This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Small data is the future of AI (Tomasz) 7. The lines are blurring for analysts and data engineers (Barr) 8. Synthetic data matters—but it comes at a cost (Tomasz) 9. The unstructureddata stack will emerge (Barr) 10. But is synthetic data a long-term solution? Probably not. All that is about to change.
Agents need to access an organization's ever-growing structured and unstructureddata to be effective and reliable. As data connections expand, managing access controls and efficiently retrieving accurate informationwhile maintaining strict privacy protocolsbecomes increasingly complex.
Here we mostly focus on structured vs unstructureddata. In terms of representation, data can be broadly classified into two types: structured and unstructured. Structureddata can be defined as data that can be stored in relational databases, and unstructureddata as everything else.
And over the last 24 months, an entire industry has evolved to service that very visionincluding companies like Tonic that generate synthetic structureddata and Gretel that creates compliant data for regulated industries like finance and healthcare. But is synthetic data a long-term solution? Probablynot.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Let’s examine a few.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
MoEs necessitate less compute for pre-training compared to dense models, facilitating the scaling of model and dataset size within similar computational budgets. link] QuantumBlack: Solving data quality for gen AI applications Unstructureddata processing is a top priority for enterprises that want to harness the power of GenAI.
In the mid-2000s, Hadoop emerged as a groundbreaking solution for processing massive datasets. It promised to address key pain points: Scaling: Handling ever-increasing data volumes. Speed: Accelerating data insights. Like Hadoop, it aims to tackle scalability, cost, speed, and data silos.
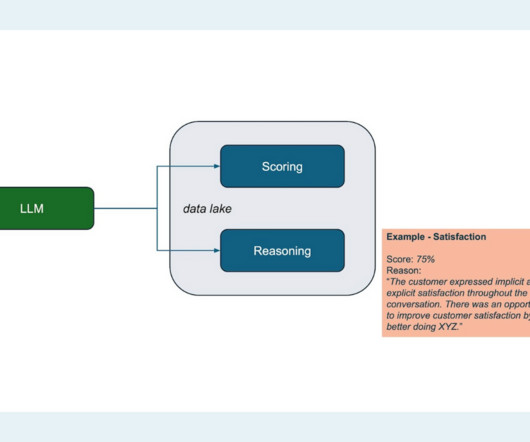
We recently spoke with Killian Farrell , Principal Data Scientist at insurance startup AssuranceIQ to learn how his team built an LLM-based product to structureunstructureddata and score customer conversations for developing sales and customer support teams. Read on to find out what they did, and what they learned!
[link] Sponsored: 7/25 Amazon Bedrock Data Integration Tech Talk Streamline & scale data integration to and from Amazon Bedrock for generative AI applications. Senior Solutions Architect at AWS) Learn about: Efficient methods to feed unstructureddata into Amazon Bedrock without intermediary services like S3.
We scored the highest in hybrid, intercloud, and multi-cloud capabilities because we are the only vendor in the market with a true hybrid data platform that can run on any cloud including private cloud to deliver a seamless, unified experience for all data, wherever it lies. Increased confidence in data results in trusted AI.
paintings, songs, code) Historical data relevant to the prediction task (e.g., Generative AI leverages the power of deep learning to build complex statistical models that process and mimic the structures present in different types of data.
Resume Parser Language: Python Data set: text file Source code: keras-english-resume-parser-and-analyzer An AI-powered tool called a resume parser pulls pertinent data from resumes or CVs and turns it into structureddata. Take online classes: Work with real-world datasets to put your knowledge into practice.
It established a data governance framework within its enterprise data lake. Powered and supported by Cloudera, this framework brings together disparate data sources, combining internal data with public data, and structureddata with unstructureddata.
We also integrate GenAI into the Monte Carlo product itself to make the lives of data teams easier through AI-powered monitor recommendations , fixes with AI, and soon, Gen-AI powered root cause analysis (stay tuned for more on that soon). This workflow creates a good balance between speed, cost, and quality of results.
We also integrate GenAI into the Monte Carlo product itself to make the lives of data teams easier through AI-powered monitor recommendations , fixes with AI, and soon, Gen-AI powered root cause analysis (stay tuned for more on that soon). This workflow creates a good balance between speed, cost, and quality of results.
In the modern data-driven landscape, organizations continuously explore avenues to derive meaningful insights from the immense volume of information available. Two popular approaches that have emerged in recent years are data warehouse and big data. Data warehousing offers several advantages.
Apache Hadoop is an open-source framework written in Java for distributed storage and processing of huge datasets. The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. A powerful Big Data tool, Apache Hadoop alone is far from being almighty.
Big data and data mining are neighboring fields of study that analyze data and obtain actionable insights from expansive information sources. Big data encompasses a lot of unstructured and structureddata originating from diverse sources such as social media and online transactions.
In an ETL-based architecture, data is first extracted from source systems, then transformed into a structured format, and finally loaded into data stores, typically data warehouses. This method is advantageous when dealing with structureddata that requires pre-processing before storage.
[link] Matt Turck: Full Steam Ahead: The 2024 MAD (Machine Learning, AI & Data) Landscape Coninue the week of insights into the world of data & AI landscape, the 2024 MAD landscape is out. We index only top-tier tables, promoting the use of these higher-quality datasets.
Table of Contents What Does an AI Data Quality Analyst Do? Essential Skills for an AI Data Quality Analyst There are several important skills an AI Data Quality Analyst needs to know in order to successfully ensure and maintain accurate, reliable AI models. Machine Learning Basics : Understanding how data impacts model training.
These skills are essential to collect, clean, analyze, process and manage large amounts of data to find trends and patterns in the dataset. The dataset can be either structured or unstructured or both. In this article, we will look at some of the top Data Science job roles that are in demand in 2024.
Mathematics / Stastistical Skills While it is possible to become a Data Scientist without a degree, it is necessary to have Mathematical skills to become a Data Scientist. Let us look at some of the areas in Mathematics that are the prerequisites to becoming a Data Scientist.
We’ll particularly explore data collection approaches and tools for analytics and machine learning projects. What is data collection? It’s the first and essential stage of data-related activities and projects, including business intelligence , machine learning , and big data analytics.
However, to succeed, AI requires a foundation of reliable and structureddata. Modern data engineering can help with this. It creates the systems and processes needed to gather, clean, transfer, and prepare data for AI models. Without it, AI technologies wouldn’t have access to high-quality data.
A single car connected to the Internet with a telematics device plugged in generates and transmits 25 gigabytes of data hourly at a near-constant velocity. And most of this data has to be handled in real-time or near real-time. Variety is the vector showing the diversity of Big Data. What is Big Data analytics?
If we look at history, the data that was generated earlier was primarily structured and small in its outlook. A simple usage of Business Intelligence (BI) would be enough to analyze such datasets. However, as we progressed, data became complicated, more unstructured, or, in most cases, semi-structured.
In the present-day world, almost all industries are generating humongous amounts of data, which are highly crucial for the future decisions that an organization has to make. This massive amount of data is referred to as “big data,” which comprises large amounts of data, including structured and unstructureddata that has to be processed.
Data Types and Dimensionality ML algorithms work well with structured and tabular data, where the number of features is relatively small. DL models excel at handling unstructureddata such as images, audio, and text, where the data has a large number of features or high dimensionality.
In summary, data extraction is a fundamental step in data-driven decision-making and analytics, enabling the exploration and utilization of valuable insights within an organization's data ecosystem. What is the purpose of extracting data? The process of discovering patterns, trends, and insights within large datasets.
Data storing and processing is nothing new; organizations have been doing it for a few decades to reap valuable insights. Compared to that, Big Data is a much more recently derived term. So, what exactly is the difference between Traditional Data and Big Data? This is a good approach as it allows less space for error.
This allows machines to extract value even from unstructureddata. Healthcare organizations generate a lot of text data. Some of it is structured , or organized into specific fields of an EHR. Unstructureddata is unavoidable, yet extremely valuable. The many healthcare factors hidden in unstructureddata.
Big data has revolutionized the world of data science altogether. With the help of big data analytics, we can gain insights from large datasets and reveal previously concealed patterns, trends, and correlations. Learn more about the 4 Vs of big data with examples by going for the Big Data certification online course.
Data can be loaded using a loading wizard, cloud storage like S3, programmatically via REST API, third-party integrators like Hevo, Fivetran, etc. Data can be loaded in batches or can be streamed in near real-time. Structured, semi-structured, and unstructureddata can be loaded.
Using easy-to-define policies, Replication Manager solves one of the biggest barriers for the customers in their cloud adoption journey by allowing them to move both tables/structureddata and files/unstructureddata to the CDP cloud of their choice easily. Specification of access conditions for specific users and groups.
Generally data to be stored in the database is categorized into 3 types namely StructuredData, Semi StructuredData and UnstructuredData. We generally refer to UnstructuredData as “Big Data” and the framework that is used for processing Big Data is popularly known as Hadoop.
MongoDB is a NoSQL database that’s been making rounds in the data science community. MongoDB’s unique architecture and features have secured it a place uniquely in data scientists’ toolboxes globally. Let us see where MongoDB for Data Science can help you. js: To create interactive and customizable charts, D3.js
The datasets are usually present in Hadoop Distributed File Systems and other databases integrated with the platform. Hive is built on top of Hadoop and provides the measures to read, write, and manage the data. Apache Spark , on the other hand, is an analytics framework to process high-volume datasets.
This fast, serverless, highly scalable, and cost-effective multi-cloud data warehouse has built-in machine learning, business intelligence, and geospatial analysis capabilities for querying massive amounts of structured and semi-structureddata. BigQuery aims to provide fast queries on massive datasets.
Big data enables businesses to get valuable insights into their products or services. Almost every company employs data models and big data technologies to improve its techniques and marketing campaigns. Most leading companies use big data analytical tools to enhance business decisions and increase revenues.
Integration with External Data : LangChain lets LLMs talk to APIs, databases, and other data sources. This lets them do things like get real-time information or process datasets that are specific to a topic. Databases Facilitates storage and retrieval of structureddata. Some important reasons are: 1.
Large commercial banks like JPMorgan have millions of customers but can now operate effectively-thanks to big data analytics leveraged on increasing number of unstructured and structureddata sets using the open source framework - Hadoop. JP Morgan has massive amounts of data on what its customers spend and earn.
Data sources can be broadly classified into three categories. Structureddata sources. These are the most organized forms of data, often originating from relational databases and tables where the structure is clearly defined. Semi-structureddata sources. Unstructureddata sources.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content