This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
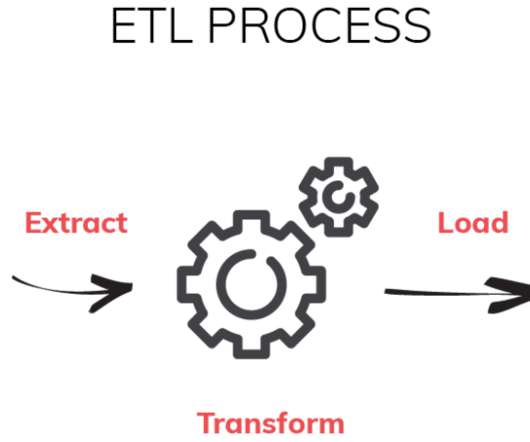
In the ELT, the load is done before the transform part without any alteration of the data leaving the rawdata ready to be transformed in the data warehouse. In a simple words dbt sits on top of your rawdata to organise all your SQL queries that are defining your data assets.
And then a wide variety of business intelligence (BI) tools popped up to provide last mile visibility with much easier end user access to insights housed in these DWs and data marts. But those end users werent always clear on which data they should use for which reports, as the datadefinitions were often unclear or conflicting.
The result of these batch operations in the data warehouse is a set of comma delimited text files containing the unfiltered rawdata logs for each user. We do this by passing the rawdata through various renderers, discussed in more detail in the next section.
You’re maintaining two systems, so your data team needs to be agile enough to work with different technologies while keeping their datadefinitions consistent. Want to run SQL queries on your structured data while also keeping raw files for your data scientists to play with? The downside?
Snowflake Secure Data Sharing helps reinforce the fact that our customers’ data is their data. While most customers prefer the Hum dashboard or APIs, more advanced customers want to flow more of the rawdata into their warehouses or lakehouses. Snowflake makes it easy and cheap for them to pull in their data.
Data Engineering at Adyen — "Data engineers at Adyen are responsible for creating high-quality, scalable, reusable and insightful datasets out of large volumes of rawdata" This is a good definition of one of the possible responsibilities of DE.
Levels of Data Aggregation Now lets look at the levels of data aggregation Level 1: At this level, unprocessed data are collected from various sources and put in one source. Level 2: At this stage, the rawdata is processed and cleaned to get rid of inconsistent data, duplicates values, and error in datatype.
Keeping data in data warehouses or data lakes helps companies centralize the data for several data-driven initiatives. While data warehouses contain transformed data, data lakes contain unfiltered and unorganized rawdata.
When created, Snowflake materializes query results into a persistent table structure that refreshes whenever underlying data changes. These tables provide a centralized location to host both your rawdata and transformed datasets optimized for AI-powered analytics with ThoughtSpot.
The inception of the data lakehouse came about as cloud warehouse providers began adding features ordinarily associated with lakes, as seen in platforms like Redshift Spectrum and Delta Lake. Conversely, data lakes began incorporating warehouse-like features, such as including SQL functionality and schema definitions.
Affinity Mapping Definition: Affinity mapping is a collaborative technique in design used to organize ideas, information, and issues. It helps you convert the rawdata into actionable insights, streamlining the design workflow and promoting better decision-making. What is Affinity Mapping?
Right now we’re focused on rawdata quality and accuracy because it’s an issue at every organization and so important for any kind of analytics or day-to-day business operation that relies on data — and it’s especially critical to the accuracy of AI solutions, even though it’s often overlooked.
The greatest data processing challenge of 2024 is the lack of qualified data scientists with the skill set and expertise to handle this gigantic volume of data. Inability to process large volumes of data Out of the 2.5 quintillion data produced, only 60 percent workers spend days on it to make sense of it.
If the general idea of stand-up meetings and sprint meetings is not taken into consideration, a day in the life of a data scientist would revolve around gathering data, understanding it, talking to relevant people about the data, asking questions about it, reiterating the requirement and the end product, and working on how it can be achieved.
However, while anyone may access rawdata, you can extract relevant and reliable information from the numbers that will determine whether or not you can achieve a competitive edge for your company. When people speak about insights in data science, they generally mean one of three components: What is Data?
It transforms multiple financial and operational systems’ rawdata into a common, friendly data model that people can understand. With Maxa, business teams go from manually managing core systems of record data to working with a single system of insights. Maxa Maxa automates financial and ERP insights.
If you ingest this log data into SSB, for example, by automatically detecting the data’s schema by sampling messages on the Kafka stream, this field will be ignored before it gets into SSB, though they are in the rawdata. This might be OK for some cases.
The Metrics Layer, also known as a Semantic Layer, is a critical component of the modern data stack that has recently received significant industry attention offers a powerful solution to the challenge of standardizing metric definitions. Lack of governance Our platform lacked governance policies for metric definitions.
Your test passes when there are no rows returned, which indicates your data meets your defined conditions. The `dbt run` command will compile and execute your models, thus transforming your rawdata into analysis-ready tables. Once the models are created and data transformed, `dbt test` should be executed.
Summary The most complicated part of data engineering is the effort involved in making the rawdata fit into the narrative of the business. Can you start by giving your definition of what MDM is and the scope of activities/functions that it includes? Can you describe what Profisee is and the story behind it?
Due to compression and high performance computing, scientists can analyze billions of rows of rawdata on their laptops using languages and statistical libraries they are familiar with like Python and R. It centralizes metrics definitions which used to be scattered across many teams.
By combining crit and warn as part of the entire TScript definition, graphs and alerts are effectively the same thing. We would add TScript in the crit section like: Now, this will definitely alert us if the CPU goes over 80%, but this is very noisy. They can do that for alerting but still show the rawdata in the graph.
The data products are packaged around the business needs and in support of the business use cases. This step requires curation, harmonization, and standardization from the rawdata into the products. What is a data fabric? Ramsey International Modern Data Platform Architecture.
Data science uses machine learning algorithms like Random Forests, K-nearest Neighbors, Naive Bayes, Regression Models, etc. They can categorize and cluster rawdata using algorithms, spot hidden patterns and connections in it, and continually learn and improve over time.
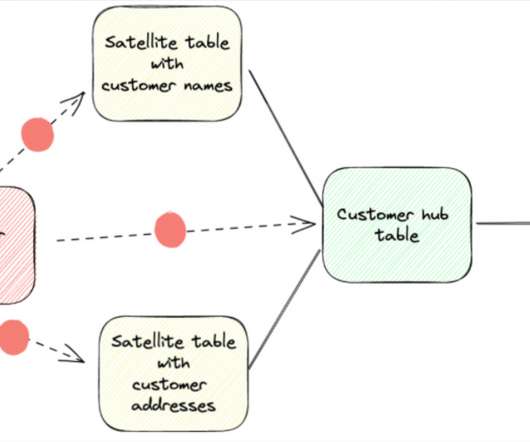
For those unfamiliar, data vault is a data warehouse modeling methodology created by Dan Linstedt (you may be familiar with Kimball or Imon models ) created in 2000 and updated in 2013. Data vault collects and organizes rawdata as underlying structure to act as the source to feed Kimball or Inmon dimensional models.
Commercial audio sets for machine learning are definitely more reliable in terms of data integrity than free ones. The same relates to those who buy annotated sound collections from data providers. Audio data labeling. It includes over 2 million human-labeld 10-second sound clips, extracted from YouTubbe videos.
Code implementations for ML pipelines: from rawdata to predictions Photo by Rodion Kutsaiev on Unsplash Real-life machine learning involves a series of tasks to prepare the data before the magic predictions take place.
A data engineer is an engineer who creates solutions from rawdata. A data engineer develops, constructs, tests, and maintains data architectures. Let’s review some of the big picture concepts as well finer details about being a data engineer. Earlier we mentioned ETL or extract, transform, load.
A DataOps Engineer owns the assembly line that’s used to build a data and analytic product. Figure 3: The Value Pipeline (data operations) and the Innovation Pipeline (analytics development). The Data Journey. A data pipeline is a series of steps that transform rawdata into analytic insights that create value.
This is where data transformation can come to the rescue. What is Data Transformation Simply speaking, the data transformation definition is the process of converting data from diverse sources into a standard format that supports its analysis.
Data modeling techniques on a normalization vs denormalization scale While the relevancy of dimensional modeling has been debated by data practitioners , it is still one of the most widely adopted data modeling technique for analytics.
Businesses benefit at large with these data collection and analysis as they allow organizations to make predictions and give insights about products so that they can make informed decisions, backed by inferences from existing data, which, in turn, helps in huge profit returns to such businesses. What is the role of a Data Engineer?
But this data is not that easy to manage since a lot of the data that we produce today is unstructured. In fact, 95% of organizations acknowledge the need to manage unstructured rawdata since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses. Why Use AWS Glue?
Low in Visibility End-users won’t be able to access all the data in the final destination, only the data that was transformed and loaded. First, every transformation performed on the data pushes you further from the rawdata and obscures some of the underlying information. This causes two issues.
As we proceed further into the blog, you will find some statistics on data engineering vs. data science jobs and data engineering vs. data science salary, along with an in-depth comparison between the two roles- data engineer vs. data scientist. vs. What does a Data Engineer do?
Odds are that your local hospital, pharmacy or medical institution's definition of being data-driven is keeping files in labelled file cabinets, as opposed to one single drawer. A simple example of a data pipeline, transforming rawdata, and converting it into a dashboard.
Business Intelligence and Artificial Intelligence are popular technologies that help organizations turn rawdata into actionable insights. While both BI and AI provide data-driven insights, they differ in how they help businesses gain a competitive edge in the data-driven marketplace.
Business Intelligence Analyst Job Description Popularly known as BI analysts, these professionals use rawdata from different sources to make fruitful business decisions. So, the first and foremost thing to do is to gather rawdata. So, their communication skills will definitely get challenged.
This involves continually striving to reduce wasted effort, identify gaps and correct them, and improve data development and deployment processes. While definitions of each of these roles may vary across organizations, each is responsible for making data available to data analysts, scientists, and other team members who depend on it.
Democratized stream processing is the ability of non-coder domain experts to apply transformations, rules, or business logic to streaming data to identify complex events in real time and trigger automated workflows and/or deliver decision-ready data to users.
Transformation: Shaping Data for the Future: LLMs facilitate standardizing date formats with precision and translation of complex organizational structures into logical database designs, streamline the definition of business rules, automate data cleansing, and propose the inclusion of external data for a more complete analytical view.
So let’s say that you have a business question, you have the rawdata in your data warehouse , and you’ve got dbt up and running. The analyst will try to do as much discovery work up-front as possible, because it’s hard to predict exactly what you’ll find in the rawdata. Or are you?
As someone actively defining and evolving the vision, roadmap and definition of success at Snowflake, Chris’s insights provide a glimpse into the future evolution of the industry. As Chris sees it, the next value unlock will be unifying data and its corresponding workloads across the many silos in which it still sits.
If digital transformation initiatives are to deliver on their promises, they need accurate, consistent, contextualized, and rich data. What Is Data Integrity? Until recently, the business community has lacked a clear and consistent definition of data integrity.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content