

A Definitive Guide to Using BigQuery Efficiently
Towards Data Science
MARCH 5, 2024
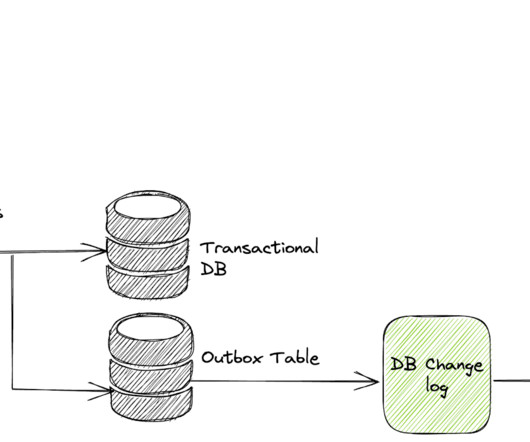
The storage system is using Capacitor, a proprietary columnar storage format by Google for semi-structured data and the file system underneath is Colossus, the distributed file system by Google. depending on location) BigQuery maintains a lot of valuable metadata about tables, columns and partitions. in europe-west3.


































Let's personalize your content