This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datasets are the repository of information that is required to solve a particular type of problem. Datasets play a crucial role and are at the heart of all Machine Learning models. Datasets are often related to a particular type of problem and machine learning models can be built to solve those problems by learning from the data.
Everyday the global healthcare system generates tons of medical data that — at least, theoretically — could be used for machine learning purposes. In this post, we’ll briefly discuss challenges you face when working with medical data and make an overview of publucly available healthcare datasets, along with practical tasks they help solve.
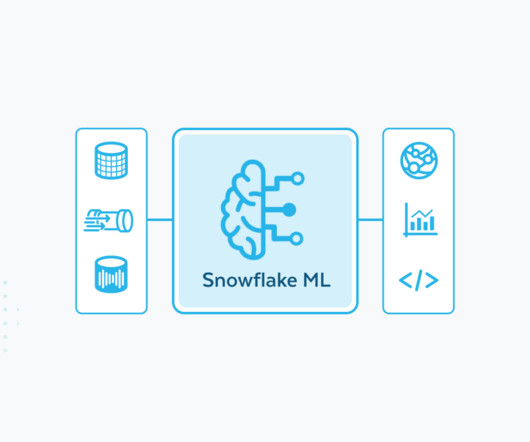
For image data, running distributed PyTorch on Snowflake ML also with standard settings resulted in over 10x faster processing for a 50,000-image dataset when compared to the same managed Spark solution. CHG builds and productionizes its end-to-end ML models in Snowflake ML.
Open-source models are often pre-trained on big datasets, allowing developers to fine-tune them for specific tasks or industries. Pre-trained Models : These models are pre-trained on large-scale datasets, saving developers significant time and resources while also enabling the use of transfer learning.
To allow innovation in medical imaging with AI, we need efficient and affordable ways to store and process these WSIs at scale. load training metadata dataset = PatchDataset ( slides_specs = slides_specs ) train_loader = DataLoader ( dataset ) trainer = pl. Then this dataset can be plugged to our PyTorch script using.to_torch.
This article describes how data and machine learning help control the length of stay — for the benefit of patients and medical organizations. The length of stay (LOS) in a hospital , or the number of days from a patient’s admission to release, serves as a strong indicator of both medical and financial efficiency. Source: Intel.
Data imputation is the method of filling in missing or unavailable information in a dataset with other numbers. Impacts on the Final Model Missing data may lead to bias in the dataset, which could affect the final model’s analysis. What Is Data Imputation? This process is important for keeping data analysis accurate.
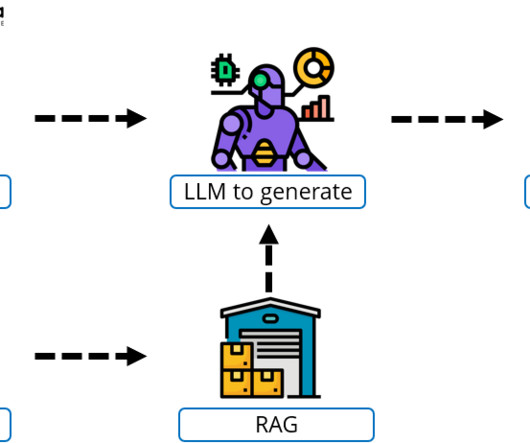
Because they are trained on huge datasets and have billions of factors. RAG retrieves medical guidelines or research papers and generates patient-specific advice or summaries for healthcare providers. Healthcare RAG system needs extensive medicaldatasets and context-aware retrieval for accuracy.
It can be manually transformed into structured data by hospital staff, but it’s never a priority in the medical setting. It creates barriers in already bloated administrative tasks and in case of emergency, can lead to medical complications. Medical transcription. Amazon Transcribe Medical. Available solutions.
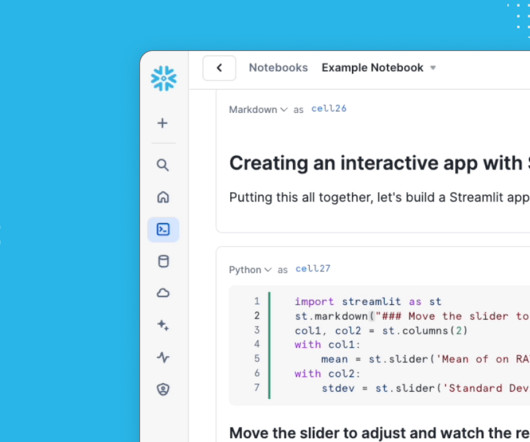
Step 4: Test-driving the deployment For our example, we will use the model to run text categorization for a news items dataset from Kaggle , which we first store in a Snowflake table.
Datasets are obtained, and forecasts are made using a regression approach. Applications Online Realtors Heart Disease Prognosis This project is helpful from a medical aspect because it is intended to offer online medical advice and direction to those with cardiac issues.
Pattern recognition is used in a wide variety of applications, including Image processing, Speech recognition, Biometrics, Medical diagnosis, and Fraud detection. And is used in a wide variety of applications, including image processing, speech recognition, and medical diagnosis.
Overview of DeepSeek AI’s Research Paper DeepSeek AI’s research paper goes into great depth about the architecture, dataset selection, model training, and performance benchmarks. Advanced Fine-Tuning and RLHF (Reinforcement Learning with Human Feedback) Fine-tuned using domain-specific datasets to improve real-world applications.
By learning the details of smaller datasets, they better balance task-specific performance and resource efficiency. It is seamlessly integrated across Meta’s platforms, increasing user access to AI insights, and leverages a larger dataset to enhance its capacity to handle complex tasks. What are Small language models?
CycleGAN, unlike traditional GANs, does not require paired datasets, in which each image in one domain corresponds to an image in another. Problem With Image-to-Image Translation Traditional picture-to-image translation algorithms, such as Pix2Pix, need paired datasets, in which each input image corresponds to a target image.
For further steps, you need to load your dataset to Python or switch to a platform specifically focusing on analysis and/or machine learning. You have three options to obtain data to train machine learning models: use free sound libraries or audio datasets, purchase it from data providers or collect it involving domain experts.
Today, we will delve into the intricacies the problem of missing data , discover the different types of missing data we may find in the wild, and explore how we can identify and mark missing values in real-world datasets. Image by Author. Let’s consider an example. Image by Author. Image by Author. Image by Author.
Even if an incorrect diagnosis was made, you would still want that to remain on the record (along with the correct updated diagnoses) so a medical professional could understand the full history, and context of a patient’s journey.
CHG Healthcare , a healthcare staffing company with over 45 years of industry expertise, uses AI/ML to power its workforce staffing solutions across 700,000 medical practitioners representing 130 medical specialties. CHG builds and productionizes its end-to-end ML models in Snowflake ML.
Applied in everything from medical development to image creation, VAEs learn to compress and creatively replicate data. Designing the Model We’ll use TensorFlow and Keras to build a VAE for the MNIST dataset. Ever utilized a program that creates blurriness-enhanced images or lifelike faces?
The main agenda is to remove the redundant and dependent features by changing the dataset onto a lower-dimensional space. variables) in a particular dataset while retaining most of the data. They make predictions based upon the probability that a new input dataset belongs to each class.
Dataset-dependent : IS relies on the Inception model trained on ImageNet, which may not be suitable for non-natural images (e.g., medical scans). Higher scores mean better quality and diversity, but ideal values depend on the dataset. To tackle these, researchers often compare IS with a more robust metric, FID.
FSL uses this idea to help with situations where it is hard, costly, or almost impossible to collect data, like: Finding rare diseases when there isn’t much medical image data available. Training the Similarity Function A big-named dataset like ImageNet is used to teach the model how to understand similarities in a supervised way.
Nonetheless, it is an exciting and growing field and there can't be a better way to learn the basics of image classification than to classify images in the MNIST dataset. Table of Contents What is the MNIST dataset? Test the Trained Neural Network Visualizing the Test Results Ending Notes What is the MNIST dataset?
Pre-training and Fine-tuning BERT’s exceptional language understanding is the result of a two-stage process: Pre-training: Two tasks are used to pre-train BERT on big-text datasets: Masked Language Modeling (MLM): With the help of context, the model learns to guess the meaning of unseen words in sentences. legal, medical).
Machine learning offers scalability and efficiency, processing large datasets quickly. A dataset's anomalies may provide valuable information about inconsistencies, mistakes, fraud, or unusual events. Global or Point Outliers: These anomalies are discrete data points that stand out from the rest of the dataset in a significant way.
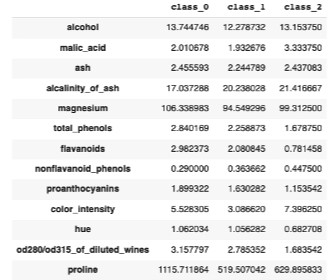
Types of Machine Learning: Machine Learning can broadly be classified into three types: Supervised Learning: If the available dataset has predefined features and labels, on which the machine learning models are trained, then the type of learning is known as Supervised Machine Learning. A sample of the dataset is shown below.
They can work with various tools to analyze large datasets, including social media posts, medical records, transactional data, and more. R has become increasingly popular among data scientists because of its ease of use and flexibility in handling complex analyses on large datasets.
These models are trained on vast datasets which allow them to identify intricate patterns and relationships that human eyes might overlook. In healthcare, generative AI can assist in medical image analysis and report writing, while predictive models forecast patient outcomes. And that’s the tip of the iceberg of possibilities.
It improves accessibility, encourages innovation for greater value, lowers disparities in research and treatment, and harnesses large-scale medical data analysis to create new data. Treatment strategies are customized using machine learning and predictive analytics according to a patient’s medical history.
It has completely changed our approach to medical diagnosis, treatment, and remote patient care. From medical image analysis to drug discovery and personalized treatment, Generative AI is revolutionizing global health initiatives and telemedicine. It is critical to prevent the progression of disease and improve treatment outcomes.
Digitizing medical reports and other records is one of the critical tasks for medical institutions to optimize their document flow. But some healthcare organizations like FDA implement various document classification techniques to process tons of medical archives daily. Stating categories and collecting training dataset.
Fig: 1: Image Annotation Challenges of manual Annotation Complications in manually annotating visual data: It is Time-consuming and labor-intensive, especially for large datasets. Scalability limitations which make it impractical for large datasets. Initially, we used a custom dataset focused on potholes.
It involves analyzing vast amounts of health-related data, including health records, medical images, and genetic information, using machine learning algorithms, natural language processing, computer vision, and other AI technologies to enhance the health of patients, lower costs, and boost the effectiveness of the delivery of healthcare.
Data analytics projects involve using statistical and computational techniques to analyse large datasets with the aim of uncovering patterns, trends, and insights. These datasets can be used to explore a wide range of research topics, including healthcare, finance, marketing , and social media. Let’s delve deep to understand it.
“Maybe you could have multiple destinations on Earth with the same dataset, doing different things.” In healthcare , for example, doctors are starting to leverage ML for real-time analysis of data to improve medical care. Moreover, interpreting AI results from the data is not overly difficult.
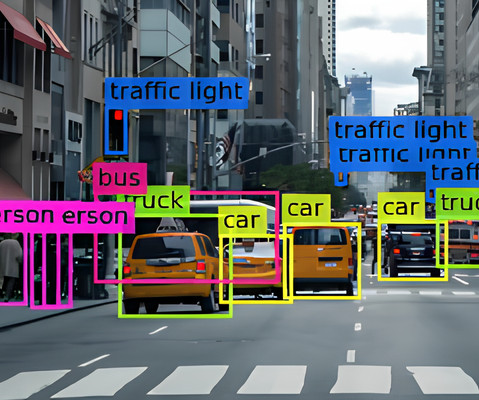
Machine learning models rely heavily on large and diverse datasets to train and improve their ability to understand and interpret visual information. From recognizing faces and detecting objects to navigating autonomous vehicles and dissecting medical images, its applications span a wide spectrum.
From documenting losses and damages to verifying that a claim submission meets all the necessary criteria, each step requires meticulous attention to detail and often entails reviewing lengthy narrative documents such as accident reports, medical records, and legal demands letters.
For example, if a patient has been using a certain medication for a long time and has not caused any side effects yet, then it might be safe for that patient to continue using this medication. Analysing medical images has been proven to identify the tiniest microscopic defects.
For instance, sales of a company, medical records of a patient, stock market records, tweets, Netflix’s list of programs, audio files on Spotify, log files of a self-driven car, your food bill from Zomato, and your screen time on Instagram. There is a much broader spectrum of things out there which can be classified as data.
The publicly available Kaggle dataset of the Tesla Stock Data from 2010 to 2020 can be used to implement this project. Maybe you could even consider gathering more data from the source of the Tesla Stock dataset. You could undertake this exercise using the publicly available Cervical Cancer Risk Classification Dataset.
Spark's primary data structure is Resilient Distributed Datasets (RDD). Each dataset in an RDD is split into logical divisions that may be calculated on several cluster nodes. Memory Management RDD is used by Spark to store data in a distributed fashion (i.e., cache, local space). It is a distributed collection of immutable things.
They are trained on large datasets to recognise patterns and make predictions or decisions based on new information. During the model evaluation phase (validation mode), we will use a labelled dataset of emails to calculate metrics like accuracy, precision and recall. At their core, ML models learn from data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content