This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Meet Tajinder, a seasoned Senior Data Scientist and ML Engineer who has excelled in the rapidly evolving field of data science. Tajinder’s passion for unraveling hidden patterns in complex datasets has driven impactful outcomes, transforming rawdata into actionable intelligence.
Datasets are the repository of information that is required to solve a particular type of problem. Also called data storage areas , they help users to understand the essential insights about the information they represent. Datasets play a crucial role and are at the heart of all Machine Learning models.
It sounds great, but how do you prove the data is correct at each layer? How do you ensure data quality in every layer ? Bronze, Silver, and Gold – The Data Architecture Olympics? The Bronze layer is the initial landing zone for all incoming rawdata, capturing it in its unprocessed, original form.
Introduction Meet Tajinder, a seasoned Senior Data Scientist and ML Engineer who has excelled in the rapidly evolving field of data science. Tajinder’s passion for unraveling hidden patterns in complex datasets has driven impactful outcomes, transforming rawdata into actionable intelligence.
Level 2: Understanding your dataset To find connected insights in your business data, you need to first understand what data is contained in the dataset. This is often a challenge for business users who arent familiar with the source data. In this example, were asking, What is our customer lifetime value by state?
What is Data Transformation? Data transformation is the process of converting rawdata into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis.
Storing data: data collected is stored to allow for historical comparisons. The historical dataset is over 20M records at the time of writing! This means about 275,000 up-to-date server prices, and around 240,000 benchmark scores.
In this blog, well explore Building an ETL Pipeline with Snowpark by simulating a scenario where commerce data flows through distinct data layersRAW, SILVER, and GOLDEN.These tables form the foundation for insightful analytics and robust business intelligence. They need to: Consolidate rawdata from orders, customers, and products.
The result of these batch operations in the data warehouse is a set of comma delimited text files containing the unfiltered rawdata logs for each user. We do this by passing the rawdata through various renderers, discussed in more detail in the next section.
Bring your raw Google Analytics data to Snowflake with just a few clicks The Snowflake Connector for Google Analytics makes it a breeze to get your Google Analytics data, either aggregated data or rawdata, into your Snowflake account. Here’s a quick guide to get started: 1.
To try and predict this, an extensive dataset including anonymised details on the individual loanee and their historical credit history are included. As a machine learning problem, it is a classification task with tabular data, a perfect fit for RAPIDS. Get the Dataset. The dataset can be downloaded from: [link].
The application you're implementing needs to analyze this data, combining it with other datasets, to return live metrics and recommended actions. But how can you interrogate the data and frame your questions correctly if you don't understand the shape of your data? Where do you begin?
But in practice, each team creates their own separate data transformations directly from the rawdata. Different data scientists are building different models with totally disconnected datasets. This practice isnt unusual, but it can lead to problems. Theres no easy way to trace issues across the pipeline.
Traditionalists would suggest starting a data stewardship and ownership program, but at a certain scale and pace, these efforts are a weak force that are no match for the expansion taking place.
As you do not want to start your development with uncertainty, you decide to go for the operational rawdata directly. Accessing Operational Data I used to connect to views in transactional databases or APIs offered by operational systems to request the rawdata. Does it sound familiar?
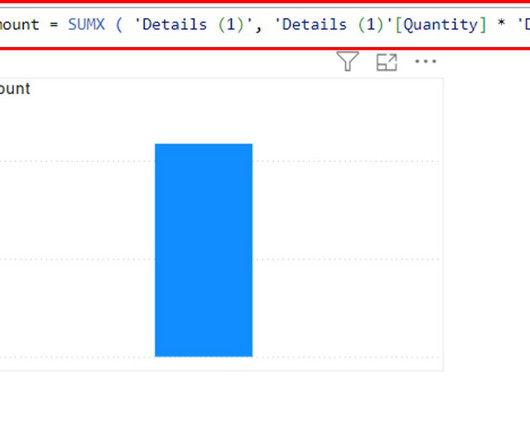
Additionally, it manages sizable datasets without causing Power BI to crash or perform less quickly. The purpose of the Power BI SUMX function was to perform calculations across a table or dataset row by row. Data about Quantity and the cost price of Amount are included in the dataset (1).
When created, Snowflake materializes query results into a persistent table structure that refreshes whenever underlying data changes. These tables provide a centralized location to host both your rawdata and transformed datasets optimized for AI-powered analytics with ThoughtSpot.
Microsoft offers a leading solution for business intelligence (BI) and data visualization through this platform. It empowers users to build dynamic dashboards and reports, transforming rawdata into actionable insights. However, it leans more toward transforming and presenting cleaned data rather than processing rawdatasets.
Read our eBook Validation and Enrichment: Harnessing Insights from RawData In this ebook, we delve into the crucial data validation and enrichment process, uncovering the challenges organizations face and presenting solutions to simplify and enhance these processes. What perspectives and opportunities could you uncover?
Data Engineering at Adyen — "Data engineers at Adyen are responsible for creating high-quality, scalable, reusable and insightful datasets out of large volumes of rawdata" This is a good definition of one of the possible responsibilities of DE. Synthetic data are AI generated data.
In this article, we will be diving into the world of Data Imputation, discussing its importance and techniques, and also learning about Multiple Imputations. What Is Data Imputation? Data imputation is the method of filling in missing or unavailable information in a dataset with other numbers.
We work with organizations around the globe that have diverse needs but can only achieve their objectives with expertly curated data sets containing thousands of different attributes. Enrichment: The Secret to Supercharged AI You’re not just improving accuracy by augmenting your datasets with additional information.
By learning the details of smaller datasets, they better balance task-specific performance and resource efficiency. It is seamlessly integrated across Meta’s platforms, increasing user access to AI insights, and leverages a larger dataset to enhance its capacity to handle complex tasks. What are Small language models?
Unlike streaming data, which needs instant processing, batch data can be processed at scheduled intervals or when resources become available. Splittable in chunks : instead of processing an entire dataset in a single, resource-intensive operation, batch data can be divided into smaller, more manageable segments.
Cloud-Based Solutions: Large datasets may be effectively stored and analysed using cloud platforms. From Information to Insight The difficulty is not gathering data but making sense of it. Tableau, Power BI, and SAS provide user-friendly interfaces and extensive modelling capabilities.
For further steps, you need to load your dataset to Python or switch to a platform specifically focusing on analysis and/or machine learning. Labeling of audio data in Audacity. Source: Towards Data Science. Voice and sound data acquisition. Free data sources. Commercial datasets. Expert datasets.
Read our eBook Validation and Enrichment: Harnessing Insights from RawData In this ebook, we delve into the crucial data validation and enrichment process, uncovering the challenges organizations face and presenting solutions to simplify and enhance these processes.
Data teams can use uniqueness tests to measure their data uniqueness. Uniqueness tests enable data teams to programmatically identify duplicate records to clean and normalize rawdata before entering the production warehouse.
You can’t simply feed the system your whole dataset of emails and expect it to understand what you want from it. It’s called deep because it comprises many interconnected layers — the input layers (or synapses to continue with biological analogies) receive data and send it to hidden layers that perform hefty mathematical computations.
Summary Building clean datasets with reliable and reproducible ingestion pipelines is completely useless if it’s not possible to find them and understand their provenance. The solution to discoverability and tracking of data lineage is to incorporate a metadata repository into your data platform.
In this article, we will be discussing 4 types of d ata Science Projects for resume that can strengthen your skills and enhance your resume: Data Cleaning Exploratory Data Analysis Data Visualization Machine Learning Data Cleaning A data scientist, most likely spend nearly 80% of their time cleaning data.
Once the prototype has been completely deployed, you will have an application that is able to make predictions to classify transactions as fraudulent or not: The data for this is the widely used credit card fraud dataset. Data analysis – create a plan to build the model.
Code implementations for ML pipelines: from rawdata to predictions Photo by Rodion Kutsaiev on Unsplash Real-life machine learning involves a series of tasks to prepare the data before the magic predictions take place. Those are the features and their respective data types: Image 1 —Features and data types.
According to the 2023 Data Integrity Trends and Insights Report , published in partnership between Precisely and Drexel University’s LeBow College of Business, 77% of data and analytics professionals say data-driven decision-making is the top goal of their data programs. That’s where data enrichment comes in.
Data analysis and Interpretation: It helps in analyzing large and complex datasets by extracting meaningful patterns and structures. By identifying and understanding patterns within the data, valuable insights can be gained, leading to better decision-making, and understanding of underlying relationships.
Optimizing queries, improving runtimes, and geospatial data science applications Photo by Tamas Tuzes-Katai on Unsplash Intro: why is a spatial index useful? In doing geospatial data science work, it is very important to think about optimizing the code you are writing. This is where concepts such as spatial indices come in.
Summary The most complicated part of data engineering is the effort involved in making the rawdata fit into the narrative of the business. Random data doesn’t do it — and production data is not safe (or legal) for developers to use. does exactly that. does exactly that.
® , Go, and Python SDKs where an application can use SQL to query rawdata coming from Kafka through an API (but that is a topic for another blog). Let’s now dig a little bit deeper into Kafka and Rockset for a concrete example of how to enable real-time interactive queries on large datasets, starting with Kafka.
rawdata path, column mappings, aggregation function to be used, etc.) We introduced a data standardization step that mapped a raw metric dataset into a standardized dataset that our metric processing logic would understand. We did that by separating the metric’s configuration logic (i.e.
The value of the edge lies in acting at the edge where it has the greatest impact with zero latency before it sends the most valuable data to the cloud for further high-performance processing. Data Collection Using Cloudera Data Platform. STEP 1: Collecting the rawdata.
import polars as pl Then I can do my first CSV import, in the example I load a French railway open dataset about lost and found objects in stations. df = pl.read_csv("lost-objects-stations.csv", sep=";") Then you can use the same code as pandas to select the data (head, ["col"], etc.). seed round.
Linear Algebra Linear Algebra is a mathematical subject that is very useful in data science and machine learning. A dataset is frequently represented as a matrix. Statistics Statistics are at the heart of complex machine learning algorithms in data science, identifying and converting data patterns into actionable evidence.
Simulated dataset that shows what the distribution of play delay may look like. After recreating the dataset, you can plot the raw numbers and perform custom analyses to understand the distribution of the data across test cells. The library also provides helper methods which abstract accessing compressed or rawdata.
Define Data Wrangling The process of data wrangling involves cleaning, structuring, and enriching rawdata to make it more useful for decision-making. Data is discovered, structured, cleaned, enriched, validated, and analyzed. Values significantly out of a dataset’s mean are considered outliers.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content