This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We all have our habits and as programmers, libraries and frameworks are definitely a part of the group. In this blog post I'll share with you a list of Java and Scala classes I use almost every time in data engineering projects. The part for Python will follow next week!
Workflow Definitions Below you can see a typical file structure of a sample workflow package written in SparkSQL. ??? In every sample workflow package there are three workflow definition files that work together to provide flexible functionality. See an example high water mark job from the main workflow definition. -
Setting Up Let’s create a new Scala 3 project and add the following to your build.sbt file. The UDP Server Create Fs2Udp.scala in the following path, src/main/scala/com/rockthejvm/fs2Udp/Fs2Udp.scala and add the following code: package com.rockthejvm.fs2Udp import cats.effect. val scala3Version = "3.3.1" lazy val root = project.
Discover a powerful technique for eliminating hard-to-trace bugs with ad-hoc type definitions: learn how Scala 2's newtypes and Scala 3's opaque types can enhance your code's safety and maintainability
Discover a powerful technique for eliminating hard-to-trace bugs with ad-hoc type definitions: learn how Scala 2's newtypes and Scala 3's opaque types can enhance your code's safety and maintainability
Antonio is an alumnus of Rock the JVM, now a senior Scala developer with his own contributions to Scala libraries and junior devs under his mentorship. Which brings us to this article: Antonio originally started from my Sudoku backtracking article and built a Scala CLI tutorial for the juniors he’s mentoring.
It could be a JAR compiled from Scala, a Python script or module, or a simple SQL file. The important thing is that this business logic can be built in a separate repository and maintained independently from the workflow definition. By external assets we simply mean some executable carrying the actual business logic of the job.
Introduction The Typelevel stack is one of the most powerful sets of libraries in the Scala ecosystem. They allow you to write powerful applications with pure functional programming - as of this writing, the Typelevel ecosystem is one of the biggest selling points of Scala. The Typelevel stack is based on Cats and Cats Effect.
Following is the authentic one-liner definition. One would find multiple definitions when you search the term Apache Spark. One would find the keywords ‘Fast’ and/or ‘In-memory’ in all the definitions. It’s also called a Parallel Data processing Engine in a few definitions.
CDE supports Scala, Java, and Python jobs. Some of the key entities exposed by the API: Jobs are the definition of something that CDE can run, usually composed of the application type, main program, and associated configuration. The user can use a simple wizard where they can define all the key configurations of their job.
The backend of Quala is called “tinbox” and is written in Scala , using many type-intensive libraries such as Shapeless , Circe , Grafter , and http4s/rho. One important design goal behind these libraries is to reduce boilerplate by letting the Scala compiler generate as much ceremony code as possible. versus Hydra. compiler is used!
Play Framework “makes it easy to build web applications with Java & Scala”, as it is stated on their site, and it’s true. In this article we will try to develop a basic skeleton for a REST API using Play and Scala. PlayScala plugin defines default settings for Scala-based applications. import Keys._
This article is for aspiring Scala developers. As the Scala ecosystem matures and evolves, this is the best time to become a Scala developer, and in this piece you will learn the essential tools that you should master to be a good Scala software engineer. Read this article to understand what you need to work with Scala.
Previous posts have looked at Algebraic Data Types with Java Variance, Phantom and Existential types in Java and Scala Intersection and Union Types with Java and Scala One of the difficult things for modern programming languages to get right is around providing flexibility when it comes to expressing complex relationships.
This article is for Scala developers of all levels - you don’t need any fancy Scala knowledge to make the best out of this piece. For those who don’t know yet, almost the entire Twitter backend runs on Scala, and the Finagle library is at the core of almost all Twitter services. serve ( ":9090" , stringLengthService ) Await.
Previous posts have looked at Algebraic Data Types with Java Variance, Phantom and Existential types in Java and Scala Intersection and Union Types with Java and Scala In this post we will combine some ideas from functional programming with strong typing to produce robust expressive code that is more reusable.
Scala or Java), this naming convention is probably second nature to you. The syntax is quite similar to many other languages (identical to Scala for example). This feature is called templating or interpolation (a feature borrowed from Scala). Values, Variables, and Types What’s programming without variables? Nothing fancy.
The application is written in Scala and using a Java High Level REST Client, which got deprecated in Elasticsearch 7.15.0 Of course, a lot of these files are the configs and tests and test resources, so the actual number of Scala files is much lower. But still, it's a lot of code, and a lot of it is dealing with Elasticsearch.
Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Can you share your definition of "data discovery" and the technical/social/process components that are required to make it viable?
It is definitely worth a good look for anyone building a platform that needs a simple to manage data layer that will scale with your business. It is definitely worth a good look for anyone building a platform that needs a simple to manage data layer that will scale with your business.
AWS Glue then creates data profiles in the catalog, a repository for all data assets' metadata, including table definitions, locations, and other features. You can also have the option of scripting the Python or Scala code in a script editor window or uploading an existing script locally. Why Use AWS Glue?
Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java. Can you start by giving your definition of what MDM is and the scope of activities/functions that it includes? Can you describe what Profisee is and the story behind it?
Math definition: (f (g x) = (f . Just for the sake of completeness, open interval can be also defined as (without requiring the Enum or Ord dependencies): [link] This class definition could be defined in a module, with other interval related functions. You can read succ . endClosed as succ(endClosed(i)).
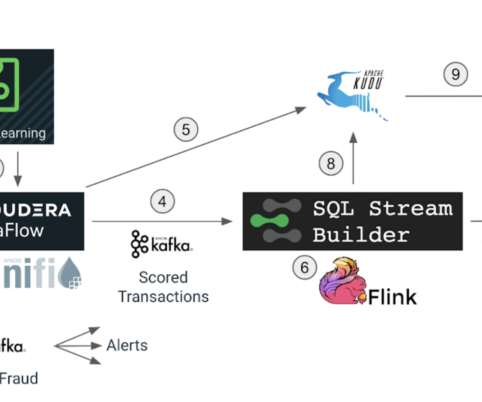
In this blog we will explore how we can use Apache Flink to get insights from data at a lightning-fast speed, and we will use Cloudera SQL Stream Builder GUI to easily create streaming jobs using only SQL language (no Java/Scala coding required). It provides flexible and expressive APIs for Java and Scala. Use case recap.
This led us towards choosing a format that supports defining a schema in a programming language agnostic Interface Definition Language (IDL) which could then propagate the schema across to all the applications that need to work on that data. Avro was an intriguing option, particularly because of Confluent’s support for this on Kafka.
New XP architecture: Systems highlighted in red are introspectable and contributable by data scientists Getting data with Metrics Repo Metrics Repo is an in-house Python framework where users define programmatically generated SQL queries and metric definitions. It centralizes metrics definitions which used to be scattered across many teams.
But instead of the spoon, there's Scala. Let me deconstruct this workshop title for you: The “type level” part is implying that it’s concerned with operating on the types of values used by computations of your Scala programs, in opposition to the regular value level meaning.
Thus, to facilitate our job it is possible to consolidate all the datasets into a single dataframe and create the “ city ” and “ weekday_or_weekend ” features, which definitely will be essential features to the model.
Moreover, if you have a Scala or Haskell background, you might notice some interesting similarities with the Type Classes. If we were in Scala, we would have called the JsonScope type class Jsonable or something like that. If we were in Scala, we would have called the JsonScope type class Jsonable or something like that.
From the definition as per the official website , PyTorch is an open-source machine learning framework that accelerates the path from research prototyping to production deployment. As per the definition from the official website , TensorFlow is an end-to-end open-source platform for machine learning. What is PyTorch ?
Shell, Adobe, Burberry, Columbia, Bayer — you definitely know the names. Moreover, the platform supports four languages — SQL, R, Python , and Scala — and allows you to switch between them and use them all in the same script. As a result, Scala code usually beats Python and R in terms of speed and performance.
DE supports Scala, Java, and Python jobs. Some of the key entities exposed by the API: Jobs are the definition of something that DE can run. For a data engineer that has already built their Spark code on their laptop, we have made deployment of jobs one click away. A job run is an execution of a job.
In part two we will explore how we can run real-time streaming analytics using Apache Flink, and we will use Cloudera SQL Stream Builder GUI to easily create streaming jobs using only SQL language (no Java/Scala coding required). You can simply connect to the CDF console, upload the flow definition, and execute it. The use case.
Last week's event: Scala Days.) And definitely don't miss Zalando Cloud Engineer/" STUPS Hacker" Henning Jacobs' presentation, " A Cloud Infrastructure for Scaling Innovation Across Autonomous Teams " (Solutions Track, Friday at 3:50 PM).
Riccardo is a proud alumnus of Rock the JVM, now a senior engineer working on critical systems written in Java, Scala and Kotlin. The above is the definition of continuations. Another tour de force by Riccardo Cardin. Version 19 of Java came at the end of 2022, bringing us a lot of exciting stuff.
The company can run various batch jobs from the workflow, including distributed and non-distributed TensorFlow jobs, distributed and non-distributed rapids jobs, and Jupyter notebooks (python/Scala/spark), R studio jobs, etc. They can launch parameterized notebooks and jobs with the help of Airflow's workflow functionality.
This tutorial complements Rock the JVM’s premium Scala masterclass , as you learn to set up and configure your Scala projects. Introduction SBT is the most popular build tool in the Scala ecosystem. SBT provides a very rich DSL to configure a Scala project. Please enjoy! Should’ve been the other way around.)
A good example is DTOs generated from a protocol buffer, an Avro, or a Swagger (OpenAPI) definition. Other languages supporting type classes, such as Scala and Haskell, implement some form of automatic discovery. Scala, for example, has an implicit resolution. required ( "userId" ), amount.
Scala developers have lots of options when it comes to doing Dependency Injection (or DI). But Scala being Scala, there are other options. You can use libraries leveraging macros, like MacWire , or use the Scala type system and the infamous “Cake pattern” and its many variations using traits, with or without self-types.
At that time I was a backend Scala developer with a.Net background. When examining Rust, I found most of the features I used every day like Pattern Matching, the “New Type Pattern” and a “Scala like” Iterator API. Early Prototyping It was in 2016 when I joined Zalando as a Scala Developer.
It’s a common conundrum, what you definitely don’t want to have is more scientists than engineers, because that would mean the former are doing the engineering work. Data engineers are well-versed in Java, Scala, and C++, since these languages are often used in data architecture frameworks such as Hadoop, Apache Spark, and Kafka.
Spark: The Definitive Guide - Big Data Processing Made Simple by Bill Chambers and Matei Zaharia Spark: The Definitive Guide by Bill Chambers and Matei Zaharia is a comprehensive guide to Apache Spark, suitable for beginners and experts that help you learn how to use, deploy, and maintain Apache Spark.
Some of the best books that will guide you in Scala are:- Scala Cookbook: Recipes for Object-Oriented and Functional Programming (Author: Alvin Alexander) Scala for the Impatient (Author: Cay S. Horstmann) Programming Scala: Scalability = Functional Programming + Objects (Author: Alex Payne and Dean Wampler) 2.
As per Apache, “ Apache Spark is a unified analytics engine for large-scale data processing ” Spark is a cluster computing framework, somewhat similar to MapReduce but has a lot more capabilities, features, speed and provides APIs for developers in many languages like Scala, Python, Java and R.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content