This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The quality of data we feed to the algorithms […] The post Practicing Machine Learning with Imbalanced Dataset appeared first on Analytics Vidhya. The machine learning algorithms heavily rely on data that we feed to them.
Source: dataedo.com It is designed to handle big data and is ideal for […] The post Best Practices For Loading and Querying Large Datasets in GCP BigQuery appeared first on Analytics Vidhya. Its importance lies in its ability to handle big data and provide insights that can inform business decisions.
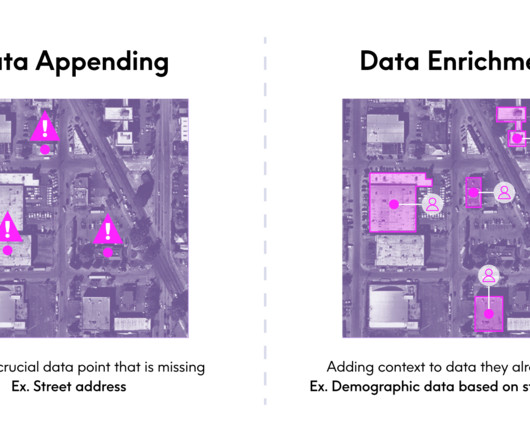
It's relatively easy to implement with static datasets because of the data availability. Data enrichment is one of common data engineering tasks. However, this apparently easy task can become a nightmare if used with inappropriate technologies.
In this eBook you will learn everything you need to know to get started, including: Key Airflow terms and concepts How to write and schedule your first DAG How to connect Airflow to other tools in your data ecosystem How to get started with two key Airflow features: Datasets and Dynamic task mapping A list of resources to continue your Airflow journey (..)
Some time ago I wrote a very simple comparison of switching from Pandas to Polars, I didn’t put much real effort into it, yet it was popular, so this is my attempt at trying to expand on that topic a […] The post How to JOIN datasets in Polars … compared to Pandas. appeared first on Confessions of a Data Guy.
Building an accurate machine learning and AI model requires a high-quality dataset. Introduction In this era of Generative Al, data generation is at its peak.
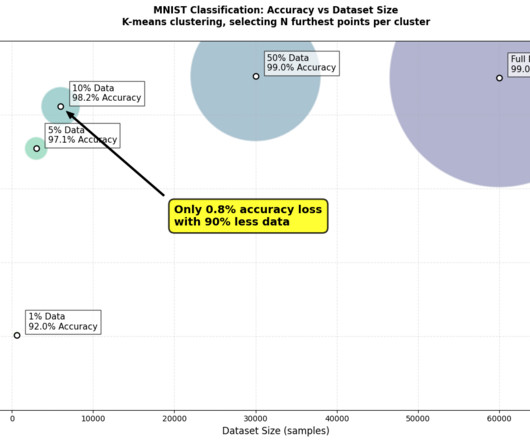
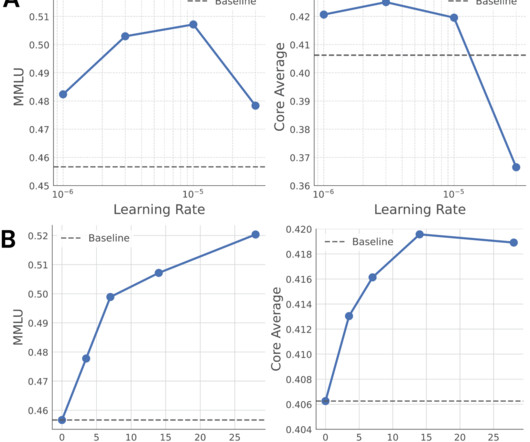
Best runs for furthest-from-centroid selection compared to full dataset. In my recent experiments with the MNIST dataset, thats exactly what happened. Data PruningResults The plot above shows the models accuracy compared to the training dataset size when using the most effective pruning method Itested. Image byauthor.
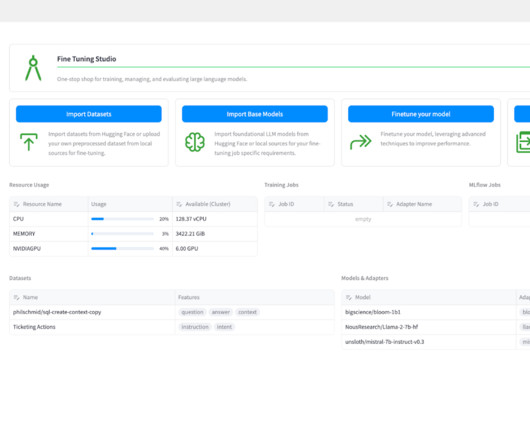
Fine Tuning Studio enables users to track the location of all datasets, models, and model adapters for training and evaluation. We can import this dataset on the Import Datasets page. The goal is to train an adapter for this base model that gives it better predictive capabilities for our specific dataset. Model Selection.
Understand input datasets available 3.1.2. Define what the output dataset will look like 3.1.3. Define checks to ensure the output dataset is usable 3.2. Introduction 2. Parts of data engineering 3.1. Requirements 3.1.1. Define SLAs so stakeholders know what to expect 3.1.4. Identify what tool to use to process data 3.3.
Introduction Large Language Models (LLMs) have given us a way to generate text, extract information, and identify patterns in industries from healthcare to.
The Counter Abstraction API resembles Java’s AtomicInteger interface: AddCount/AddAndGetCount : Adjusts the count for the specified counter by the given delta value within a dataset. We create one such Rollup table per dataset and use Cassandra as our persistent store. The delta value can be positive or negative.
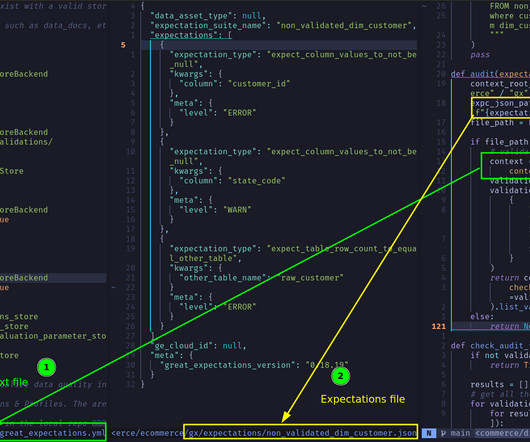
Running checks on one dataset 5.2. Checks involving the current dataset and its historical data 5.3. Checks involving comparing datasets 5. TL;DR: How the greatexpectations library works 4.1. greatexpectations quick setup 5. From an implementation perspective, there are four types of tests 5.1.
These models handle large tabular datasets with small parameter spaces, requiring innovative data solutions. At Yelp, we encountered challenges that prompted us to enhance the training time of our ad-revenue generating models, which use a Wide and Deep Neural Network architecture for predicting ad click-through rates (pCTR).
Introduction Big Data is a large and complex dataset generated by various sources and grows exponentially. It is so extensive and diverse that traditional data processing methods cannot handle it. The volume, velocity, and variety of Big Data can make it difficult to process and analyze.
Matthaus gives the dlt vision about creating the foundation for developers to be able to create sources in a wink creating a large ecosystem of APIs datasets easily maintainable. This is Croissant. Starting today it will be supported by 3 majors platforms: Kaggle, HuggingFace and OpenML.
Tajinder’s passion for unraveling hidden patterns in complex datasets has driven impactful outcomes, transforming raw data into actionable intelligence. Introduction Meet Tajinder, a seasoned Senior Data Scientist and ML Engineer who has excelled in the rapidly evolving field of data science.
Images and Videos: Computer vision algorithms must analyze visual content and deal with noisy, blurry, or mislabeled datasets. They are responsible for designing, implementing, and maintaining robust, scalable data pipelines that transform raw unstructured data—text, images, videos, and more—into high-quality, AI-ready datasets.
After my (admittedly lengthy) explanation of what I do as the EVP and GM of our Enrich business, she summarized it in a very succinct, but new way: “Oh, you manage the appending datasets.” Matching accuracy: Matching records between datasets is complex. ” That got me thinking.
Earlier this year, Precisely announced Data Link : an ecosystem of pre-linked datasets from leading data providers. Historically, seamless integration across these datasets has been extremely difficult they’re not standardized across providers, which leaves your team with tedious manual mapping and troubleshooting.
Big data is nothing but the vast volume of datasets measured in terabytes or petabytes or even more. Introduction In this technical era, Big Data is proven as revolutionary as it is growing unexpectedly. According to the survey reports, around 90% of the present data was generated only in the past two years.
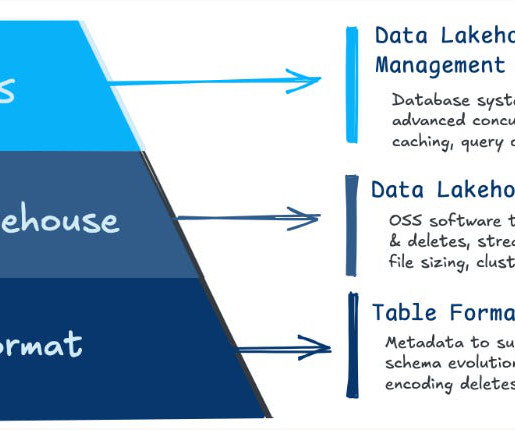
The Medallion architecture is a framework that allows data engineers to build organized and analysis-ready datasets in a lakehouse environment. For instance, suppose a new dataset from an IoT device is meant to be ingested daily into the Bronze layer. How do you ensure data quality in every layer?
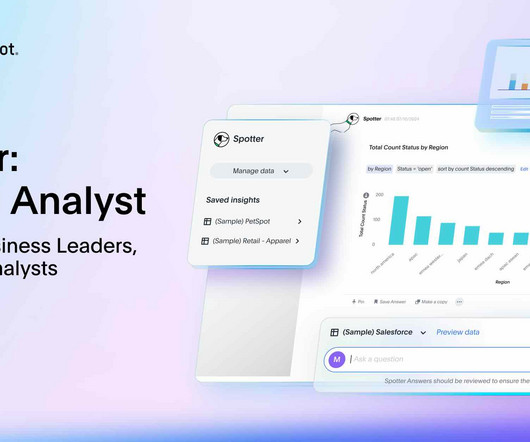
Level 2: Understanding your dataset To find connected insights in your business data, you need to first understand what data is contained in the dataset. Spotter quickly translates your datasets into business-friendly terminology so business users can confidently explore their data through natural language conversations.
This hybrid approach empowers enterprises to efficiently handle massive datasets while maintaining flexibility and reducing operational overhead. These advancements address enterprises' real-world challenges, such as maintaining fresh, up-to-date datasets and optimizing for high-throughput scenarios. Exploring Apache Hudi 1.0:
Data enrichment is the process of augmenting your organizations internal data with trusted, curated third-party datasets. The Multiple Data Provider Challenge If you rely on data from multiple vendors, you’ve probably run into a major challenge: the datasets are not standardized across providers. What is data enrichment?
It is a core component of the Apache Hadoop ecosystem and allows for storing and processing large datasets across multiple commodity servers. Introduction HDFS (Hadoop Distributed File System) is not a traditional database but a distributed file system designed to store and process big data.
A large international scientist collaboration released The Well : 2 massive datasets from physics simulation (15TB) to astronomical scientific data (100TB). It's easily readable (mildly large ~10 pages) and gives metrics about the performance plateau that we start to see at scale.
Tajinder’s passion for unraveling hidden patterns in complex datasets has driven impactful outcomes, transforming raw data into actionable intelligence. Introduction Meet Tajinder, a seasoned Senior Data Scientist and ML Engineer who has excelled in the rapidly evolving field of data science.
Now With Actionable, Automatic, Data Quality Dashboards Imagine a tool that can point at any dataset, learn from your data, screen for typical data quality issues, and then automatically generate and perform powerful tests, analyzing and scoring your data to pinpoint issues before they snowball. Announcing DataOps Data Quality TestGen 3.0:
Most jobs vendors have a ton of ‘junk jobs,’ so we spent a fair bit of time culling the dataset to jobs that are unique. During processing, we match companies, titles and more, with our dataset. We put the jobs data into Amazon S3. We have a network of Lamdas that fire any time new data is added.
The following diagram illustrates how the lineage graph has expanded: Collecting data flow signals for the AI system For our AI systems, we collect lineage signals by tracking relationships between various assets, such as input datasets, features, models, workflows, and inferences.
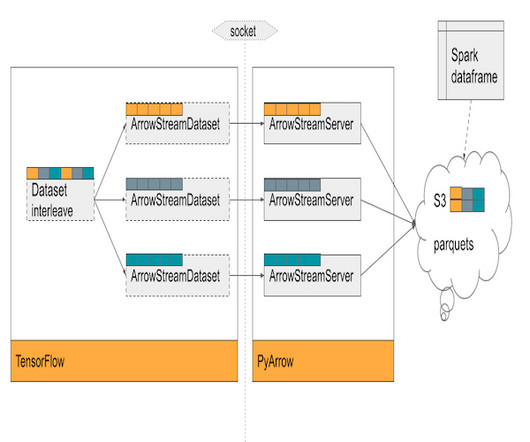
Architecture Overview The first pivotal step in managing impressions begins with the creation of a Source-of-Truth (SOT) dataset. This foundational dataset is essential, as it supports various downstream workflows and enables a multitude of usecases.
Machine learning models : trained on labeled datasets using supervised learning and improved through unsupervised learning to identify patterns and anomalies in unlabeled data. For example, in the data warehouse, it’s represented as a Dataset – an in-code Python class capturing the asset’s schema and metadata.
Each project, from beginner tasks like Image Classification to advanced ones like Anomaly Detection, includes a link to the dataset and source code for easy access and implementation.
I found the blog to be a fresh take on the skill in demand by layoff datasets. Our internal benchmark of the NYC dataset shows a 48% performance gain of smallpond over Spark!! Whether you use Datasets already or want to get started, we've got you covered! link] Mehdio: DuckDB goes distributed?
Synthetic data works by leveraging models to create artificial datasets that reflect what someone might find organically (in some alternate reality where more data actually exists), and then using that new data to train their own models. But is synthetic data a long-term solution? Probably not.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content