This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The database is the major element of a data science project. To generate actionable insights, the database must be centralized and organized efficiently. If a corrupted, unorganized, or redundant database is used, the results of the analysis may become inconsistent and highly misleading. appeared first on Analytics Vidhya.
Introduction SQL injection is an attack in which a malicious user can insert arbitrary SQL code into a web application’s query, allowing them to gain unauthorized access to a database. We can use this to steal sensitive information or make unauthorized changes to the data stored in the database.
Introduction In the bustling arena of database management systems, two heavyweight contenders emerge, each carrying its arsenal of features and capabilities. In one corner, we have the suave and sophisticated Microsoft SQL Server (MSSQL), donned in the elegance of enterprise-level prowess.
Introduction Structured Query Language is a powerful language to manage and manipulate data stored in databases. SQL is widely used in the field of data science and is considered an essential skill to have if you work with data.
This generated data is stored in the database and will maintain it. SQL is a structured query language used to read and write these databases. In simple words, SQL is used […] The post Top 5 SQL Interview Questions With Implementation appeared first on Analytics Vidhya.
SQL2Fabric Mirroring is a new fully managed service offered by Striim to mirror on premise SQLDatabases. It’s a collaborative service between Striim and Microsoft based on Fabric Open Mirroring that enables real-time data replication from on-premise SQL Server databases to Azure Fabric OneLake.
Looking to learn SQL and databases to level up your data science skills? Learn SQL, database internals, and much more with these free university courses.
Introduction Data normalization is the process of building a database according to what is known as a canonical form, where the final product is a relational database with no data redundancy. More specifically, normalization involves organizing data according to attributes assigned as part of a larger data model.
Summary Databases are the core of most applications, whether transactional or analytical. In recent years the selection of database products has exploded, making the critical decision of which engine(s) to use even more difficult. What are the aspects of the database market that keep you interested as a VP of product?
Introduction SQL is a database programming language created for managing and retrieving data from Relational databases like MySQL, Oracle, and SQL Server. SQL(Structured Query Language) is the common language for all databases. In other terms, SQL is a language that communicates with databases.
This week, we delve into the vital world of Databases, SQL, Data Management, and Statistical Concepts in Data Science. Welcome back to Week 2 of KDnuggets’ "Back to Basics" series.
People assume that NoSQL is a counterpart to SQL. Instead, it’s a different type of database designed for use-cases where SQL is not ideal. The differences between the two are many, although some are so crucial that they define both databases at their cores.
The main thing I knew going in was "SDF understands SQL". For the next era of Analytics Engineering to be as transformative as the last, dbt needs to move beyond being a string preprocessor and into fully comprehending SQL. Today we're going to dig into what SQL comprehension actually means, since it's so critical to what comes next.
The free book is a combination of SQL cheat sheets and practical database examples. It provided bite-size information about every SQL function and attribute with coding samples.
Summary Databases come in a variety of formats for different use cases. The default association with the term "database" is relational engines, but non-relational engines are also used quite widely. Can you describe what constitutes a NoSQL database? Your first 30 days are free! Data lakes are notoriously complex.
Summary Stream processing systems have long been built with a code-first design, adding SQL as a layer on top of the existing framework. RisingWave is a database engine that was created specifically for stream processing, with S3 as the storage layer. Can you describe what RisingWave is and the story behind it?
Summary A significant portion of data workflows involve storing and processing information in database engines. Validating that the information is stored and processed correctly can be complex and time-consuming, especially when the source and destination speak different dialects of SQL. Your first 30 days are free!
Among the four big NoSQL database types, key-value stores are probably the most popular ones due to their simplicity and fast performance. Let’s further explore how key-value stores work and what are their practical uses.
SQL is the essential data science language due to its universal database accessibility, efficient data cleaning capabilities, seamless integration with other languages, and requirement for most data science jobs.
Summary Building a database engine requires a substantial amount of engineering effort and time investment. In this episode he explains how he used the combination of Apache Arrow, Flight, Datafusion, and Parquet to lay the foundation of the newest version of his time-series database. Your first 30 days are free!
In the era of the cloud most developers rely on hosted services to manage their databases, but what if you are a cloud service? RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. Why Postgres?
Graph databases are quickly becoming a core part of the analytics toolset for enterprise IT organizations. If you know SQL, you can easily learn Cypher and open up a huge opportunity for data analysis.
The current database includes 2,000 server types in 130 regions and 340 zones. Results are stored in git and their database, together with benchmarking metadata. Databases: SQLite files used to publish data Duck DB to query these files in the public APIs Cockroach DB : used to collect and store historical data.
RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. With Materialize, you can!
Data lineage refers to the process of tracing the journey of data as it moves through various systems, illustrating how data transitions from one data asset, such as a database table (the source asset), to another (the sink asset). In this blog, we will delve into an early stage in PAI implementation: data lineage. Hack, C++, Python, etc.)
Apache Sqoop stands for “SQL to Hadoop,” and is one such tool that transfers data between Hadoop(HIVE, HBASE, HDFS, etc.) and relational database servers(MySQL, Oracle, PostgreSQL, […] The post Top 8 Interview Questions on Apache Sqoop appeared first on Analytics Vidhya.
With dbt, you can apply software engineering practices to SQL development. Managing your SQL patrimony has never been easier. So, yes, dbt is cool but there is a common pattern with it: you accumulate SQL queries. Fast forward to 2 years later, you find yourself with hundreds or thousands of SQL queries. See the doc.
RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold You shouldn't have to throw away the database to build with fast-changing data.
Object-relational mapping, or ORM, is a technique that allows you to interact with databases using the object-oriented paradigm of the programming language of your choosing. How is that different from structured query language, though, and when do you use them?
However, scaling LLM data processing to millions of records can pose data transfer and orchestration challenges, easily addressed by the user-friendly SQL functions in Snowflake Cortex. Traditionally, SQL has been limited to structured data neatly organized in tables.
Materialization of data warehouse layers — What are the consideration for every materialisation you should pick in your data warehouse layer: view, tables, schema vs. databases, etc. The best code is the code you never wrote — Every line of code is a form of debt—a liability that must be maintained and understood.
dbt Core is an open-source framework that helps you organise data warehouse SQL transformation. In a simple words dbt sits on top of your raw data to organise all your SQL queries that are defining your data assets. a macro — a macro is a Jinja function that either do something or return SQL or partial SQL code.
With yato you give a folder with SQL queries and it guesses the DAG and runs the queries in the right order. BigQuery supports DELETE to delete partitions in a SQL query. I'd like to do a bit of user research about yato, if you consider using it drop me a message please. Give a lot of insights on the market.
RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team. It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. With Materialize, you can!
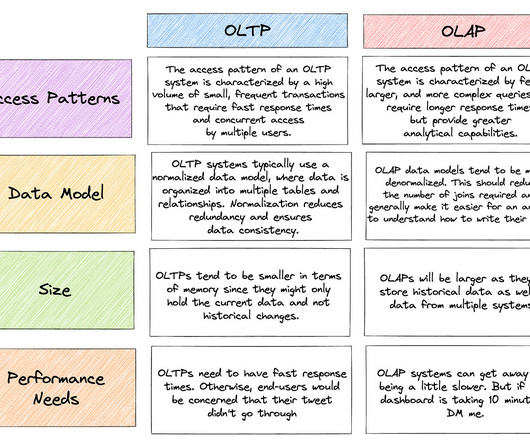
Adding databases like MongoDB and CassandraDB only makes matters worse, since they’re not SQL-friendly – the language most analysts and data practitioners are used to.… If you’re relying on your OLTP system to provide analytics, you might be in for a surprise.
Introduction Data replication is also known as database replication, which is copying data to ensure that all information remains consistent across all data resources in real-time. data replication is like a safety net that keeps your information safe from disappearing or falling through the cracks. In most cases, data alters.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content