This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These skills are essential to collect, clean, analyze, process and manage large amounts of data to find trends and patterns in the dataset. The dataset can be either structured or unstructured or both. They also make use of ETLtools, messaging systems like Kafka, and Big Data Tool kits such as SparkML and Mahout.
Data scientist’s responsibilities — Datasets and Models. Machine learning algorithms are designed to solve specific problems, though other conditions factor in the choice: the dataset size, the training time that you have, number of features, etc. Distinction between data scientists and engineers is similar. Let’s explore it.
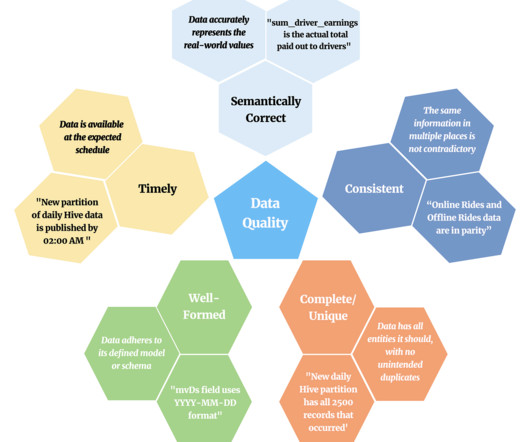
Semantic Correctness — The core.rider_events derived dataset shows a drastic increase in today’s cancels volume, caused by a bug in the origin web service creating the event. This is useful because these users are often not familiar with ETLtooling. As such, DynamoDB was a natural choice as a NoSQL key-value store.
MongoDB is a NoSQL database that’s been making rounds in the data science community. MongoDB is used for data science, meaning that we utilize the capabilities of this NoSQL database system as part of our data analysis and data modeling processes, which fall under the realm of data science. What is MongoDB for Data Science?
Their roles are expounded below: Acquire Datasets: It is about acquiring datasets that are focused on defined business objectives to drive out relevant insight. Databases: Knowledgeable about SQL and NoSQL databases. Data Warehousing: Experience in using tools like Amazon Redshift, Google BigQuery, or Snowflake.
Seesaw was able to scale up its main database, an Amazon DynamoDB cloud-based service optimized for large datasets. However, Seesaw’s DynamoDB database stored the data in its own NoSQL format that made it easy to build applications, just not analytical ones. Storing all of that data was not a problem.
A data migration is the process where old datasets, perhaps resting in outdated systems, are transferred to newer, more efficient ones. And the larger your datasets, the more meticulous planning you have to do. What makes data migrations complex? Sure, you’re moving data from point A to point B, but the reality is far more nuanced.
It is a cloud-based service by Amazon Web Services (AWS) that simplifies processing large, distributed datasets using popular open-source frameworks, including Apache Hadoop and Spark. EMR is a service used by data scientists to preprocess large datasets, feature engineering, and small-scale training of models.
Skills Required Data architects must be proficient in programming languages such as Python, Java, and C++, Hadoop and NoSQL databases, predictive modeling, and data mining, and experience with data modeling tools like Visio and ERWin. Average Annual Salary of Data Architect On average, a data architect makes $165,583 annually.
Interested in NoSQL databases? MongoDB Careers: Overview MongoDB is one of the leading NoSQL database solutions and generates a lot of demand for experts in different fields. Experience with ETLtools and data integration techniques. If so, you need to go somewhere else. But first, let’s discuss MongoDB a bit.
It is possible to move datasets with incremental loading (when only new or updated pieces of information are loaded) and bulk loading (lots of data is loaded into a target source within a short period of time). They include NoSQL databases (e.g., Talend Open Studio: versatile open-source tool for innovative projects.
Traditional data transformation tools are still relevant today, while next-generation Kafka, cloud-based tools, and SQL are on the rise for 2023. NoSQL If you think that Hadoop doesn't matter as you have moved to the cloud, you must think again. Knowledge of requirements and knowledge of machine learning libraries.
It backs up and restores relational DBMS, NoSQL, data warehouses, and any other data repository types. The actual mapping and transformation work will be performed using the AWS SCT tool, and a small percentage of manual intervention could be required to map the complex schemas. Is AWS DMS an ETLtool?
ETL (extract, transform, and load) techniques move data from databases and other systems into a single hub, such as a data warehouse. Get familiar with popular ETLtools like Xplenty, Stitch, Alooma, etc. They must be skilled at creating solutions that use the Azure Cosmos DB for NoSQL API.
Sqoop ETL: ETL is short for Export, Load, Transform. The purpose of ETLtools is to move data across different systems. Apache Sqoop is one such ETLtool provided in the Hadoop environment. HBase is a NoSQL database, but the data can be dumped into HBase as well.
6) Hive Hadoop Component is helpful for ETL whereas Pig Hadoop is a great ETLtool for big data because of its powerful transformation and processing capabilities. 2) Hive Hadoop Component is used for completely structured Data whereas Pig Hadoop Component is used for semi structured data.
Business win online when they use hard-to-copy technology to deliver a superior customer experience through mining larger and larger datasets.”- Thus, organizations must make use of effective ETLtools to ease the process of data preparation that requires a less complex IT infrastructure.
Since non-RDBMS are horizontally scalable, they can become more powerful and suitable for large or constantly changing datasets. Data architects require practical skills with data management tools including data modeling, ETLtools, and data warehousing. E.g. PostgreSQL, MySQL, Oracle, Microsoft SQL Server.
To solve this last mile problem and ensure your data models actually get used by business team members, you need to sync data directly to the tools your business team members use day-to-day, from CRMs like Salesforce to ad networks, email tools and more. The NoSQL movement is continuing to mature after fifteen years of innovation.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content