This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The machine learning algorithms heavily rely on data that we feed to them. The quality of data we feed to the algorithms […] The post Practicing Machine Learning with Imbalanced Dataset appeared first on Analytics Vidhya.
Yet organizations struggle to pave a path to production due to an AI and data mismatch. LLMs excel at unstructured data, but many organizations lack mature preparation practices for this type of data; meanwhile, structureddata is better managed, but challenges remain in enabling LLMs to understand rows and columns.
And over the last 24 months, an entire industry has evolved to service that very vision—including companies like Tonic that generate synthetic structureddata and Gretel that creates compliant data for regulated industries like finance and healthcare. But is synthetic data a long-term solution? Probably not.
In the mid-2000s, Hadoop emerged as a groundbreaking solution for processing massive datasets. It promised to address key pain points: Scaling: Handling ever-increasing data volumes. Speed: Accelerating data insights. Like Hadoop, it aims to tackle scalability, cost, speed, and data silos.
And over the last 24 months, an entire industry has evolved to service that very visionincluding companies like Tonic that generate synthetic structureddata and Gretel that creates compliant data for regulated industries like finance and healthcare. But is synthetic data a long-term solution? Probablynot.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Let’s examine a few.
When created, Snowflake materializes query results into a persistent table structure that refreshes whenever underlying data changes. These tables provide a centralized location to host both your raw data and transformed datasets optimized for AI-powered analytics with ThoughtSpot.
Open Context is an open access data publishing service for archaeology. It started because we need better ways of dissminating structureddata and digital media than is possible with conventional articles, books and reports. What are your protocols for determining which data sets you will work with?
Then, based on this information from the sample, defect or abnormality the rate for whole dataset is considered. This process of inferring the information from sample data is known as ‘inferential statistics.’ A database is a structureddata collection that is stored and accessed electronically.
Types of Machine Learning: Machine Learning can broadly be classified into three types: Supervised Learning: If the available dataset has predefined features and labels, on which the machine learning models are trained, then the type of learning is known as Supervised Machine Learning. Example: Let us look at the structure of a decision tree.
To store and process even only a fraction of this amount of data, we need Big Data frameworks as traditional Databases would not be able to store so much data nor traditional processing systems would be able to process this data quickly. collect(): Return all the elements of the dataset as an array at the driver program.
MoEs necessitate less compute for pre-training compared to dense models, facilitating the scaling of model and dataset size within similar computational budgets. Try Astro Free → Hugging Face: Mixture of Experts Explained The mixture of Experts (MoEs) are transformer models efficiently gaining traction in the open AI community.
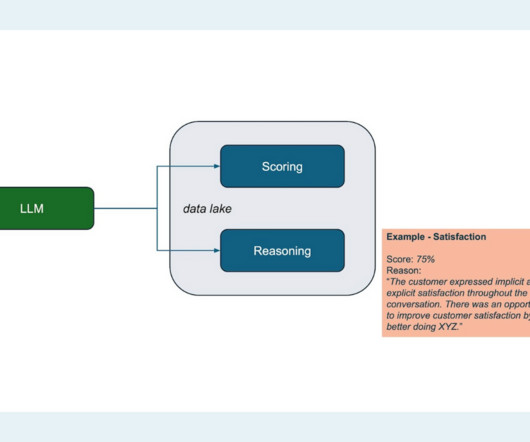
Not only can the LLM turn unstructured data into structureddata, but it can also give a summary of exactly what happened – and it can do so dynamically, so new context is always added and taken into account. This new dataset opened the door for even more machine learning analysis on newly structureddata.
The field names should exactly match for Bulldozer to convert the structureddata entries into the key-value pairs. Users can use the protobuf schema KeyMessage and ValueMessage to deserialize data from Key-Value DAL as well. Each execution moves the latest view of the data warehouse into a Key-Value DAL namespace.
Resume Parser Language: Python Data set: text file Source code: keras-english-resume-parser-and-analyzer An AI-powered tool called a resume parser pulls pertinent data from resumes or CVs and turns it into structureddata. Take online classes: Work with real-world datasets to put your knowledge into practice.
Moreover, these models struggle with domain shift, where the statistical distribution of training data varies from that of new data (e.g., Training the Similarity Function A big-named dataset like ImageNet is used to teach the model how to understand similarities in a supervised way.
Apache Hadoop is an open-source framework written in Java for distributed storage and processing of huge datasets. The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. A powerful Big Data tool, Apache Hadoop alone is far from being almighty.
The following are key attributes of our platform that set Cloudera apart: Unlock the Value of Data While Accelerating Analytics and AI The data lakehouse revolutionizes the ability to unlock the power of data. Increased confidence in data results in trusted AI. Unlike software, ML models need continuous tuning.
In terms of representation, data can be broadly classified into two types: structured and unstructured. Structureddata can be defined as data that can be stored in relational databases, and unstructured data as everything else. Data scrutiny. Data fairness is one of the dimensions of ethical AI.
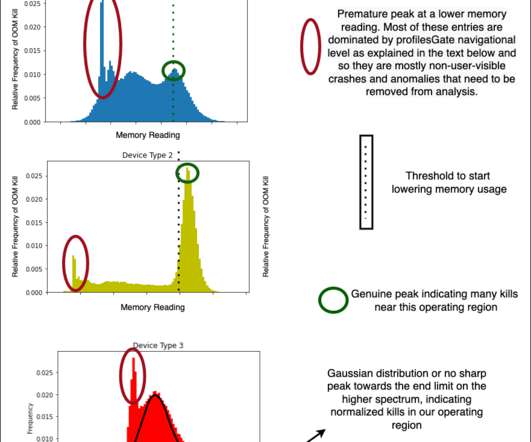
This is done by first elaborating on the dataset curation stage?—?specially Since memory management is not something one usually associates with classification problems, this blog focuses on formulating the problem as an ML problem and the data engineering that goes along with it. The dataset will thus be very biased/skewed.
Interactive exploration : Users can build dashboards that support real-time interaction and deep data exploration. AI-enhanced analytics : Built-in machine learning capabilities help uncover hidden patterns and trends within datasets. Next, we’ll examine the key distinctions between Power BI and Microsoft Fabric.
(Senior Solutions Architect at AWS) Learn about: Efficient methods to feed unstructured data into Amazon Bedrock without intermediary services like S3. Techniques for turning text data and documents into vector embeddings and structureddata. link] All rights reserved ProtoGrowth Inc, India.
Big data and data mining are neighboring fields of study that analyze data and obtain actionable insights from expansive information sources. Big data encompasses a lot of unstructured and structureddata originating from diverse sources such as social media and online transactions.
paintings, songs, code) Historical data relevant to the prediction task (e.g., Generative AI leverages the power of deep learning to build complex statistical models that process and mimic the structures present in different types of data.
TDWI’s 2024 Data Quality Maturity Model What do organizations at the “Established” level look like? Organizations are adept at managing the quality of structureddata, but management of unstructured and semi-structureddata is less mature. • Invest in training and culture.
In an ETL-based architecture, data is first extracted from source systems, then transformed into a structured format, and finally loaded into data stores, typically data warehouses. This method is advantageous when dealing with structureddata that requires pre-processing before storage.
In the modern data-driven landscape, organizations continuously explore avenues to derive meaningful insights from the immense volume of information available. Two popular approaches that have emerged in recent years are data warehouse and big data. Data warehousing offers several advantages.
These skills are essential to collect, clean, analyze, process and manage large amounts of data to find trends and patterns in the dataset. The dataset can be either structured or unstructured or both. In this article, we will look at some of the top Data Science job roles that are in demand in 2024.
Big Data vs Small Data: Volume Big Data refers to large volumes of data, typically in the order of terabytes or petabytes. It involves processing and analyzing massive datasets that cannot be managed with traditional data processing techniques.
Data scientists are likely to use a variety of different tools to move through their processes. It could be a homespun version of PostgreSQL on their local machine for exploring structureddata sets; to visualize, they could be writing code or using a BI tool like Tableau or PowerBI.
The motivation for Machine Unlearning is critical from the privacy perspective and for model correction, fixing outdated knowledge, and access revocation of the training dataset. link] Daniel Beach: Delta Lake - Map and Array data types Having a well-structureddata model is always great, but we often handle semi-structureddata.
In modern enterprises, the exponential growth of data means organizational knowledge is distributed across multiple formats, ranging from structureddata stores such as data warehouses to multi-format data stores like data lakes.
It established a data governance framework within its enterprise data lake. Powered and supported by Cloudera, this framework brings together disparate data sources, combining internal data with public data, and structureddata with unstructured data.
Lesson 5: Splitting tasks horizontally reduces runtime Lets say we have two tasks we want to perform (pink and blue) on a large dataset. With that expansion comes new challenges and new learning opportunities when it comes to GenAI development. This workflow creates a good balance between speed, cost, and quality of results.
Lesson 5: Splitting tasks horizontally reduces runtime Lets say we have two tasks we want to perform (pink and blue) on a large dataset. With that expansion comes new challenges and new learning opportunities when it comes to GenAI development. This workflow creates a good balance between speed, cost, and quality of results.
However, in order for them to truly excel at specific tasks, like code generation or language translation for rare dialects, they need to be tuned for the task with a more focused and specialized dataset.
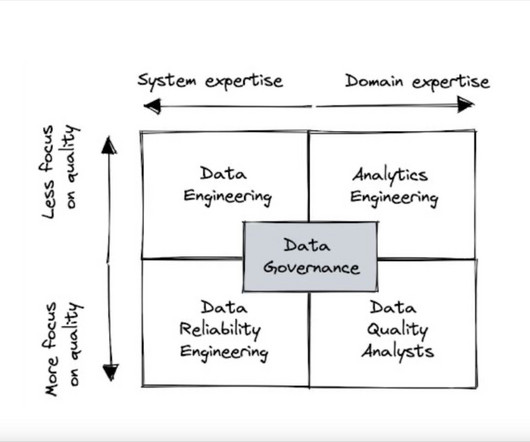
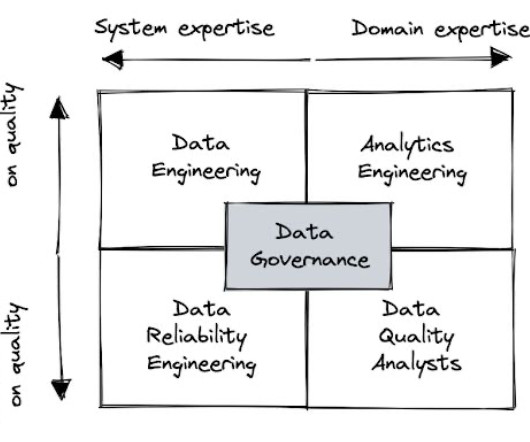
Now, let’s take a closer look at the strengths and weaknesses of the most popular data quality team structures. Data engineering Having the data engineering team lead the response to data quality is by far the most common pattern. It is deployed by about half of all organizations that use a modern data stack.
Now, let’s take a closer look at the strengths and weaknesses of the most popular data quality team structures. Data engineering Photo by Luke Chesser on Unsplash Having the data engineering team lead the response to data quality is by far the most common pattern.
We index only top-tier tables, promoting the use of these higher-quality datasets. I strongly believe the concept of Data Product will play a bigger role in data engineering. Spotify shares some of the critical triggers in an organization that leads to build data platform.
Parameter Data Mining Business Intelligence (BI) Definition The process of uncovering patterns, relationships, and insights from extensive datasets. Process of analyzing, collecting, and presenting data to support decision-making. Focus Exploration and discovery of hidden patterns and trends in data.
Determine what data you’ll need Once you’ve determined the use case, brainstorm and dig deeper into what your end goals are and what you need to know to get there. For example, will you need structureddata, unstructured, or a combination? sample datasets: are data samples available for download and evaluation?
Data storing and processing is nothing new; organizations have been doing it for a few decades to reap valuable insights. Compared to that, Big Data is a much more recently derived term. So, what exactly is the difference between Traditional Data and Big Data? This is a good approach as it allows less space for error.
A single car connected to the Internet with a telematics device plugged in generates and transmits 25 gigabytes of data hourly at a near-constant velocity. And most of this data has to be handled in real-time or near real-time. Variety is the vector showing the diversity of Big Data. What is Big Data analytics?
In summary, data extraction is a fundamental step in data-driven decision-making and analytics, enabling the exploration and utilization of valuable insights within an organization's data ecosystem. What is the purpose of extracting data? The process of discovering patterns, trends, and insights within large datasets.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content