This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
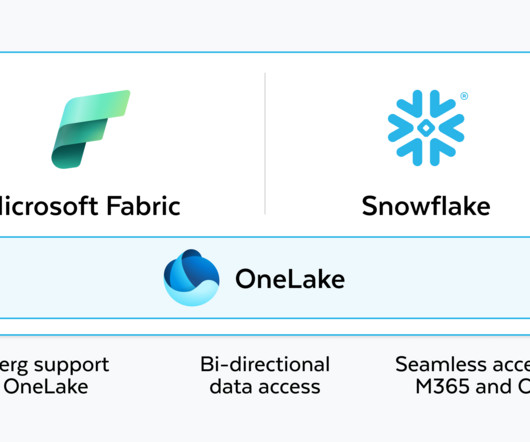
Iceberg tables become interoperable while maintaining ACID compliance by adding a layer of metadata to the data files in a users object storage. An external catalog tracks the latest table metadata and helps ensure consistency across multiple readers and writers. Put simply: Iceberg is metadata.
The key to those solutions is a robust and flexible metadata management system. LinkedIn has gone through several iterations on the most maintainable and scalable approach to metadata, leading them to their current work on DataHub. What were you using at LinkedIn for metadata management prior to the introduction of DataHub?
Next, look for automatic metadata scanning. It has real-time metadata updates, deep data lineage, and its flexible if you want to customize or extend it for your teams specific needs. OpenMetadata Source: DataHub Then theres OpenMetadata , which is kind of like the Swiss Army knife of metadata tools.
Better Metadata Management Add Descriptions and Data Product tags to tables and columns in the Data Catalog for improved governance. Watch the Launch Webinar Here: [link] Download Now Request Demo Smarter Profiling & Test Generation Improved logic reduces false positives , making test results more accurate and actionable.
Automated metadata management – AI-generated catalog asset descriptions significantly reduce manual efforts and improve metadata quality – enabling teams to focus on more strategic tasks. Take the next steps in your data integrity journey today learn more about the Data Integrity Suite and schedule a personalized demo.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. Atlan is the metadata hub for your data ecosystem.
Blog An instant demo of data lineage is worth a thousand words Written by Ross Turk on August 10, 2021 They say that a picture is worth a thousand words. That’s why we have made an instant demo of Datakin available at demo.datakin.com. After that, you can explore a collection of metadata from a fictional data pipeline.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. Atlan is the metadata hub for your data ecosystem.
As Snowflake operates on the tables and writes data, OneLake will automatically convert the Iceberg metadata to Delta Lake format, without rewriting the Parquet files, so that Fabric engines can query the same tables. Similarly, Fabric OneLake enables Snowflake to read all OneLake data in Iceberg format, for consumption by Snowflake’s engine.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. Atlan is the metadata hub for your data ecosystem.
Snowpark ML Operations: Model management The path to production from model development starts with model management, which is the ability to track versioned model artifacts and metadata in a scalable, governed manner. The Snowpark Model Registry API provides simple catalog and retrieval operations on models.
This journey must include a strong data governance framework to align people, processes, and technology, and enable them to understand and trust their data and metadata to achieve their business objectives. Does our organization’s data governance service include visibility and transparency of our spatial data and their metadata?
It supports “fuzzy” search — the service takes in natural language queries and returns the most relevant text results, along with associated metadata. For document- or chunk-level access controls, you can use metadata filtering to ensure that the service only returns the results that the client is authorized to view.
Not only do we have a unique vantage point into the challenges faced by data analysts, we also possess rich metadata that feeds into Snowflake’s dedicated text-to-SQL model that Copilot leverages in combination with Mistral’s technology. Or, experience Copilot firsthand at our free Dev Day event on June 6th in the Demo Zone!
Printing it loses all this metadata. On 29 Oct, Saturday morning, a new project kicked off, with the first demo due on Monday morning. The first demo was scheduled for Monday, 31 October, in the morning: only two days later. He indirectly mandated working over the weekend by setting a Monday morning demo deadline, on a Saturday.
The solution to discoverability and tracking of data lineage is to incorporate a metadata repository into your data platform. The metadata repository serves as a data catalog and a means of reporting on the health and status of your datasets when it is properly integrated into the rest of your tools.
Metadata and evolution support : We’ve added structured-type schema evolution for flexibility as source systems or business reporting needs change. Get better Iceberg ecosystem interoperability with Primary Key information added to Iceberg table metadata. In the meantime, you can get hands-on with Iceberg today!
Atlan is the metadata hub for your data ecosystem. Instead of locking all of that information into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Go to dataengineeringpodcast.com/atlan today to learn more about how you can take advantage of active metadata and escape the chaos.
kyutai released Moshi — Moshi is a "voice-enabled AI" The team as kyutai developed the model with an audio interface-first with an audio language model, which make the conversation with the AI more real (demo at 5:00 min) as it can interrupt you or kinda "think" (meaning for predict the next audio segment) while it speaks.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. Atlan is the metadata hub for your data ecosystem.
Catalog Integration: Our newly developed Catalog Integration feature allows you to seamlessly plug Snowflake into other Iceberg catalogs tracking table metadata. For metadata management, you can configure Snowflake to manage your Iceberg data or use an external Iceberg catalog. Have a Snowflake account and want to try this out?
If you need to deliver unprecedented speed, cost savings, and simplified access to large scale, real-time data, visit dataengineeringpodcast.com/molecula and request a demo. What is the current state of the ecosystem for generating and sharing metadata between systems? What are your goals for the OpenLineage effort?
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. Atlan is the metadata hub for your data ecosystem.
For this demo, I’ll use one of my favorite public feeds: real-time reservations in Meetup groups around the world. Given that events are produced in real time and at a reasonable pace, the Meetup feed is pretty handy for demos with real data. How about we take it for a spin? Try it yourself!
Additionally, Cortex Search supports date-range filtering on metadata columns. Watch the demo: See Cortex Agents in action. Improved customizability Cortex Search now provides the ability to select the vector embedding model for semantic search. This includes two multilingual models, snowflake-arctic-embed-l-v2.0 ai and Seek AI.
For example, when Confluent Monitoring Interceptors are configured on Kafka clients, they write metadata to a Kafka topic called _confluent-monitoring. In one command, this demo environment brings up an active-active multi-datacenter environment with Confluent Replicator copying data bidirectionally. Try it out yourself.
Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. What are some of the data modeling considerations that need to be considered when pushing metadata to Sifflet? Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
It consists of Python APIs accessible through the Snowpark ML library, and SQL interfaces for defining, managing and retrieving features, along with managed infrastructure for feature metadata management and continuous feature processing. Check out the Snowpark ML demo from Snowday to see the latest launches in action.
Data products contain data and its metadata, code, and infrastructure so that each product is self-contained and usable independently. These features elevate the data integration process, leveraging extensive metadata, AI, and ML algorithms. Operational data integration leadership DataOS supports a broad spectrum of use cases.
Access the AWS console ( docs , talk , demo ) ConsoleMe allows users to access the AWS console through the use of temporary IAM role credentials. Utilize ConsoleMe’s native policy editors for advanced requests ( docs , talk , demo ) ConsoleMe offers a native policy editor for popular resource types. Where can I learn more?
Atlan is the metadata hub for your data ecosystem. Instead of locking all of that information into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Go to dataengineeringpodcast.com/atlan today to learn more about how you can take advantage of active metadata and escape the chaos.
To highlight these new capabilities, we built a search demo using OpenAI to create embeddings for Amazon product descriptions and Rockset to generate relevant search results. In the demo, you’ll see how Rockset delivers search results in 15 milliseconds over thousands of documents. What does this mean for search?
Schedule a demo and well give you a personalized walkthrough or try Striim at production-scale for free! This would potentially require you to change your database log parsing logic with each new database release. Small data volumes or hoping to get hands on quickly? At Striim we also offer a free developer version.
Governed internal collaboration with better discoverability and AI-powered object metadata The Internal Marketplace (private preview) introduces a new way for customers to boost secure collaboration, through a single directory of all data products specifically curated for use within an organization.
Malloy's Near Term Roadmap — I've shared recently Malloy demo , which was awesome. Masthead does not run SQL on your data—which generate costs uplift—but reading logs and metadata to identify anomalies. You can put space in BigQuery column names — The editors of blef.fr (me) have no comment.
Request a demo at dataengineeringpodcast.com/metis-machine to learn more about how Metis Machine is operationalizing data science. Request a demo at dataengineeringpodcast.com/metis-machine to learn more about how Metis Machine is operationalizing data science.
Data products contain data and its metadata, code, and infrastructure so that each product is self-contained and usable independently. Augmented data integration, self-service data preparation, metadata support, and data governance are key strengths. Operational data integration leadership DataOS supports a broad spectrum of use cases.
Not only does ThoughtSpot not store your sample data or metadata, or use this information for model training, but we are also investing in bring-your-own and host-your-own model capabilities for both generative AI and machine learning models.
It logs each event with AI-enhanced metadata for effective tracking and auditing, while its adaptive design accommodates evolving data sources through schema evolution. Try Striim today with a free trial or book a demo to see it in action. Start Your Free Trial | Schedule a Demo
The snapshotId of the source tables involved in the materialized view are also maintained in the metadata. A Note on Iceberg materialized view specification Currently, the metadata needed for materialized views is maintained in Hive Metastore and it builds upon the materialized views metadata previously supported for Hive ACID tables.
Apache Ozone achieves this significant capability through the use of some novel architectural choices by introducing bucket type in the metadata namespace server. Provides high performance namespace metadata operations similar to HDFS. BucketLayout Feature Demo , describes the ozone shell, ozoneFS and aws cli operations.
To achieve a viable customer 360 solution at scale, a data team must: Build and maintain an identity graph Compute complex user traits Represent funnels as part of the journey Maintain metadata for predictive traits that change over time This work is complex and laborious. Click here to request a demo of Profiles.
In this blog, we will discuss performance improvement that Cloudera has contributed to the Apache Iceberg project in regards to Iceberg metadata reads, and we’ll showcase the performance benefit using Apache Impala as the query engine. Impala can access Hive table metadata fast because HMS is backed by RDBMS, such as mysql or postgresql.
It also provides metadata on what assumptions and fixes were used to inform the address match. Use our Quickstart to learn how to geocode address data with Mapbox’s native app, or watch a quick two-minute demo to see how Mapbox used the Snowflake Native App Framework to create its native app.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content