This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Were explaining the end-to-end systems the Facebook app leverages to deliver relevant content to people. At Facebooks scale, the systems built to support and overcome these challenges require extensive trade-off analyses, focused optimizations, and architecture built to allow our engineers to push for the same user and business outcomes.
Not only could this recommendation system save time browsing through lists of movies, it can also give more personalized results so users don’t feel overwhelmed by too many options. What are Movie Recommendation Systems? Recommender systems have two main categories: content-based & collaborative filtering.
Buck2 is a from-scratch rewrite of Buck , a polyglot, monorepo build system that was developed and used at Meta (Facebook), and shares a few similarities with Bazel. As you may know, the Scalable Builds Group at Tweag has a strong interest in such scalable build systems. Meta recently announced they have made Buck2 open-source.
When you hear the term System Hacking, it might bring to mind shadowy figures behind computer screens and high-stakes cyber heists. In this blog, we’ll explore the definition, purpose, process, and methods of prevention related to system hacking, offering a detailed overview to help demystify the concept.
When it comes to managing data, a database management system (DBMS) is a vital tool. Database management systems (DBMS) use entities to represent and manage data. In a database management system (DBMS), an entity is a piece of data tracked and stored by the system. But what is an entity? What is Entity Set in DBMS?
Both AI agents and business stakeholders will then operate on top of LLM-driven systems hydrated by the dbt MCP context. Todays system is not a full realization of the vision in the posts shared above, but it is a meaningful step towards safely integrating your structured enterprise data into AI workflows. Why does this matter?
System based on XML. Using XML eliminates the requirement for bindings on platforms, operating systems, or networks. Because the server’s and mentor’s decisions are closely related to one another in a strongly coupled system, both interfaces must be updated if one changes. Information on web administrations 3.
But on the other side, TestSigma is a comprehensive AI-driven testing automation system that uses artificial intelligence to reduce the technical intricacy of test automation. Containerization solutions also aid distribution by ensuring uniformity between development, testing, operational, and staging systems.
The storage system is using Capacitor, a proprietary columnar storage format by Google for semi-structured data and the file system underneath is Colossus, the distributed file system by Google. BigQuery separates storage and compute with Google’s Jupiter network in-between to utilize 1 Petabit/sec of total bisection bandwidth.
Amazon’s SDE3 definition is closer to what is considered a “team lead” or “tech lead” role at many companies, and so I view this SDE3 role as being at the upper end of a senior engineer definition. Address systemic issues. Reduce support costs by addressing systemic issues.
An operating system that allows multiple programmes to run simultaneously on a single processor machine is known as a multiprogramming operating system. Imagine that I/O is a part of the process that is currently running (which, by definition, does not need the CPU to be accomplished). context switching).
The simple idea was, hey how can we get more value from the transactional data in our operational systems spanning finance, sales, customer relationship management, and other siloed functions. But those end users werent always clear on which data they should use for which reports, as the data definitions were often unclear or conflicting.
Applying systems thinking views a system as a set of interconnected and interdependent components defined by its limits and more than the sum of their parts (subsystems). When one component of a system is altered, the effects frequently spread across the entire system. are the main objectives of systems thinking.
Analytics Engineers deliver these insights by establishing deep business and product partnerships; translating business challenges into solutions that unblock critical decisions; and designing, building, and maintaining end-to-end analytical systems. DJ acts as a central store where metric definitions can live and evolve.
You will learn how to build up Kube-state-metrics system, pull and collect metrics, deploy a Prometheus server and metrics exporters, configure alerts with Alertmanager, and create Grafana dashboards. Metric Endpoint: The systems you want Prometheus to monitor should disclose their metrics on an endpoint called /metrics.
In today’s heterogeneous data ecosystems, integrating and analyzing data from multiple sources presents several obstacles: data often exists in various formats, with inconsistencies in definitions, structures, and quality standards.
In this case, the main stakeholders are: - Title Launch Operators Role: Responsible for setting up the title and its metadata into our systems. In this context, were focused on developing systems that ensure successful title launches, build trust between content creators and our brand, and reduce engineering operational overhead.
Meta’s vast and diverse systems make it particularly challenging to comprehend its structure, meaning, and context at scale. We discovered that a flexible and incremental approach was necessary to onboard the wide variety of systems and languages used in building Metas products. We believe that privacy drives product innovation.
In particular, our machine learning powered ads ranking systems are trying to understand users’ engagement and conversion intent and promote the right ads to the right user at the right time. Specifically, such discrepancies unfold into the following scenarios: Bug-free scenario : Our ads ranking system is working bug-free.
ChatGPT can be an unexpectedly useful to break down jargon terms: just don't forget to verify its definition, as ChatGPT can make things up. I was sceptical that any system would automatically reject resumes, because I never saw this as a hiring manager. Otherwise, understand the jargon in simple terms, yourself.
The data warehouse solved for performance and scale but, much like the databases that preceded it, relied on proprietary formats to build vertically integrated systems. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
To start, can you share your definition of what constitutes a "Data Lakehouse"? What are the pain points that are still prevalent in lakehouse architectures as compared to warehouse or vertically integrated systems? To start, can you share your definition of what constitutes a "Data Lakehouse"?
We’re introducing parameter vulnerability factor (PVF) , a novel metric for understanding and measuring AI systems’ vulnerability against silent data corruptions (SDCs) in model parameters. But the growing complexity and diversity of AI hardware systems also brings an increased risk of hardware faults such as bit flips.
The answer lies in unstructured data processing—a field that powers modern artificial intelligence (AI) systems. To address these challenges, AI Data Engineers have emerged as key players, designing scalable data workflows that fuel the next generation of AI systems. How does a self-driving car understand a chaotic street scene?
I wrote code for drivers on Windows, and started to put a basic observability system in place. EC2 had no observability system back then: people would spin up EC2 instances but have no idea whether or not they worked. With my team, we built the basics of what is now called AWS Systems Manager.
For example, ticketing, merchandise, fantasy engagement and game viewership data often reside in separate systems (or with separate entities), making it a challenge to bring together a cohesive view of each fan. Technology implementation is "a part of," but not the definition of," its approach.
Ayhan visualized this data and observed a definite fall in all metrics: page views, visits, questions asked, votes. Q&A activity is definitely down: the company is aware of this metric taking a dive, and said they’re actively working to address it. Booking.com says a systems migration is the reason for the delay.
CDE vendors: a definite trend With more than 20 players in this space, let’s begin with a timeline of when the products launched. It’s also possible to posit that the “spark” which ignited this confluence of factors was the Covid-19 pandemic of 2020-21, and the accompanying rise of remote work.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand. We also considered caching data logs in an online system capable of supporting a range of indexed per-user queries. What are data logs?
Many of these projects are under constant development by dedicated teams with their own business goals and development best practices, such as the system that supports our content decision makers , or the system that ranks which language subtitles are most valuable for a specific piece ofcontent. cluster=sandbox, workflow.id=demo.branch_demox.EXP_01.training
This basically means the tool updates itself by pulling in changes to data structures from your systems. Its definitely not feature-rich, but if you’re just starting out and want something fast and free, its way better than nothing. You dont want to dig through endless tabs or outdated spreadsheets. Its simple, but it works.
With data volumes skyrocketing, and complexities increasing in variety and platforms, traditional centralized data management systems often struggle to keep up. As data management grows increasingly complex, you need modern solutions that allow you to integrate and access your data seamlessly.
She asked the Director of Engineering if he could help take a known set of FAFSA application data and use it to artificially augment a much larger set of anonymous data tht her systems had collected over time. The engineering director’s next step?
Summary One of the perennial challenges of data analytics is having a consistent set of definitions, along with a flexible and performant API endpoint for querying them. What is your overarching design philosophy for the API of the Cube system? What are some of the data modeling steps that are needed in the source systems?
Delays and failures are inevitable in distributed systems, which may delay IP address change events from reaching FlowCollector. FlowCollector consumes a stream of IP address change events from Sonar and uses this information to attribute flow IP addresses in real-time.
” My take is that in the way Covid-19 was an unforeseen ‘black swan’ event, so was the boom in tech and in VC-funding in 2021, which was definitely impacted by the pandemic, thanks to businesses and consumers shifting to digital, as a result of the lockdowns making in-person activities difficult and non-practical.
[link] Alex Miller: Decomposing Transactional Systems I was re-reading Jack Vanlightly's excellent series on understanding the consistency model of various lakehouse formats when I stumbled upon the blog on decomposing transaction systems. Apache Hudi, for example, introduces an indexing technique to Lakehouse.
Thanks to the Netflix internal lineage system (built by Girish Lingappa ) Dataflow migration can then help you identify downstream usage of the table in question. Workflow Definitions Below you can see a typical file structure of a sample workflow package written in SparkSQL. ??? backfill.sch.yaml ??? daily.sch.yaml ???
What are the technical systems that you are relying on to power the different data domains? What is your philosophy on enforcing uniformity in technical systems vs. relying on interface definitions as the unit of consistency? What are the technical systems that you are relying on to power the different data domains?
Unified Logging System: We implemented comprehensive engagement tracking that helps us understand how users interact with gift content differently from standardPins. Unified Logging System: We implemented comprehensive engagement tracking that helps us understand how users interact with gift content differently from standardPins.
The last important remaining piece to explore is the merge system. In this post, we’ll see how to use the Nickel merge system to write reusable configuration modules, and why the merge approach seems to be more adapted for modular configurations than plain functions, despite Nickel being a functional language.
What are the skills and systems that need to be in place to effectively execute on an AI program? "AI" What are some of the useful clarifying/scoping questions to address when deciding the path to deployment for different definitions of "AI"? "AI" has grown to be an even more overloaded term than it already was.
This approach is super cost-efficient because you’re not running your systems constantly. Sure, it might cost more to keep systems running 24/7, but when you need instant insights, nothing else will do. You’re basically running two systems in parallel – one for batch processing and one for streaming. The downside?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















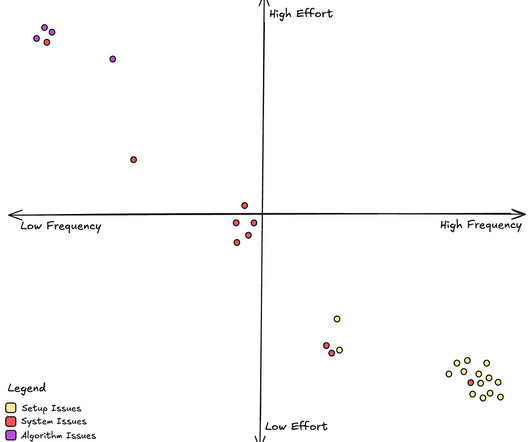

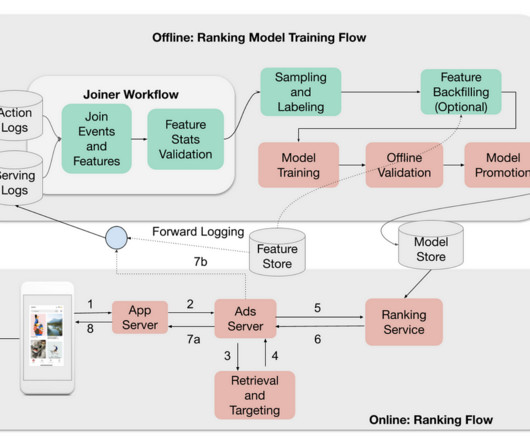







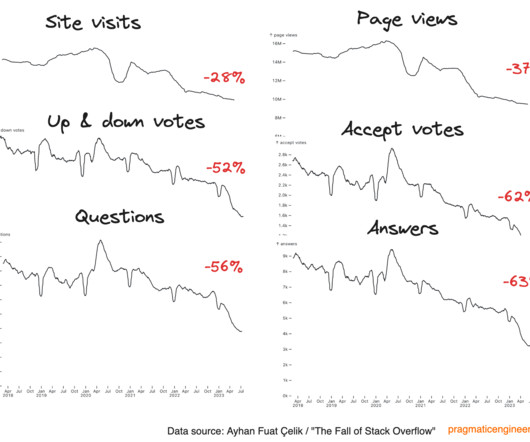
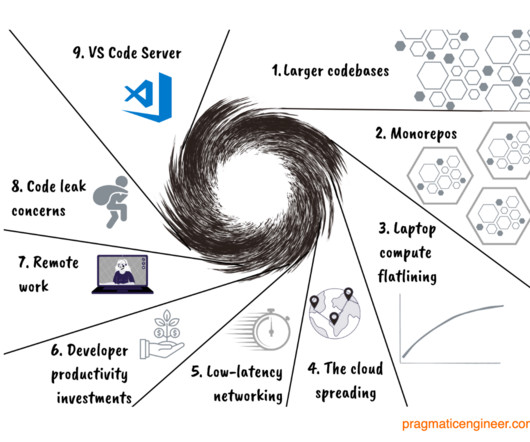


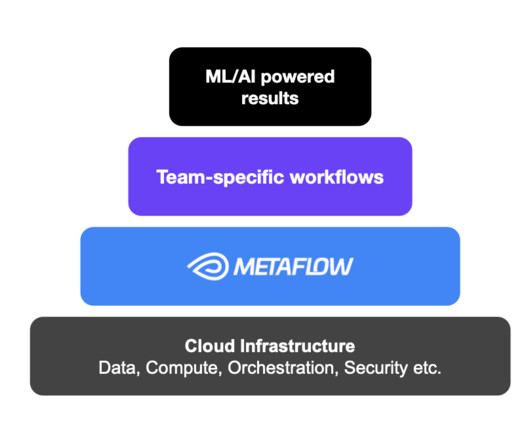




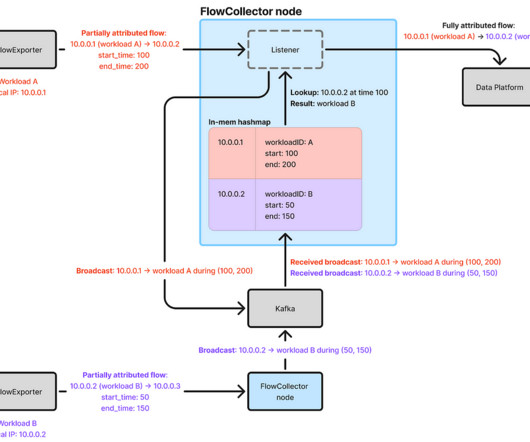














Let's personalize your content