This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We all have our habits and as programmers, libraries and frameworks are definitely a part of the group. In this blog post I'll share with you a list of Java and Scala classes I use almost every time in data engineering projects. The part for Python will follow next week!
Riccardo is a proud alumnus of Rock the JVM, now a senior engineer working on critical systems written in Java, Scala and Kotlin. Version 19 of Java came at the end of 2022, bringing us a lot of exciting stuff. First, we need to use a version of Java that is at least 19. Another tour de force by Riccardo Cardin.
Project Structure We will use Scala 3.3.0, values :+ Url ( "url1" )) assertEquals ( obtained , expected ) } } Let’s run tests in SBT: sbt:loadbalancer> test [ info] compiling 1 Scala source to ~/loadbalancer/target/scala-3.3.0/test-classes. and several monumental libraries to complete our project. currentOpt. currentOpt.
Java, as the language of digital technology, is one of the most popular and robust of all software programming languages. Java, like Python or JavaScript, is a coding language that is highly in demand. Java, like Python or JavaScript, is a coding language that is highly in demand. Who is a Java Full Stack Developer?
In this article, we will first understand how to implement UDP with Java NIO and gradually transition to Fs2’s io library which provides binding for UDP networking. Setting Up Let’s create a new Scala 3 project and add the following to your build.sbt file. val scala3Version = "3.3.1" lazy val root = project. in ( file ( "." )).
CDE supports Scala, Java, and Python jobs. Some of the key entities exposed by the API: Jobs are the definition of something that CDE can run, usually composed of the application type, main program, and associated configuration. For example, a Java program running Spark with specific configurations.
Previous posts have looked at Algebraic Data Types with Java Variance, Phantom and Existential types in Java and Scala Intersection and Union Types with Java and Scala One of the difficult things for modern programming languages to get right is around providing flexibility when it comes to expressing complex relationships.
Java 8 was released just the year before, adding the beloved lambdas and streams functionality. So why did we end up picking Java as our backend development stack? Remember how Twitter had to re-platform from Ruby to Java to support its growth? Definitely not an enticing prospect, so our choice was geared towards the long run.
Following is the authentic one-liner definition. One would find multiple definitions when you search the term Apache Spark. One would find the keywords ‘Fast’ and/or ‘In-memory’ in all the definitions. It’s also called a Parallel Data processing Engine in a few definitions.
Antonio is an alumnus of Rock the JVM, now a senior Scala developer with his own contributions to Scala libraries and junior devs under his mentorship. Which brings us to this article: Antonio originally started from my Sudoku backtracking article and built a Scala CLI tutorial for the juniors he’s mentoring.
I am going to explain the main points of it by drawing a parallel to the Java implementation. setStartClosed :: i -> a -> i Read the signatures as: If i is a price and a an integer (as the Java interface), so this is a function that receives a Price, an Integer, and returns a Price. Math definition: (f (g x) = (f .
For the JDK, we’ll do great with a long-term support Java version. Scala or Java), this naming convention is probably second nature to you. The syntax is quite similar to many other languages (identical to Scala for example). Types are the same as regular Java types but capitalized. Nothing fancy.
The application is written in Scala and using a Java High Level REST Client, which got deprecated in Elasticsearch 7.15.0 and replaced by ElasticSearch Java API client , so first of all, we had to update the codebase to use the new client. However: It’s in Java. x also represented a choice. Both had their pros and cons.
Why do data scientists prefer Python over Java? Java vs Python for Data Science- Which is better? Which has a better future: Python or Java in 2021? This blog aims to answer all questions on how Java vs Python compare for data science and which should be the programming language of your choice for doing data science in 2021.
Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Can you share your definition of "data discovery" and the technical/social/process components that are required to make it viable?
This article is for aspiring Scala developers. As the Scala ecosystem matures and evolves, this is the best time to become a Scala developer, and in this piece you will learn the essential tools that you should master to be a good Scala software engineer. Read this article to understand what you need to work with Scala.
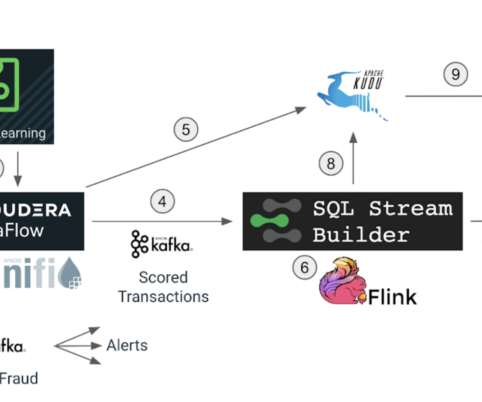
In this blog we will explore how we can use Apache Flink to get insights from data at a lightning-fast speed, and we will use Cloudera SQL Stream Builder GUI to easily create streaming jobs using only SQL language (no Java/Scala coding required). It provides flexible and expressive APIs for Java and Scala. Use case recap.
The backend of Quala is called “tinbox” and is written in Scala , using many type-intensive libraries such as Shapeless , Circe , Grafter , and http4s/rho. One important design goal behind these libraries is to reduce boilerplate by letting the Scala compiler generate as much ceremony code as possible. versus Hydra. compiler is used!
Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Can you start by giving your definition of what MDM is and the scope of activities/functions that it includes?
Play Framework “makes it easy to build web applications with Java & Scala”, as it is stated on their site, and it’s true. In this article we will try to develop a basic skeleton for a REST API using Play and Scala. PlayScala plugin defines default settings for Scala-based applications. import Keys._
This led us towards choosing a format that supports defining a schema in a programming language agnostic Interface Definition Language (IDL) which could then propagate the schema across to all the applications that need to work on that data. Avro was an intriguing option, particularly because of Confluent’s support for this on Kafka.
It’s a common conundrum, what you definitely don’t want to have is more scientists than engineers, because that would mean the former are doing the engineering work. Data engineers are well-versed in Java, Scala, and C++, since these languages are often used in data architecture frameworks such as Hadoop, Apache Spark, and Kafka.
DE supports Scala, Java, and Python jobs. Some of the key entities exposed by the API: Jobs are the definition of something that DE can run. For a data engineer that has already built their Spark code on their laptop, we have made deployment of jobs one click away. A job run is an execution of a job.
132 - kotlin context receivers.mp4 We’ll use nothing more than the Kotlin standard library this time on top of Java 19. Moreover, if you have a Scala or Haskell background, you might notice some interesting similarities with the Type Classes. In Scala 2, we have the implicit classes, and in Scala 3, we have given classes.
According to the Wikipedia definition, A programming language is a notation for writing programs, which are specifications of a computation or algorithm ("Programming language"). Python, like Java, supports Memory management and Object-Oriented Capability. This helped Java spread its popularity faster.
In part two we will explore how we can run real-time streaming analytics using Apache Flink, and we will use Cloudera SQL Stream Builder GUI to easily create streaming jobs using only SQL language (no Java/Scala coding required). You can simply connect to the CDF console, upload the flow definition, and execute it. The use case.
Read More: Data Automation Engineer: Skills, Workflow, and Business Impact Python for Data Engineering Versus SQL, Java, and Scala When diving into the domain of data engineering, understanding the strengths and weaknesses of your chosen programming language is essential. Statically typed, requiring type definition upfront.
The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. Though Kafka is not the only option available in the market, it definitely stands out from other brokers and deserves special attention. In former times, Kafka worked with Java only.
From the definition as per the official website , PyTorch is an open-source machine learning framework that accelerates the path from research prototyping to production deployment. As per the definition from the official website , TensorFlow is an end-to-end open-source platform for machine learning. What is PyTorch ?
But instead of the spoon, there's Scala. Let me deconstruct this workshop title for you: The “type level” part is implying that it’s concerned with operating on the types of values used by computations of your Scala programs, in opposition to the regular value level meaning.
As per Apache, “ Apache Spark is a unified analytics engine for large-scale data processing ” Spark is a cluster computing framework, somewhat similar to MapReduce but has a lot more capabilities, features, speed and provides APIs for developers in many languages like Scala, Python, Java and R.
Factors Data Engineer Machine Learning Definition Data engineers create, maintain, and optimize data infrastructure for data. Languages Python, SQL, Java, Scala R, C++, Java Script, and Python Tools Kafka, Tableau, Snowflake, etc. However, there are significant differences listed in the table.
Have experience with programming languages Having programming knowledge is more of an option than a necessity but it’s definitely a huge plus. Some good options are Python (because of its flexibility and being able to handle many data types), as well as Java, Scala, and Go.
Scala developers have lots of options when it comes to doing Dependency Injection (or DI). The usual Java libraries can be used, like Spring , or Guice for Play developers. But Scala being Scala, there are other options. Back to requirements What are the basic things we can expect from DI? sendFor ( order. send ( order.
With this change we are doubling down on the support of Kotlin as the 3rd JVM language next to Java and Scala. Kotlin allows writing more succinct code with fewer pitfalls compared to Java and comes with a lot of useful features and libraries (e.g. Recently , we moved Kotlin from TRIAL to ADOPT.
Apache Spark Streaming Use Cases Spark Streaming Architecture: Discretized Streams Spark Streaming Example in Java Spark Streaming vs. Structured Streaming Spark Streaming Structured Streaming What is Kafka Streaming? The Java API contains several convenience classes that help define DStream transformations, as we will see along the way.
Apache Hadoop is an open-source Java-based framework that relies on parallel processing and distributed storage for analyzing massive datasets. Yet, its pool of supporters definitely stands out if compared with other Big Data platforms. IBM Big Data Hadoop Course also comes with free Java and Linux courses. Definitely, not.
A good example is DTOs generated from a protocol buffer, an Avro, or a Swagger (OpenAPI) definition. Other languages supporting type classes, such as Scala and Haskell, implement some form of automatic discovery. Scala, for example, has an implicit resolution. required ( "userId" ), amount. set ( JavaLanguageVersion.
Furthermore, the administrator is involved in the implementation and definition of policies for cloud-based systems so that clients may quickly communicate with all of the services that the systems can potentially reciprocate online. Java, JavaScript, and Python are examples, as are upcoming languages like Go and Scala.
This job requires a handful of skills, starting from a strong foundation of SQL and programming languages like Python , Java , etc. They achieve this through a programming language such as Java or C++. It is considered the most commonly used and most efficient coding language for a Data engineer and Java, Perl, or C/ C++.
Glue automatically creates Scala or Python code for your ETL tasks, which you can modify using tools you are already comfortable with. The Glue Data Catalog is loaded with relevant table definitions and statistics as the Glue crawlers automatically analyze different data stores you own to deduce schemas and partition structures.
See more details on understanding and managing related costs here as well as schema definitions in Snowflake documentation. Observability Application observability gets better with logging and tracing via event tables – public preview We are improving application observability for developers and data engineers. Learn more here.
While Kafka is probably best known from its key-based partitioning capabilities (see: ProducerRecord(String topic, K key, V value ) in Kafka’s Java API), it’s also possible to publish messages directly to the specific partition using the alternative, probably a less known ProducerRecord(String topic, Integer partition, K key, V value ).
It claims to support code reuse all over multiple workloads—batch processing, interactive queries, real-time analytics, machine learning, and graph processing—and offers development APIs in Java, Scala, Python , and R. Explore for Apache Spark Tutorial for more information. 5 best practices of Apache Spark 1.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content