This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In today’s heterogeneous data ecosystems, integrating and analyzing data from multiple sources presents several obstacles: data often exists in various formats, with inconsistencies in definitions, structures, and quality standards. This automated data catalog always provides up-to-date inventory of assets that never get stale.
Iceberg tables become interoperable while maintaining ACID compliance by adding a layer of metadata to the data files in a users object storage. An external catalog tracks the latest table metadata and helps ensure consistency across multiple readers and writers. Put simply: Iceberg is metadata.
You can also add metadata on models (in YAML). In a nutshell the dbt journey starts with sources definition on which you will define models that will transform these sources to something else you'll need in your downstream usage of the data. You can read dbt's official definitions.
While data products may have different definitions in different organizations, in general it is seen as data entity that contains data and metadata that has been curated for a specific business purpose. A data fabric weaves together different data management tools, metadata, and automation to create a seamless architecture.
Key Takeaways: Prioritize metadata maturity as the foundation for scalable, impactful data governance. The past year brought significant changes, from the growing importance of metadata maturity to the increasing convergence of data governance and data quality practices. How can you further improve your strategy moving forward?
This diversity created a unique hurdle for offline assets: the inability to reuse schemas due to the limitations of physical table schemas in adapting to changing definitions. Each product features its own distinct data model, physical schema, query language, and access patterns. Creating a canonical representation for compliance tools.
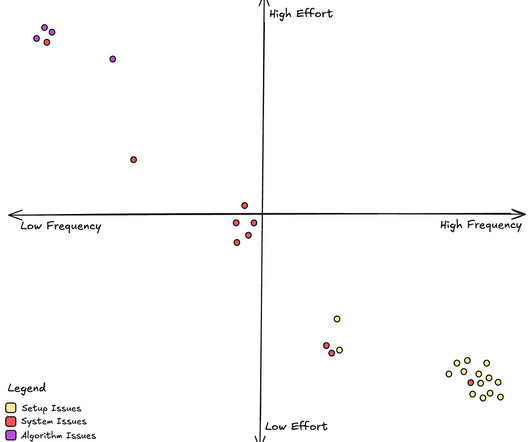
In this case, the main stakeholders are: - Title Launch Operators Role: Responsible for setting up the title and its metadata into our systems. While this is a critical business need and we definitely should solve it, its essential to evaluate how it stacks up against other priorities across different areas of the organization.
Multi-dimensional data model Similar to how Kubernetes labels infrastructure metadata, the model's structure is built on key-value pairs. Some of them may be configured to filter and match container metadata, making them perfect for ephemeral Kubernetes workloads. Kubernetes-pods: If the pod metadata is marked with prometheus.io/scrape
These tools can be called by LLM systems to learn about your data and metadata. With the dbt MCP server, LLMs can understand and query these metrics directly, ensuring that AI-generated analyses are consistent with your organization's definitions. Consider starting in a sandbox environment or only granting read permissions.
depending on location) BigQuery maintains a lot of valuable metadata about tables, columns and partitions. Utilize INFORMATION_SCHEMA to retrieve table metadata like distinct partition values, significantly reducing costs compared to traditional queries. GB Assuming we are running a SELECT * on this table, it would cost us 5.78
Content-Based Filtering Content-based filtering utilizes the attributes & metadata of a movie to generate recommendations that share similar properties. However, the quality of content-based filtering can be affected if a movie's metadata is incorrectly labeled, misleading or limited in scope.
Next, look for automatic metadata scanning. It has real-time metadata updates, deep data lineage, and its flexible if you want to customize or extend it for your teams specific needs. OpenMetadata Source: DataHub Then theres OpenMetadata , which is kind of like the Swiss Army knife of metadata tools. Its simple, but it works.
Enhanced Testing & Profiling Copy & Move Tests with Ease The Test Definitions page now supports seamless test migration between test suites. Better Metadata Management Add Descriptions and Data Product tags to tables and columns in the Data Catalog for improved governance. DataOps just got more intelligent.
Can you share your definition of "data discovery" and the technical/social/process components that are required to make it viable? Can you share your definition of "data discovery" and the technical/social/process components that are required to make it viable?
Workflow Definitions Below you can see a typical file structure of a sample workflow package written in SparkSQL. ??? In every sample workflow package there are three workflow definition files that work together to provide flexible functionality. Attributes are set via Metacat , which is a Netflix internal metadata management platform.
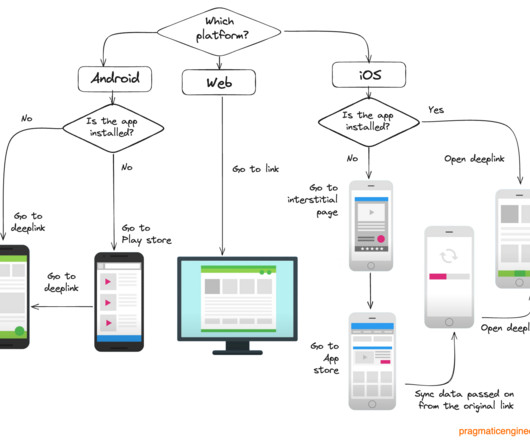
Now after 7 years, Google has announced it will retire Firebase Dynamic Links, but with no definite successor lined up. To make this migration easier and as seamless as possible, we will give developers the ability to export their deep-link metadata.”
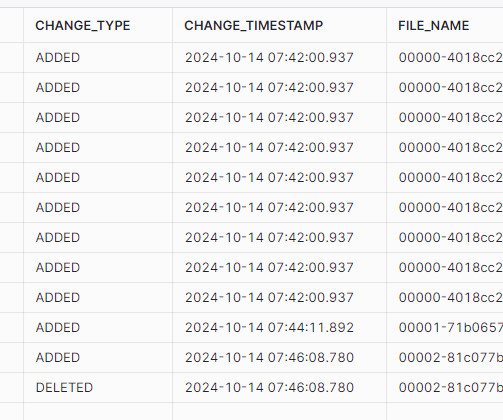
When using Iceberg tables, every Data Definition Language ( DDL ) operation triggers the generation of a new metadata JSON file that captures the updated structure. This article outlines a process for efficiently tracking schema changes in Iceberg tables by leveraging Snowflake’s powerful metadata storage capabilities.
Since the previous stable version ( 0.3.1 ), efforts have been made on three principal fronts: tooling (in particular the language server), the core language semantics (contracts, metadata, and merging), and the surface language (the syntax and the stdlib). The | symbol attaches metadata to fields.
Acryl]([link] The modern data stack needs a reimagined metadata management platform. Acryl]([link] The modern data stack needs a reimagined metadata management platform. Acryl Data’s vision is to bring clarity to your data through its next generation multi-cloud metadata management platform.
Instead of writing functions that return records and pipe them together, we write records directly where all fields might not have a definition yet. Metadata can be attached to record fields, giving them more expressive power and the ability to better describe an interface for a partial configuration. s t r i n g. s t r i n g.
In every step,we do not just read, transform and write data, we are also doing that with the metadata. The Dataops Heritage In my previous article, I have described the loop around the devops part of dataops. Last part, it was added the data security and privacy part.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Can you share your definition of "behavioral data" and how it is differentiated from other sources/types of data?
Metadata Caching. This is used to provide very low latency access to table metadata and file locations in order to avoid making expensive remote RPCs to services like the Hive Metastore (HMS) or the HDFS Name Node, which can be busy with JVM garbage collection or handling requests for other high latency batch workloads.
Data and Metadata: Data inputs and data outputs produced based on the application logic. Also included, business and technical metadata, related to both data inputs / data outputs, that enable data discovery and achieving cross-organizational consensus on the definitions of data assets.
What is your philosophy on enforcing uniformity in technical systems vs. relying on interface definitions as the unit of consistency? TimeXtender Logo]([link] TimeXtender is a holistic, metadata-driven solution for data integration, optimized for agility. How are you managing visibility/auditability across the different data domains?
It houses metadata and both the desired and current state for each resource. So, if any other component needs to access information about the metadata or state of resources stored in the etcd, they have to go through the kube-apiserver. This ensures that all of the configurations are set correctly before being stored in the etcd.
In this blog, we’ll highlight the key CDP aspects that provide data governance and lineage and show how they can be extended to incorporate metadata for non-CDP systems from across the enterprise. Atlas provides open metadata management and governance capabilities to build a catalog of all assets, and also classify and govern these assets.
VP of Architecture, Healthcare Industry Organizations will focus more on metadata tagging of existing and new content in the coming years. Quotes I think many organizations practice data governance at a very high level, mostly at the policy and process definitional level. No problem! is fairly advanced.
How ThoughtSpot builds trust with data catalog connectors For many, the data catalog is still the primary home for metadata enrichment and governance. Our data catalog integrations allow you to tap into this metadata wealth and surface it in the context where it’s needed most—when conducting business analytics.
This is really for us the definition of a self serve platform. and he/she has different actions to execute (reading, calling a vision API, transform, create metadata, store them, etc…). TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. What you have to code is this workflow
For each data logs table, we initiate a new worker task that fetches the relevant metadata describing how to correctly query the data. The data logs workflow will gather metadata, then prepare requester IDs, then run parallel processes for each table. For instance, a Hack enum could define a set of user interface element references.
What is your working definition of "data governance" and how does that influence your product focus and priorities? Acryl]([link] The modern data stack needs a reimagined metadata management platform. Acryl Data’s vision is to bring clarity to your data through its next generation multi-cloud metadata management platform.
What are the patterns that you and the community have established to encourage discovery and reuse of granular task definitions? How have you approached the design of data contracts/type definitions to provide a consistent/portable API for defining inter-task dependencies across languages?
Can you describe what your working definition of "Data Culture" is? TimeXtender Logo]([link] TimeXtender is a holistic, metadata-driven solution for data integration, optimized for agility. Can you describe what your working definition of "Data Culture" is? How are they interdependent?
It maintains metadata, manages tablet allocation, lists nodes, and handles permissions. Consistency: A table creation will request CoordinatorServer, which creates the metadata and assigns replicas to TabeltServers (three replicas by default), one of which is the leader. How Fluss manages Real-Time Updates and Changelog Management?
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. How have the definitions shifted over the past few decades? Atlan is the metadata hub for your data ecosystem.
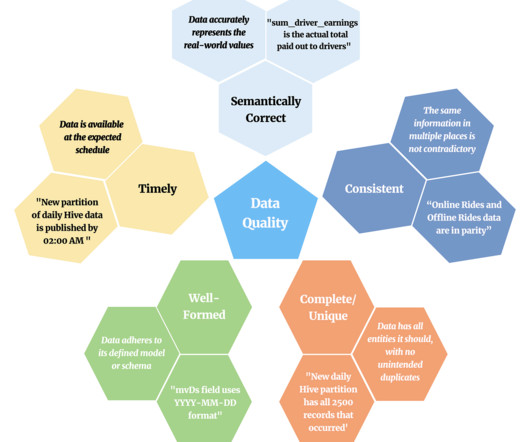
Data quality is an amorphous term, with various definitions depending on the context. In Verity, we defined data quality as follows: Verity’s Definition of Data Quality The measure of how well data can be used as intended. Five aspects of data quality with the definition in italics and an example in quotes.
Support for auto-refresh and Iceberg metadata generation is coming soon to Delta Lake Direct. To help ensure that you are querying the latest versions of your tables, you can add an auto-refresh setting (generally available soon) to your Iceberg table and catalog integration definitions in SQL.
It filters out any invalid entries and enriches the valid ones with additional metadata, such as show or movie title details, and the specific page and row location where each impression was presented to users. This refined output is then structured using an Avro schema, establishing a definitive source of truth for Netflixs impression data.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. What are the different places in a data system that schema definitions need to be established?
If we can place the metadata, indexing, and recent data files in Express One, we can potentially build a Snowflake-style performant architecture in Lakehouse. Apache Hudi, for example, introduces an indexing technique to Lakehouse. We all know that data freshness plays a critical role in the performance of Lakehouse.
It also becomes the role of the data engineering team to be a “center of excellence” through the definitions of standards, best practices and certification processes for data objects. In a fast growing, rapidly evolving, slightly chaotic data ecosystem, metadata management and tooling become a vital component of a modern data platform.
Different schemas, naming standards, and data definitions are frequently used by disparate repository source systems, which can lead to datasets that are incompatible or conflicting. The danger of quality degradation is reduced when subsequent migration planning is supported by an accurate inventory and assessment.
Every company out there has his own definition for the data engineer role. What is data engineering As I said it before data engineering is still a young discipline with many different definitions. Reddit r/dataengineering wiki a place where some data eng definitions are written. Who are the data engineers? Is it really modern?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content