analytics with ThoughtSpot. Hit ‘Continue’.
Rockset is the real-time analytics database in the cloud for modern data teams. Get faster analytics on fresher data, at lower costs, by exploiting indexing over brute-force scanning. In many tech circles, SQL databases remain synonymous with old-school on-premises databases like Oracle or DB2.
Data validation performs a check against existing values in a database to ensure that they fall within valid parameters. Data enrichment is the process of enhancing your data by appending relevant context from additional sources – improving its overall value, accuracy, and usability.
The goal of dimensional modeling is to take rawdata and transform it into Fact and Dimension tables that represent the business. Part 1: Setup dbt project and database Step 1: Install project dependencies Before you can get started: You must have either DuckDB or PostgreSQL installed.
The value of the edge lies in acting at the edge where it has the greatest impact with zero latency before it sends the most valuable data to the cloud for further high-performance processing. Data Collection Using Cloudera Data Platform. STEP 1: Collecting the rawdata. Conclusion.
Native CDC for Postgres and MySQL — Snowflake will be able to connect to Postgres and MySQL to natively move data from your databases to the warehouse. This enables easier data management and query operations, making it possible to perform SQL-like operations and transactions directly on data files.
Extract and Load This phase includes VDK jobs calling the Europeana REST API to extract rawdata. You have just learned how to implement batch data processing in VDK! It only requires ingesting rawdata, manipulating it, and, finally, using it for your purposes! link] Summary Congratulations!
Data Engineering at Adyen — "Data engineers at Adyen are responsible for creating high-quality, scalable, reusable and insightful datasets out of large volumes of rawdata" This is a good definition of one of the possible responsibilities of DE. It's a technique to work with anonymised data.
Collecting, cleaning, and organizing data into a coherent form for business users to consume are all standard data modeling and data engineering tasks for loading a data warehouse. Based on Tecton blog So is this similar to data engineering pipelines into a data lake/warehouse?
ByteGraph: A Graph Database for TikTok — ByteGraph is the open-source graph database developed by the company behind TikTok. Seek AI promise is a prompt where you ask your data anything and the AI responds on top of the rawdata directly. This article shows you what are the key concepts to understand it.
And even when we manage to streamline the data workflow, those insights aren’t always accessible to users unfamiliar with antiquated business intelligence tools. That’s why ThoughtSpot and Fivetran are joining forces to decrease the amount of time, steps, and effort required to go from rawdata to AI-powered insights.
In modern databases, this issue of querying and searching is also very pertinent. Indexing often makes looking up data faster than filtering, and you can create indices based on a column of interest. Some of these limitations are due to the way spatial indexing stores the leaves in the data.
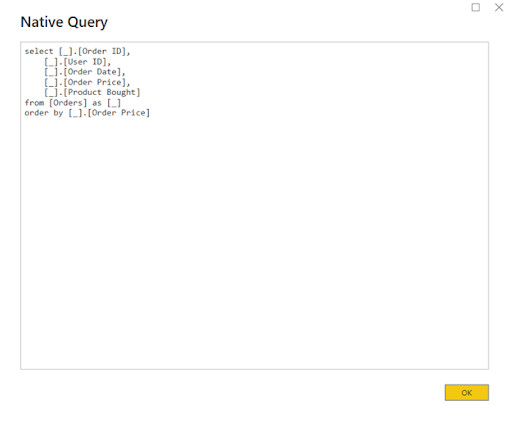
Understanding Query Folding in Power BI Query Folding may be considered as having your instructions written in structured query language form; whereafter, it is handed over to the base of the database to be put into practice. For this demonstration, I will incorporate the usage of Microsoft Access Database. Contents, Folder.
Microsoft offers a leading solution for business intelligence (BI) and data visualization through this platform. It empowers users to build dynamic dashboards and reports, transforming rawdata into actionable insights. This allows seamless data movement and end-to-end workflows within the same environment.
Read our eBook Validation and Enrichment: Harnessing Insights from RawData In this ebook, we delve into the crucial data validation and enrichment process, uncovering the challenges organizations face and presenting solutions to simplify and enhance these processes.
You work hard to make sure that your data is clean, reliable, and reproducible throughout the ingestion pipeline, but what happens when it gets to the data warehouse? Dataform picks up where your ETL jobs leave off, turning rawdata into reliable analytics. How is the metadata itself stored and managed in Marquez?
Summary The most complicated part of data engineering is the effort involved in making the rawdata fit into the narrative of the business. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services.
Last week, Rockset hosted a conversation with a few seasoned data architects and data practitioners steeped in NoSQL databases to talk about the current state of NoSQL in 2022 and how data teams should think about it. Rick Houlihan Developers want more than just a database. Much was discussed.
For more information, check out the best Data Science certification. A data scientist’s job description focuses on the following – Automating the collection process and identifying the valuable data. Report data findings to management Monitor data collection. Look out for upgrades on analytical techniques.
Data centers and warehouses typically operate cloud computing systems of databases and software. The recommended coursework must include courses in web development, web design, programming, networking, database management, and mathematics, as well as other courses. What is Cloud Computing? Salary range: $49K - $100K 5.
Data Analysts’ responsibility is to analyze data using statistical techniques, implement databases, gather primary and secondary sources of data, and identify, analyze, and interpret trends. How to track changes in databases? Taking data from sources and storing or processing it is known as data extraction.
Businesses benefit at large with these data collection and analysis as they allow organizations to make predictions and give insights about products so that they can make informed decisions, backed by inferences from existing data, which, in turn, helps in huge profit returns to such businesses. What is the role of a Data Engineer?
Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making. These data sources serve as the starting point for the pipeline, providing the rawdata that will be ingested, processed, and analyzed.
Features: Networking and Content Delivery Security, Identity, and Compliance Management Cloud storage and databases Integrated AWS services such as Amazon AppFlow, Augmented AI, AppStream 2.0, Cloudyn Cloudyn gives a detailed overview of its databases, computing prowess, and data storage capabilities. and more 2.
Without proper data quality testing, duplicate data can wreak all kinds of havoc—from spamming leads and degrading personalization programs to needlessly driving up database costs and causing reputational damage (for instance, duplicate social security numbers or other user IDs).
The greatest data processing challenge of 2024 is the lack of qualified data scientists with the skill set and expertise to handle this gigantic volume of data. Inability to process large volumes of data Out of the 2.5 quintillion data produced, only 60 percent workers spend days on it to make sense of it.
Get more out of your data: Top use cases for Snowflake Notebooks To see what’s possible and change how you interact with Snowflake data, check out the various use cases you can achieve in a single interface: Integrated data analysis: Manage your entire data workflow within a single, intuitive environment.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content