This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Let’s create a validateutility.scala in the following path, src/main/scala/rockthejvm/websockets/domain , and add the following code: package rockthejvm.websockets.domain import cats.data.Validated object validateutility { def validateItem [ F ]( value : String , userORRoom : F , name : String ) : Validated [ String , F ] = { Validated.
FaunaDB is a cloud native database built by the engineers behind Twitter’s infrastructure and designed to serve the needs of modern systems. You listen to this show to learn and stay up to date with what’s happening in databases, streaming platforms, big data, and everything else you need to know about modern data management.
Value: /opt/cloudera/parcels/CDH/lib/hbase_connectors/lib/hbase-spark.jar:/opt/cloudera/parcels/CDH/lib/hbase_connectors/lib/hbase-spark-protocol-shaded.jar:/opt/cloudera/parcels/CDH/jars/scala-library-2.11.12.jar. Ensure you use the appropriate version numbers. Restart Region Servers.
For machine learning applications relational models require additional processing to be directly useful, which is why there has been a growth in the use of vector databases. Go to dataengineeringpodcast.com/linode today and get a $100 credit to launch a database, create a Kubernetes cluster, or take advantage of all of their other services.
Singlestore aims to cut down on the number of database engines that you need to run so that you can reduce the amount of copying that is required. By supporting fast, in-memory row-based queries and columnar on-disk representation, it lets your transactional and analytical workloads run in the same database.
Summary The database market has seen unprecedented activity in recent years, with new options addressing a variety of needs being introduced on a nearly constant basis. Despite that, there are a handful of databases that continue to be adopted due to their proven reliability and robust features.
If you want to master the Typelevel Scala libraries (including Http4s) with real-life practice, check out the Typelevel Rite of Passage course, a full-stack project-based course. HOTP scala implementation HOTP generation is quite tedious, therefore for simplicity, we will use a java library, otp-java by Bastiaan Jansen.
See example below: - template: id: wap type: wap tables: - ${CATALOG}/${DATABASE}/${TABLE} write_jobs: - job: id: write type: Spark spark: script: $S3{./src/sparksql_write.sql} Running code against a production database can be slow, especially with the overhead required for distributed data processing systems like Apache Spark.
This article is all about choosing the right Scala course for your journey. How should I get started with Scala? Do you have any tips to learn Scala quickly? How to Learn Scala as a Beginner Scala is not necessarily aimed at first-time programmers. Which course should I take?
Introduction The Typelevel stack is one of the most powerful sets of libraries in the Scala ecosystem. They allow you to write powerful applications with pure functional programming - as of this writing, the Typelevel ecosystem is one of the biggest selling points of Scala. The Typelevel stack is based on Cats and Cats Effect.
you could write the same pipeline in Java, in Scala, in Python, in SQL, etc.—with Native CDC for Postgres and MySQL — Snowflake will be able to connect to Postgres and MySQL to natively move data from your databases to the warehouse. Databricks sells a toolbox, you don't buy any UX. 3) Spark 4.0
The foundational skills are similar between traditional data engineers and AI data engineers are similar, with AI data engineers more heavily focused on machine learning data infrastructure, AI-specific tools, vector databases, and LLM pipelines. Let’s dive into the tools necessary to become an AI data engineer.
The thought of learning Scala fills many with fear, its very name often causes feelings of terror. The truth is Scala can be used for many things; from a simple web application to complex ML (Machine Learning). The name Scala stands for “scalable language.” So what companies are actually using Scala?
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. No more shipping and praying, you can now know exactly what will change in your database!
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. No more shipping and praying, you can now know exactly what will change in your database!
They no longer have to depend on any skilled Java or Scala developers to write special programs to gain access to such data streams. . To execute such real-time queries, the skills are typically in the hands of a select few in the organization who possess unique skills like Scala or Java and can write code to get such insights.
Play Framework “makes it easy to build web applications with Java & Scala”, as it is stated on their site, and it’s true. In this article we will try to develop a basic skeleton for a REST API using Play and Scala. PlayScala plugin defines default settings for Scala-based applications. import Keys._ getOrElse ( 0L ), carDTO.
Http4s is one of the most powerful libraries in the Scala ecosystem, and it’s part of the Typelevel stack. If you want to master the Typelevel Scala libraries with real-life practice, check out the Typelevel Rite of Passage course, a full-stack project-based course. content ) match case Right ( payload ) => IO ( database.
Http4s is one of the most powerful libraries in the Scala ecosystem, and it’s part of the Typelevel stack. If you want to master the Typelevel Scala libraries with real-life practice, check out the Typelevel Rite of Passage course, a full-stack project-based course. content ) match case Right ( payload ) => IO ( database.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
Within the scope of gen AI, this new Snowpark runtime empowers developers to efficiently and securely deploy containers to do things like the following and more: LLM fine-tuning Open-source vector database deployment Distributed embedding processing Voice to text transcription Why did Snowflake build a container service?
In this post, we’ll explore the differences between real-time analytics databases and stream processing frameworks. Differing Paradigms Stream processing systems and real-time analytics (RTA) databases are both exploding in popularity. Let’s start with a quick summary of both stream processing and RTA databases. Stateful Or Not?
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
This serverless data integration service can automatically and quickly discover structured or unstructured enterprise data when stored in data lakes in Amazon S3, data warehouses in Amazon Redshift, and other databases that are a component of the Amazon Relational Database Service. being data exactly matches the classifier, and 0.0
What are some of the potential pitfalls for automatic schema management in the target database? What are some of the potential pitfalls for automatic schema management in the target database? What are some of the complexities introduced by processing data from multiple customers with various compliance requirements?
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Just connect it to your database/data warehouse/data lakehouse/whatever you’re using and let them do the rest.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
This data engineering skillset typically consists of Java or Scala programming skills mated with deep DevOps acumen. Many times, users are left to push the stream of data into a traditional database, data lake, or data warehouse just to perform these simple computations. A rare breed. SQL as the democratization enabler.
To store and process even only a fraction of this amount of data, we need Big Data frameworks as traditional Databases would not be able to store so much data nor traditional processing systems would be able to process this data quickly. It also supports multiple languages and has APIs for Java, Scala, Python, and R.
In this blog post, we will delve into six such capabilities – comprehensive cross-cloud replication, zero copy database and schema clone, collation support, stored procedures, multi-table transactions, and transparent online upgrade – that every enterprise must consider while choosing their data platforms.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. No more shipping and praying, you can now know exactly what will change in your database!
Contact Info LinkedIn @fhueske on Twitter fhueske on GitHub Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?
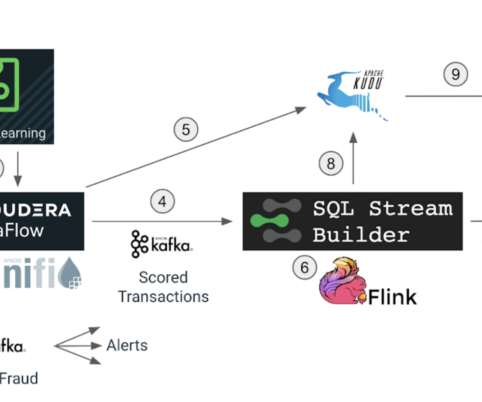
In this blog we will explore how we can use Apache Flink to get insights from data at a lightning-fast speed, and we will use Cloudera SQL Stream Builder GUI to easily create streaming jobs using only SQL language (no Java/Scala coding required). The streaming SQL job also saves the fraud detections to the Kudu database. Apache Flink.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. Just connect it to your database/data warehouse/data lakehouse/whatever you’re using and let them do the rest.
It is a declarative language for interacting with databases and allows you to create queries to extract information from your data sets. SQL in data science helps users collect data from the databases and later edit them if the situation demands it. Keep reading to know more about the data science coding languages.
cache, local space) 8 It supports multiple languages such as Java, Scala, R, and Python. RDDs can include any kind of Python, Java, or Scala object, including classes that the user has specified. Kafka stream can be used as part of microservice, as it's just a library. 7 Kafka stores data in Topic i.e., in a buffer memory.
The history repeat, we've seen it with Scala, Go or even Julia at some scale. ByteGraph: A Graph Database for TikTok — ByteGraph is the open-source graph database developed by the company behind TikTok. Enjoy the Data News. In the end Python and SQL are still here for good. But with Rust the approach is different.
Previous posts have looked at Algebraic Data Types with Java Variance, Phantom and Existential types in Java and Scala Intersection and Union Types with Java and Scala In this post we will combine some ideas from functional programming with strong typing to produce robust expressive code that is more reusable. Priority ( 4 , List.
Your host is Tobias Macey and today I’m interviewing Paul Dix about Influx Data and the different facets of the market for timeseries databases Interview Introduction How did you get involved in the area of data management? This has led to an explosion of database engines and related tools to address these different needs.
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. No more shipping and praying, you can now know exactly what will change in your database!
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. What if you could mimic your entire production database to create a realistic dataset with zero sensitive data?
With their new managed database service you can launch a production ready MySQL, Postgres, or MongoDB cluster in minutes, with automated backups, 40 Gbps connections from your application hosts, and high throughput SSDs. No more shipping and praying, you can now know exactly what will change in your database!
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content