This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datasets are the repository of information that is required to solve a particular type of problem. Also called data storage areas , they help users to understand the essential insights about the information they represent. Datasets play a crucial role and are at the heart of all Machine Learning models.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
Audio data file formats. Similar to texts and images, audio is unstructureddata meaning that it’s not arranged in tables with connected rows and columns. For further steps, you need to load your dataset to Python or switch to a platform specifically focusing on analysis and/or machine learning. Free data sources.
If we look at history, the data that was generated earlier was primarily structured and small in its outlook. A simple usage of Business Intelligence (BI) would be enough to analyze such datasets. However, as we progressed, data became complicated, more unstructured, or, in most cases, semi-structured.
Linear Algebra Linear Algebra is a mathematical subject that is very useful in data science and machine learning. A dataset is frequently represented as a matrix. Statistics Statistics are at the heart of complex machine learning algorithms in data science, identifying and converting data patterns into actionable evidence.
This field uses several scientific procedures to understand structured, semi-structured, and unstructureddata. It entails using various technologies, including data mining, data transformation, and data cleansing, to examine and analyze that data.
VDK helps you easily perform complex operations, such as data ingestion and processing from different sources, using SQL or Python. You can use VDK to build data lakes and ingest rawdata extracted from different sources, including structured, semi-structured, and unstructureddata.
But this data is not that easy to manage since a lot of the data that we produce today is unstructured. In fact, 95% of organizations acknowledge the need to manage unstructuredrawdata since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses.
Receipt table (later referred to as table_receipts_index): It turns out that all the receipts were manually entered into the system, which creates unstructureddata that is error-prone. This data collection method was chosen because it was simple to deploy, with each employee responsible for their own receipts.
Mathematics / Stastistical Skills While it is possible to become a Data Scientist without a degree, it is necessary to have Mathematical skills to become a Data Scientist. Let us look at some of the areas in Mathematics that are the prerequisites to becoming a Data Scientist.
DL models automatically learn features from rawdata, eliminating the need for explicit feature engineering. Data Types and Dimensionality ML algorithms work well with structured and tabular data, where the number of features is relatively small.
Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making. These data sources serve as the starting point for the pipeline, providing the rawdata that will be ingested, processed, and analyzed.
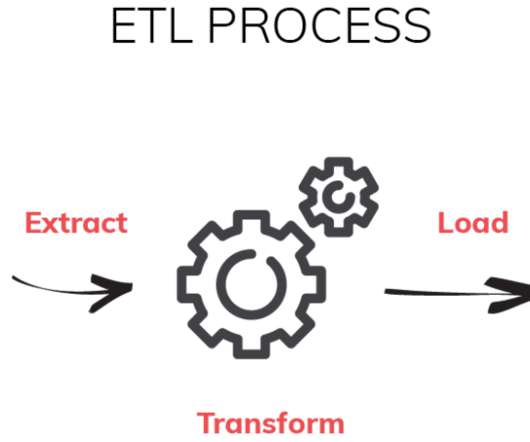
Banks, healthcare systems, and financial reporting often rely on ETL to maintain highly structured, trustworthy data from the start. ELT (Extract, Load, Transform) ELT flips the orderstoring rawdata first and applying transformations later. Data Lakes Data lakes store raw, unstructureddata.
We’ll particularly explore data collection approaches and tools for analytics and machine learning projects. What is data collection? It’s the first and essential stage of data-related activities and projects, including business intelligence , machine learning , and big data analytics.
As you now know the key characteristics, it gets clear that not all data can be referred to as Big Data. What is Big Data analytics? Big Data analytics is the process of finding patterns, trends, and relationships in massive datasets that can’t be discovered with traditional data management techniques and tools.
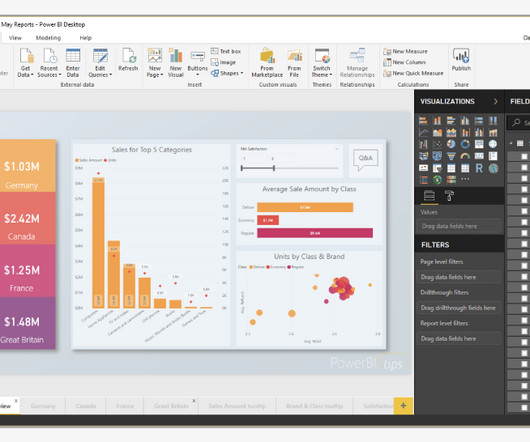
Power BI is a technology-driven business intelligence tool or an array of software services, apps, and connectors to convert unrelated and rawdata into visually immersive, coherent, actionable, and interactive insights and information. Microsoft developed it and combines business analytics, data visualization, and best practices.
More importantly, we will contextualize ELT in the current scenario, where data is perpetually in motion, and the boundaries of innovation are constantly being redrawn. Extract The initial stage of the ELT process is the extraction of data from various source systems. What Is ELT? So, what exactly is ELT?
Cleaning Bad data can derail an entire company, and the foundation of bad data is unclean data. Therefore it’s of immense importance that the data that enters a data warehouse needs to be cleaned. Data can be loaded in batches or can be streamed in near real-time.
A pipeline may include filtering, normalizing, and data consolidation to provide desired data. It can also consist of simple or advanced processes like ETL (Extract, Transform and Load) or handle training datasets in machine learning applications. In most cases, data is synchronized in real-time at scheduled intervals.
Organisations and businesses are flooded with enormous amounts of data in the digital era. Rawdata, however, is frequently disorganised, unstructured, and challenging to work with directly. Data processing analysts can be useful in this situation.
By accommodating various data types, reducing preprocessing overhead, and offering scalability, data lakes have become an essential component of modern data platforms , particularly those serving streaming or machine learning use cases. With strong G2 scores (4.7 Not to mention seamless integration with the Oracle ecosystem.
In today's world, where data rules the roost, data extraction is the key to unlocking its hidden treasures. As someone deeply immersed in the world of data science, I know that rawdata is the lifeblood of innovation, decision-making, and business progress. What is data extraction?
The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. This article explains what a data lake is, its architecture, and diverse use cases. Unstructureddata sources.
Low in Visibility End-users won’t be able to access all the data in the final destination, only the data that was transformed and loaded. First, every transformation performed on the data pushes you further from the rawdata and obscures some of the underlying information. This causes two issues.
The difference here is that warehoused data is in its raw form, with the transformation only performed on-demand following information access. Another benefit is that this approach supports optimizing the data transforming processes all analytical processing evolves.
If you work at a relatively large company, you've seen this cycle happening many times: Analytics team wants to use unstructureddata on their models or analysis. For example, an industrial analytics team wants to use the logs from rawdata.
To reduce development time and increase data reliability, DataOps engineers automate manual processes, such as data extraction and testing. Managing the production of data pipelines. A DataOps engineer provides organizations with access to structured datasets and analytics they will further analyze and derive insights from.
The maximum value of big data can be extracted by integrating the in-memory processing capabilities of SAP HANA (High Performance Analytic Appliance) and the ability of Hadoop to store large unstructureddatasets. “With Big Data, you’re getting into streaming data and Hadoop.
Just before we jump on to a detailed discussion on the key components of the Hadoop Ecosystem and try to understand the differences between them let us have an understanding on what is Hadoop and what is Big Data. What is Big Data and Hadoop? Apache Pig is 10% faster than Apache Hive for filtering 10% of the data.
This blog offers an exclusive glimpse into the daily rituals, challenges, and moments of triumph that punctuate the professional journey of a data scientist. The primary objective of a data scientist is to analyze complex datasets to uncover patterns, trends, and valuable information that can aid in informed decision-making.
Big data enables businesses to get valuable insights into their products or services. Almost every company employs data models and big data technologies to improve its techniques and marketing campaigns. Most leading companies use big data analytical tools to enhance business decisions and increase revenues.
Factors Data Engineer Machine Learning Definition Data engineers create, maintain, and optimize data infrastructure for data. In addition, they are responsible for developing pipelines that turn rawdata into formats that data consumers can use easily. Assess the needs and goals of the business.
feature engineering or feature extraction when useful properties are drawn from rawdata and transformed into a desired form, and. The accuracy of the forecast depends not only on features but also on hyperparameters or internal settings that dictate how exactly your algorithm will learn on a specific dataset.
Ensuring all relevant data inputs are accounted for is crucial for a comprehensive ingestion process. Data Extraction : Begin extraction using methods such as API calls or SQL queries. Batch processing gathers large datasets at scheduled intervals, ideal for operations like end-of-day reports.
With businesses relying heavily on data, the demand for skilled data scientists has skyrocketed. In data science, we use various tools, processes, and algorithms to extract insights from structured and unstructureddata. That's the promise of a career in data science. Implementing machine learning magic.
What is Data Cleaning? Data cleaning, also known as data cleansing, is the essential process of identifying and rectifying errors, inaccuracies, inconsistencies, and imperfections in a dataset. It involves removing or correcting incorrect, corrupted, improperly formatted, duplicate, or incomplete data.
Check out the Data Science course fee to start your journey. Why is Data Science So Important? Data is not useful until it is transformed into valuable information. Mining large datasets containing structured and unstructureddata and identifying hidden patterns to gain actionable insights are two main tasks in data science.
Datasets like Google Local, Amazon product reviews, MovieLens, Goodreads, NES, Librarything are preferable for creating recommendation engines using machine learning models. They have a well-researched collection of data such as ratings, reviews, timestamps, price, category information, customer likes, and dislikes.
A Data Engineer's primary responsibility is the construction and upkeep of a data warehouse. In this role, they would help the Analytics team become ready to leverage both structured and unstructureddata in their model creation processes. They construct pipelines to collect and transform data from many sources.
Data Integration 3.Scalability Specialized Data Analytics 7.Streaming We need to analyze this data and answer a few queries such as which movies were popular etc. To this group, we add a storage account and move the rawdata. Then we create and run an Azure data factory (ADF) pipelines. Scalability 4.Link
Whether you know it or not, this article will help you understand how companies ride the big data wave without merely getting stuck by the massive volume. Go for the best Big Data courses and work on ral-life projects with actual datasets.
Traditional data warehouse platform architecture. Key data warehouse limitations: Inefficiency and high costs of traditional data warehouses in terms of continuously growing data volumes. Inability to handle unstructureddata such as audio, video, text documents, and social media posts. Data lake.
A business generates data daily related to production, sales, marketing , customer feedback, team structure, costs, and other metrics. Sometimes it isn't easy to get a clear picture of the business because of unstructureddata, and data visualization benefits the company by visually structuring the data.
For those looking to start learning in 2024, here is a data science roadmap to follow. What is Data Science? Data science is the study of data to extract knowledge and insights from structured and unstructureddata using scientific methods, processes, and algorithms.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content