This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Filling in missing values could involve leveraging other company data sources or even third-party datasets. Data Normalization Data normalization is the process of adjusting related datasets recorded with different scales to a common scale, without distorting differences in the ranges of values.
The customer had traditional ETLtools on the table; we were in fact already providing them services around Oracle Data Integrator (ODI). They asked us to evaluate whether we thought an ETLtool was the appropriate choice to solve these two requirements.
Tools like Databricks, Tabular and Galaxy try to solve this problem and it really feels like the future. Indeed, datalakes can store all types of data including unstructured ones and we still need to be able to analyse these datasets. set_upstream(t1) Bubbles [11] is another open-source tool for ETL in the Python world.
These skills are essential to collect, clean, analyze, process and manage large amounts of data to find trends and patterns in the dataset. The dataset can be either structured or unstructured or both. They also make use of ETLtools, messaging systems like Kafka, and Big Data Tool kits such as SparkML and Mahout.
Impala works best for analytical performance with properly designed datasets (well-partitioned, compacted). Spark is primarily used to create ETL workloads by data engineers and data scientists. So which open source pipeline tool is better, NiFi or Airflow? Over time, those practices lead to cluster and Impala instability.
Data Ingestion Data ingestion is the first step of both ETL and data pipelines. In the ETL world, this is called data extraction, reflecting the initial effort to pull data out of source systems. ETLtools usually pride themselves on their ability to extract from many variations of source systems.
Operational analytics is the process of creating data pipelines and datasets to support business teams such as sales, marketing, and customer support. Data teams would then point tools like Metabase, Looker, or Tableau at these datasets and teams could do analysis and business intelligence. What is Operational Analytics?
We’ll talk about when and why ETL becomes essential in your Snowflake journey and walk you through the process of choosing the right ETLtool. Our focus is to make your decision-making process smoother, helping you understand how to best integrate ETL into your data strategy. But first, a disclaimer.
Data scientist’s responsibilities — Datasets and Models. Machine learning algorithms are designed to solve specific problems, though other conditions factor in the choice: the dataset size, the training time that you have, number of features, etc. Distinction between data scientists and engineers is similar. Let’s explore it.
Common Challenges in Data Versioning Best Practices for Implementing Data Versioning Data Versioning Tools and Technologies Tracking Data Versions with Monte Carlo What is Data Versioning? Data versioning is the practice of tracking and managing changes to datasets over time. Tracking changes between versions.
Lineage provides users with the ability to see the upstream dependencies associated with a particular data set and the transformations applied to create the dataset. This makes lineage a useful tool in analysis, but also in identifying and diagnosing issues. Review ETLtool logs if you have access.
Or we can leverage third party ETLtools but for this scenario me and my colleague Gautam has focused on Salesforce product features. LIVE Connection and Dataset Click on your dataset and it will open a visualization window On left ,select the desired columns you want to show in your report.
Semantic Correctness — The core.rider_events derived dataset shows a drastic increase in today’s cancels volume, caused by a bug in the origin web service creating the event. This is useful because these users are often not familiar with ETLtooling.
Data profiling tools: Profiling plays a crucial role in understanding your dataset’s structure and content. Improved data quality The primary goal of using data testing tools is to enhance the overall quality of an organization’s data assets. This is part of a series of articles about data quality.
In general, there are a few questions to ask yourself about your data before choosing one of these tools: Who at your company will be loading the data? How big is the dataset? Below is a summary table highlighting the core benefits and drawbacks of certain ETLtooling options for getting spreadsheet data in your data warehouse.
The purpose of data extraction is to transform large, unwieldy datasets into a usable and actionable format. Data extraction serves as a means for businesses to harness the potential hidden within these otherwise challenging datasets, often extending their utility beyond their original intended purpose.
The choice of tooling and infrastructure will depend on factors such as the organization’s size, budget, and industry as well as the types and use cases of the data. Data Pipeline vs ETL An ETL (Extract, Transform, and Load) system is a specific type of data pipeline that transforms and moves data across systems in batches.
An AI Data Quality Analyst should be comfortable with: Data Management : Proficiency in handling large datasets. Tools : Familiarity with data validation tools, data wrangling tools like Pandas , and platforms such as AWS , Google Cloud , or Azure. Data Validation Tools : Great Expectations, Apache Griffin.
Data cleansing is the process of identifying and correcting or removing inaccurate records from the dataset, improving the data quality. effective communication that’s essential for coordinating ETL tasks, managing dependencies, and ensuring that everyone is aware of schedules, downtimes, and changes.
It’s a new approach to making data actionable and solving the “last mile” problem in analytics by empowering business teams to access—and act on—transformed data directly in the SaaS tools they already use every day. For instance, one common cause of data downtime is freshness – i.e. when data is unusually out-of-date.
It is a cloud-based service by Amazon Web Services (AWS) that simplifies processing large, distributed datasets using popular open-source frameworks, including Apache Hadoop and Spark. EMR is a service used by data scientists to preprocess large datasets, feature engineering, and small-scale training of models.
A data migration is the process where old datasets, perhaps resting in outdated systems, are transferred to newer, more efficient ones. And the larger your datasets, the more meticulous planning you have to do. What makes data migrations complex? Sure, you’re moving data from point A to point B, but the reality is far more nuanced.
DatasetsDatasets in Azure Data Factory define the schema and location of data sources or sinks. By specifying details like the file format, storage location, and table structure, datasets enable efficient data access and manipulation, ensuring that pipelines can interact with data consistently and accurately.
Their roles are expounded below: Acquire Datasets: It is about acquiring datasets that are focused on defined business objectives to drive out relevant insight. Data Warehousing: Experience in using tools like Amazon Redshift, Google BigQuery, or Snowflake. ETLTools: Worked on Apache NiFi, Talend, and Informatica.
Being an ETLtool, Tableau Prep helps collect data from different sources, cleans them up, and then blends and loads the required data into other places for further analysis. Connecting to Data Begin by selecting your dataset. Choose your dataset and click Open. Choose your dataset and click Open.
Maintenance: Bugs are common when dealing with different sizes and types of datasets. They develop skills that can be achieved by any individual with enough practice: Problem-solving skills: Big data is about solving the problem and obtaining optimized and well-structured information from the dataset. Salary: $135,000 - $165,000 2.
Maintenance: Bugs are common when dealing with different sizes and types of datasets. Problem-solving skills Big data is about solving the problem and obtaining optimized and well-structured information from the dataset. This is done by specific data analyzing algorithms implemented into the data models to analyze the data efficiently.
Apache Spark: Spark and MongoDB can work together using the MongoDB Connector for Apache Spark to run massive dataset processing. ETLTools: ETLtooling such as Apache Nifi or Talend is capable of handling data extraction-, transformation- and load operations on MongoDB.
For example, integrity issues can affect Sales and Operations Planning (S&OP), Enterprise Resource Planning (ERP), and Customer Relationship Management (CRM), all leveraging the same dataset. Read more about our Reverse ETLTools. This has the potential to impact the entire business operations. featured image via unsplash
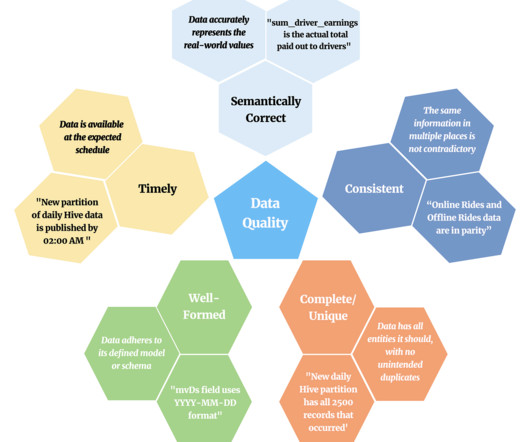
Ryan Yackel June 14, 2023 Understanding Data Quality Testing Data quality testing refers to the evaluation and validation of a dataset’s accuracy, consistency, completeness, and reliability. Regularly testing your datasets reduces the likelihood of such occurrences by detecting inconsistencies early on.
This highly consumable dataset is called a materialized view (MV), and BI tools and applications can use the MV REST endpoint to query streams of data without a dependency on other systems. Reduce ingest latency and complexity: Multiple point solutions were needed to move data from different data sources to downstream systems.
As organizations expand and data sources multiply, automated ETL can seamlessly scale to meet these rising demands without a significant overhaul of the existing infrastructure. Enhanced Optimization: Automated ETLtools employ advanced algorithms and techniques that constantly optimize data extraction, transformation, and loading processes.
Users can experiment with different data transformations, combine disparate datasets, and discover new patterns or relationships. Exploring these tools should give you a very cool overview of ETLtools being used in the market today. If you need help to understand how these tools work, feel free to drop us a message!
The Yelp dataset consists of information on Yelp's companies, user reviews, and other information that has been made freely available for personal, educational, and scholarly use. This dataset covers 6,685,900 reviews, 192,609 businesses, and 200,000 photos across ten metropolitan areas. Create an oil-well monitoring application.
This table only stores the current attributes for each user, and is then loaded into the various SaaS platforms via Reverse ETLtools. Introduction Most data modeling approaches for customer segmentation are based on a wide table with user attributes. Take for example a Customer Experience (CX) team that uses Salesforce as a CRM.
An analytics engineer is a modern data team member that is responsible for modeling data to provide clean, accurate datasets so that different users within the company can work with them. One of the core responsibilities of an analytics engineer is to model raw data into clean, tested, and reusable datasets. Data modeling.
Listed below are some of the interesting features we found: Query Log Ingestion and the Behavioral Analysis Engine (BAE) Alation has a tool that will ingest and parse queries. You can determine which datasets are popular and might be a good candidate to transition to the data catalog right away.
Improved Collaboration Among Teams Data engineering teams frequently collaborate with other departments, such as analysts or scientists, who depend on accurate datasets for their tasks. Anomaly detection: Lets you automatically detect anomalies within datasets or pipelines based on historical patterns or predefined rules.
Customer data integration here might include creating a data warehouse where you can house your accurate and complete dataset. Actionability Data warehouses enable you to perform operational analytics straight from the warehouse itself, or use a Reverse ETLtool to connect it with the tools you already use for analytics.
Data quality testing is the process of validating that key characteristics of a dataset match what is anticipated prior to its consumption. Inaccurate data refers to the distribution issues that arise from incorrectly represented datasets. In this case, the SLI would be something like “hours since dataset refreshed.”
Loading data from different datasets and deciding on which file format is efficient for a task. Develop efficient pig and hive scripts with joins on datasets using various techniques. Assess the quality of datasets for a hadoop data lake. Understanding the usage of various data visualizations tools like Tableau, Qlikview, etc.
Seesaw was able to scale up its main database, an Amazon DynamoDB cloud-based service optimized for large datasets. Rockset’s native DynamoDB connector automatically ingests and indexes all data within seconds, without ETL, to enable sub-second SQL queries. Storing all of that data was not a problem.
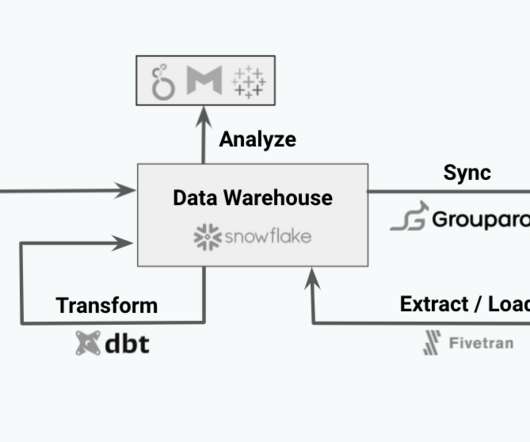
To goal is to create a consistent and coherent dataset compatible with analytical applications and services. After data has been transformed, the next step is to then make that data actionable using a Reverse ETLtool such as Grouparoo. featured image via unsplash
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content