This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. These formats are transforming how organizations manage large datasets. Though basic and easy to use, traditional table storage formats struggle to keep up. Why are They Essential?
What’s interesting is that if you look at your operations, you usually perform database operations such as joins, aggregates, filters, etc. But, instead of using a relationaldatabase management system (RDBMS), you use Pandas and Numpy. We are going to perform data analysis on the Stock Market dataset. polars==0.14.31
Unique: Unique datasets are free of redundant or extraneous entries. Consistent: Data is consistently represented in a standard way throughout the dataset. That means having large enough datasets to accurately represent the information in question, including information on all relevant fields.
Apache Hadoop is an open-source framework written in Java for distributed storage and processing of huge datasets. Hadoop was created to deal with huge datasets rather than with a large number of files extremely smaller than the default size of 128 MB. The table below summarizes core differences between two platforms in question.
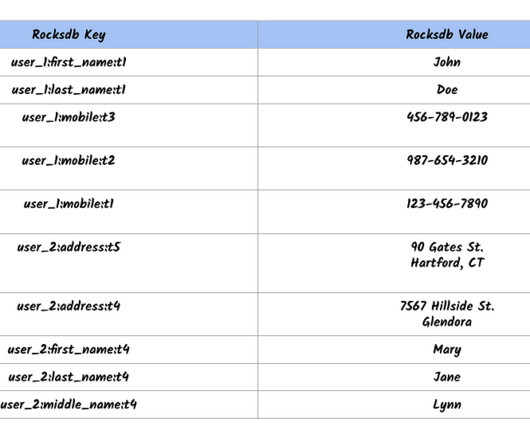
While a simple key value database can be viewed as a persistent hash map, a wide column database can be interpreted as a two dimensional key-value store with a flexible columnar structure. The key difference compared to a relationaldatabase is that the columns can vary from row to row, without a fixed schema.
Then, based on this information from the sample, defect or abnormality the rate for whole dataset is considered. Hypothesis testing is a part of inferential statistics which uses data from a sample to analyze results about whole dataset or population. According to a database model, the organization of data is known as database design.
Dive Into Deep Learning Quality software tools have played an essential part in the rapid advancement of deep learning alongside massive datasets and powerful hardware. SQL (Structured Query Language) is a computer language designed specifically for handling data in database management systems.
Values significantly out of a dataset’s mean are considered outliers. Data mining, report writing, and relationaldatabases are also part of business intelligence, which includes OLAP. Based on a single or more independent variable, a logistic regression model can be used to study datasets with a particular outcome.
With Select Star’s data catalog, a single source of truth for your data is built in minutes, even across thousands of datasets. With Select Star’s data catalog, a single source of truth for your data is built in minutes, even across thousands of datasets. You’ll also get a swag package when you continue on a paid plan.
To illustrate that, let’s take Cloud SQL from the Google Cloud Platform that is a “Fully managed relationaldatabase service for MySQL, PostgreSQL, and SQL Server” It looks like this when you want to create an instance. You can choose your parameters like the region, the version or the number of CPUs.
This serverless data integration service can automatically and quickly discover structured or unstructured enterprise data when stored in data lakes in Amazon S3, data warehouses in Amazon Redshift, and other databases that are a component of the Amazon RelationalDatabase Service.
NoSQL databases are designed for scalability and flexibility, making them well-suited for storing big data. The most popular NoSQL database systems include MongoDB, Cassandra, and HBase. These four fields are at the forefront of big data technology and are essential for understanding and managing large datasets.
This data isn’t just about structured data that resides within relationaldatabases as rows and columns. Big Data analytics is the process of finding patterns, trends, and relationships in massive datasets that can’t be discovered with traditional data management techniques and tools. What is Big Data analytics?
Photo by Shubham Dhage on Unsplash While data normalization holds merit in traditional relationaldatabases, the paradigm shifts when dealing with modern analytics platforms like BigQuery. Also, storage is much cheaper than compute and that means: With pre-joined datasets, you exchange compute for storage resources!
Supports numerous data sources It connects to and fetches data from a variety of data sources using Tableau and supports a wide range of data sources, including local files, spreadsheets, relational and non-relationaldatabases, data warehouses, big data, and on-cloud data. Tableau supports Python machine learning features.
If you have large datasets in a cloud-based project management platform like Hive, you can smoothly migrate them to a relationaldatabase management system (RDBMS), like MySQL. In today’s data-driven world, efficient workflow management and secure storage are essential for the success of any project or organization.
Big Data vs Traditional Data The difference between Big Data vs Traditional Data heavily relies on the tools, plans, processes, and objectives used within, which derive useful insights from the datasets. Let us now take a detailed look into how Big Data differs from Traditional relationaldatabases.
A solid foundation in database management enables professionals to deal with large datasets and interpret intricate data structures. In addition to allowing businesses to make decisions based on data, database specialist skills are essential for ensuring data accuracy and consistency.
Examples MySQL, PostgreSQL, MongoDB Arrays, Linked Lists, Trees, Hash Tables Scaling Challenges Scales well for handling large datasets and complex queries. Flexibility: Offers scalability to manage extensive datasets efficiently. Widely applied in businesses and web development for managing large datasets.
While both deal with large datasets, but when it comes to data warehouse vs big data, they have different focuses and offer distinct advantages. Data warehouses are typically built using traditional relationaldatabase systems, employing techniques like Extract, Transform, Load (ETL) to integrate and organize data.
Even as modern SQL engines evolve to be capable of querying ever larger and more diverse datasets, the essential concepts and fundamental syntax of SQL queries remains largely consistent over time. Educating Data Analysts at Scale. What We Teach.
As a whole, data normalization plays an essential role in business for those who have to deal with large datasets as a part of their daily operations. Now, let’s understand why data normalization is important. Normalization helps keep your data consistent and reliable so that you can make better business decisions with confidence.
In simple terms, it is the accuracy, completeness, and correctness of data stored in a database or in a dataset, providing protection to data consuming applications from partial or unintended state of data while constant transactions are changing the underlying data.
Each dataset and job exists in a unique operational context, with interdependencies that may seem simple…until they multiply. By studying queries that have been executed, they create a rough mapping of input/output datasets. But what if your data isn’t in a relationaldatabase? Let’s call them query log analysis systems.
What’s forgotten is that the rise of this paradigm was driven by a particular type of human-facing application in which a user looks at a UI and initiates actions that are translated into database queries. Event streams present a very different paradigm for thinking about data from traditional databases.
However, it’s only by combining these with rich proprietary datasets and operational data streams that organizations can find true differentiation. The author writes an overview of the performance implication of disaggregated systems compared to traditional monolithic databases.
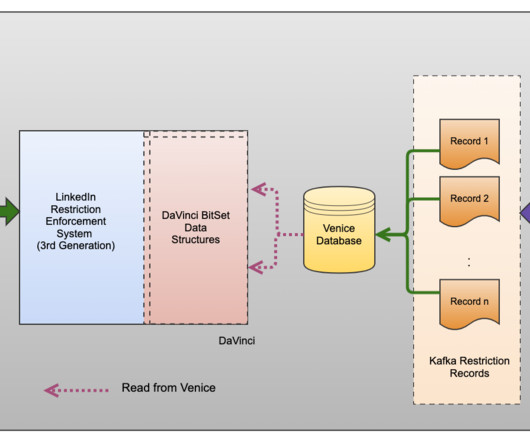
At the heart of this system was a reliance on a relationaldatabase, Oracle, which served as the repository for all member restrictions data. Figure 2: Relationaldatabase schema We adopted a pragmatic and scalable approach by distributing member restrictions across different Oracle tables.
As a whole, data normalization plays an essential role in business for those who have to deal with large datasets as a part of their daily operations. Now, let’s understand why data normalization is important. Normalization helps keep your data consistent and reliable so that you can make better business decisions with confidence.
A simple usage of Business Intelligence (BI) would be enough to analyze such datasets. They analyze datasets to find trends and patterns and report the results using visualization tools. Data engineers can also create datasets using Python. It is an outcome of coordination between different statistical tools.
Structured data can be defined as data that can be stored in relationaldatabases, and unstructured data as everything else. It aims to protect AI stakeholders from the effects of biased, compromised or skewed datasets. Here we mostly focus on structured vs unstructured data. Data scrutiny.
With the help of Hadoop big data tools, organizations can make decisions that will be based on the analysis of multiple datasets and variables, and not just small samples or anecdotal incidents. HIVE Hive is an open-source data warehousing Hadoop tool that helps manage huge dataset files. Why are Hadoop Big Data Tools Needed?
RelationalDatabases – The fundamental concept behind databases, namely MySQL, Oracle Express Edition, and MS-SQL that uses SQL, is that they are all RelationalDatabase Management Systems that make use of relations (generally referred to as tables) for storing data.
Organizations are collecting more and more data, so the need to manage large datasets in an effective way is becoming critical. Power BI incremental refresh lets you load only the new data or modified rows into an already published dataset instead of replacing all the existing records with a full schedule.
Data Science is all about dealing with huge datasets, finding trends and patterns, analysis of data, number crunching, and these are derived from the field of Mathematics and Statistics. Linear Algebra Every observation in a dataset is modeled as a point in a high-dimensional vector-space.
Setting Up a RelationalDatabase with Amazon RDS Difficulty Level: Intermediate AWS cloud practitioner applications can create relationaldatabases using the Amazon RelationalDatabase Service (RDS).
In this article, I will examine the principal distinctions and similarities between SQL vs SQLite databases. Relationaldatabases can be interacted with using this computer language. Data kept in relationaldatabases is managed using the programming language SQL. What is SQL? What is SQLite? How Are They Similar?
Big data operations require specialized tools and techniques since a relationaldatabase cannot manage such a large amount of data. MapReduce is a Hadoop framework used for processing large datasets. Another name for it is a programming model that enables us to process big datasets across computer clusters.
Batch processing gathers large datasets at scheduled intervals, ideal for operations like end-of-day reports. Data Extraction with Apache Hadoop and Apache Sqoop : Hadoop’s distributed file system (HDFS) stores large data volumes; Sqoop transfers data between Hadoop and relationaldatabases.
Database Software- Other NoSQL: NoSQL databases cover a variety of database software that differs from typical relationaldatabases. Key-value stores, columnar stores, graph-based databases, and wide-column stores are common classifications for NoSQL databases. Columnar Database (e.g.-
Data Warehouses: These are optimized for storing structured data, often organized in relationaldatabases. It supports SQL-based queries for precise data retrieval, batch analytics for processing large datasets, and reporting dashboards for visualizing key metrics and trends.
Python is the best language for managing massive datasets and effectively performing complex algorithms because of its syntax and variety of packages. SQL Structured Query Language, or SQL, is used to manage and work with relationaldatabases. Data scientists use SQL to query, update, and manipulate data.
Amazon RDS (RelationalDatabase Service) Another famous AWS web application is the Amazon RDS, a relationaldatabase service managed and simple to install, operate, and scale databases on the cloud. Lambda usage includes real-time data processing, communication with IoT devices, and execution of automated tasks.
Data can arrive late, it can be out of order, it can be incomplete or you might have a scenario where you need to enrich and extend your datasets with additional information for them to be complete. Rockset is fully mutable Rockset is a fully mutable database. In either case, the ability to change your data is very important.
Apache Kafka ® and its surrounding ecosystem, which includes Kafka Connect, Kafka Streams, and KSQL, have become the technology of choice for integrating and processing these kinds of datasets. License costs and modification of the existing hardware are required to enable OPC UA. No license costs or hardware modifications are required.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content