This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a data warehouse The data warehouse (DW) was an approach to data architecture and structureddata management that really hit its stride in the early 1990s.
Data storage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structureddata and transactional workloads but struggled with performance at scale as data volumes grew.
Consider the hoops we have to jump through when working with semi-structureddata, like JSON, in relationaldatabases such as PostgreSQL and MySQL. JSON is a good match for document databases, such as MongoDB. JSON is a good match for document databases, such as MongoDB.
data access semantics that guarantee repeatable data read behavior for client applications. System Requirements Support for StructuredData The growth of NoSQL databases has broadly been accompanied with the trend of data “schemalessness” (e.g., This is described more in-depth later in this article.
For data storage, the database is one of the fundamental building blocks. There are many kinds of databases available, each with its strengths and weaknesses. In this article, we’ll look at what are the different types of databases and which is the most common. What are the Different Types of Database Architectures?
In this digital age, data is king, and how we manage, analyze, and harness its power is constantly evolving. Database management, once confined to IT departments, has become a strategic cornerstone for businesses across industries. In this blog, we will talk about the future of database management.
But in order to justify why this concept came into existence, I thought it’d be great to look back in time and understand the evolution of the data landscape. Evolution of the data landscape 1980s — Inception Relationaldatabases came into existence. Organizations began to use relationaldatabases for ‘everything’.
Think of a database as a smart, organized library that stores and manages information efficiently. On the other hand, datastructures are like the tools that help organize and arrange data within a computer program. What is a Database? A vital component of our lives is the database.
Introduction Data Engineer is responsible for managing the flow of data to be used to make better business decisions. A solid understanding of relationaldatabases and SQL language is a must-have skill, as an ability to manipulate large amounts of data effectively. What is AWS Kinesis?
Summary Data warehouses have gone through many transformations, from standard relationaldatabases on powerful hardware, to column oriented storage engines, to the current generation of cloud-native analytical engines. Go to dataengineeringpodcast.com/linode today to get a $20 credit and launch a new server in under a minute.
MapReduce performs batch processing only and doesn’t fit time-sensitive data or real-time analytics jobs. Data engineers who previously worked only with relationaldatabase management systems and SQL queries need training to take advantage of Hadoop. Data storage options. Data management and monitoring options.
Rockset is the real-time analytics database in the cloud for modern data teams. Get faster analytics on fresher data, at lower costs, by exploiting indexing over brute-force scanning. In many tech circles, SQL databases remain synonymous with old-school on-premises databases like Oracle or DB2.
Learning inferential statistics website: wallstreetmojo.com, kdnuggets.com Learning Hypothesis testing website: stattrek.com Start learning database design and SQL. A database is a structureddata collection that is stored and accessed electronically. Considering this information database model is fitted with data.
When it comes to managing data, a database management system (DBMS) is a vital tool. Database management systems (DBMS) use entities to represent and manage data. In a DBMS, entities are usually organized into tables, which allow for more efficient storage and retrieval of data. But what is an entity?
The ingestion layer supports multiple data types and formats, including: Batch Data: Data collected and processed in discrete chunks, typically from static sources such as databases or logs. This method is advantageous when dealing with structureddata that requires pre-processing before storage.
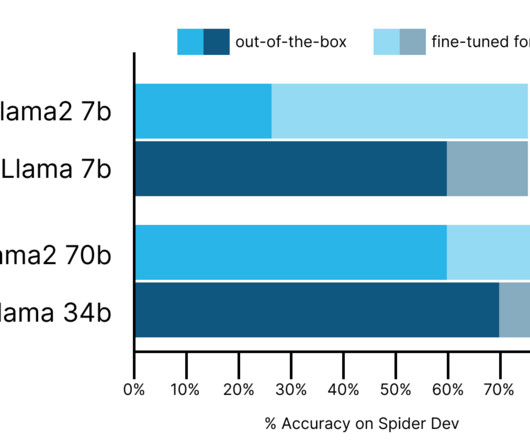
SQL—the standard programming language of relationaldatabases—was not included in these benchmarks. As part of our vision to bring generative AI and LLMs to the data , we are evaluating a variety of foundational models that could serve as the baseline for text-to-SQL capabilities in the Data Cloud.
In fact, you can describe big data from many different sources by these five characteristics: volume, value, variety, velocity and veracity. Even though the complexity, data shape and data volume are increasing and changing, companies are looking for simpler and faster database solutions.
And most of this data has to be handled in real-time or near real-time. Variety is the vector showing the diversity of Big Data. This data isn’t just about structureddata that resides within relationaldatabases as rows and columns. NoSQL databases. Apache Spark.
Making decisions in the database space requires deciding between RDBMS (RelationalDatabase Management System) and NoSQL, each of which has unique features. RDBMS uses SQL to organize data into structured tables, whereas NoSQL is more flexible and can handle a wider range of data types because of its dynamic schemas.
Structuringdata refers to converting unstructured data into tables and defining data types and relationships based on a schema. A data warehouse is a type of data management system that is designed to enable and support business intelligence (BI) activities, especially analytics. The Snowflake database. .
Did you know that almost all database management systems (DBMS) use a particular data organization model? This article provides an introduction to the relational model, which is by far the most common data organization model in DBMS today. What is the Relational Model in DBMS?
Data storing and processing is nothing new; organizations have been doing it for a few decades to reap valuable insights. Compared to that, Big Data is a much more recently derived term. So, what exactly is the difference between Traditional Data and Big Data? This is a good approach as it allows less space for error.
Data warehouses are typically built using traditional relationaldatabase systems, employing techniques like Extract, Transform, Load (ETL) to integrate and organize data. Data warehousing offers several advantages. By structuringdata in a predefined schema, data warehouses ensure data consistency and accuracy.
In terms of representation, data can be broadly classified into two types: structured and unstructured. Structureddata can be defined as data that can be stored in relationaldatabases, and unstructured data as everything else.
Big Data NoSQL databases were pioneered by top internet companies like Amazon, Google, LinkedIn and Facebook to overcome the drawbacks of RDBMS. RDBMS is not always the best solution for all situations as it cannot meet the increasing growth of unstructured data.
Data Ingestion Data ingestion refers to the process of importing data into a system or database for storage and analysis. This can involve extracting data from various sources, such as files, operational databases, APIs or IoT data, and transforming it into a format that is suitable for storage and analysis.
Hadoop Sqoop and Hadoop Flume are the two tools in Hadoop which is used to gather data from different sources and load them into HDFS. Sqoop in Hadoop is mostly used to extract structureddata from databases like Teradata, Oracle, etc., They enable the connection of various data sources to the Hadoop environment.
Ensuring all relevant data inputs are accounted for is crucial for a comprehensive ingestion process. Common Tools Data Sources Identification with Apache NiFi : Automates data flow, handling structured and unstructured data. Used for identifying and cataloging data sources.
A data warehouse implies a certain degree of preprocessing, or at the very least, an organized and well-defined data model. Data lakes, in contrast, are designed as repositories for all kinds of information, which might not initially be organized and structured. It is often used as a foundation for enterprise data lakes.
The storage system is using Capacitor, a proprietary columnar storage format by Google for semi-structureddata and the file system underneath is Colossus, the distributed file system by Google. This comes with the advantages of reduction of redundancy, data integrity and consequently, less storage usage.
One of the primary focuses of a Data Engineer's work is on the Hadoop data lakes. NoSQL databases are often implemented as a component of data pipelines. Data engineers may choose from a variety of career paths, including those of Database Developer, Data Engineer, etc.
link] Percona: JSON and RelationalDatabases – Part One Whether we like it or not, most data engineering and modeling challenges will be handling semi-structureddata in the coming years. SaaS companies like Salesforce and Zendesk are increasingly processing and emitting sem-structuredata.
SQL Structured Query Language, or SQL, is used to manage and work with relationaldatabases. Data scientists use SQL to query, update, and manipulate data. Data scientists can also organize unstructured raw data using SQL so that it can be analyzed with statistical and machine learning methods.
Data Engineers are skilled professionals who lay the foundation of databases and architecture. Using database tools, they create a robust architecture and later implement the process to develop the database from zero. Data engineers who focus on databases work with data warehouses and develop different table schemas.
Data collection revolves around gathering raw data from various sources, with the objective of using it for analysis and decision-making. It includes manual data entries, online surveys, extracting information from documents and databases, capturing signals from sensors, and more.
Along with the complexity of modern business comes the need to process data faster and more robustly. Because of this, standard transactional databases aren’t always the best fit. Instead, databases such as DynamoDB have been designed to manage the new influx of data. This is why companies turn towards DynamoDB.
So there will be a case an event might trigger a ride request, but the transactional database may fail the request and vice versa. It leads to an inconsistent state between the downstream systems and the transactional database. However, Event sourcing comes with a few major limitations.
Definition and examples Unstructured data , in its simplest form, refers to any data that does not have a pre-defined structure or organization. Unlike structureddata, which is organized into neat rows and columns within a database, unstructured data is an unsorted and vast information collection.
Big Data is a collection of large and complex semi-structured and unstructured data sets that have the potential to deliver actionable insights using traditional data management tools. Big data operations require specialized tools and techniques since a relationaldatabase cannot manage such a large amount of data.
Similarly, databases are only useful for today’s real-time analytics if they can be both strict and flexible. Traditional databases, with their wholly-inflexible structures, are brittle. So are schemaless NoSQL databases, which capably ingest firehoses of data but are poor at extracting complex insights from that data.
The toughest challenges in business intelligence today can be addressed by Hadoop through multi-structureddata and advanced big data analytics. Big data technologies like Hadoop have become a complement to various conventional BI products and services. Big data, multi-structureddata, and advanced analytics.
A data warehouse (DW) is a data repository that allows for storing and managing all the historical enterprise data, coming from disparate internal and external sources like CRMs, ERPs, flat files, etc. Initially, DWs dealt with structureddata presented in tabular forms. Data mart structure schemas.
A data lake is a centralized repository containing extensive storage for raw, unfiltered data coming into a company’s data storage system. This data can be structured, semi-structured, or unstructured and comes from various sources such as databases, IoT devices, log files, etc.
With RAG, when a customer makes an inquiry about an order, the system can retrieve their specific details from the database and generate a response with relevant follow-up options, like tracking a shipment or managing returns. The RAG chain starts with a user query, which triggers the system to fetch relevant data from the database.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content