This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Document Intelligence Studio is a data extraction tool that can pull unstructured data from diverse documents, including invoices, contracts, bank statements, pay stubs, and health insurance cards. The cloud-based tool from Microsoft Azure comes with several prebuilt models designed to extract data from popular document types.
We recently announced our AI-generated documentation feature, which uses large language models (LLMs) to automatically generate documentation for tables and columns in Unity.
The blog covers methods for representing documents as vectors and computing similarity, such as Jaccard similarity, Euclidean distance, cosine similarity, and cosine similarity with TF-IDF, along with pre-processing steps for text data, such as tokenization, lowercasing, removing punctuation, removing stop words, and lemmatization.
It is estimated that between 80% and 90% of the world’s data is unstructured 1 , with text files and documents making up a significant portion. Every day, countless text-based documents, like contracts and insurance claims, are stored for safekeeping. Neither stage requires any ML- or application-development experience.
As organizations increasingly seek to enhance decision-making and drive operational efficiencies by making knowledge in documents accessible via conversational applications, a RAG-based application framework has quickly become the most efficient and scalable approach. Until now, document preparation (e.g.
for the simulation engine Go on the backend PostgreSQL for the data layer React and TypeScript on the frontend Prometheus and Grafana for monitoring and observability And if you were wondering how all of this was built, Juraj documented his process in an incredible, 34-part blog series. Documenting the steps. You can read this here.
Conversational apps: Creating reliable, engaging responses for user questions is now simpler, opening the door to powerful use cases such as self-service analytics and document search via chatbots. For instance, if your documents are in multiple languages, an LLM with strong multilingual capabilities is key.
Because they can preserve the visual layout of documents and are compatible with a wide range of devices and operating systems, PDFs are used for everything from business forms and educational material to creative designs. PDF files are one of the most popular file formats today.
The database landscape has reached 394 ranked systems across multiple categoriesrelational, document, key-value, graph, search engine, time series, and the rapidly emerging vector databases. As AI applications multiply quickly, vector technologies have become a frontier that data engineers must explore.
Its Snowflake Native App, Digityze AI, is an AI-powered document intelligence platform that transforms unstructured biomanufacturing documentation into structured, actionable data and manages the document lifecycle.
Unstructured text is everywhere in business: customer reviews, support tickets, call transcripts, documents. Meanwhile, operations teams use entity extraction on documents to automate workflows and enable metadata-driven analytical filtering.
ℹ️ I want to mention that the dbt documentation is one of the best tools documentation out there. You just have to understand that there is the reference part which is the detailed documentation of function or configuration and there is the documentation part which is more about concepts and tutorials.
Use cases range from getting immediate insights from unstructured data such as images, documents and videos, to automating routine tasks so you can focus on higher-value work. Healthcare professionals can use AI to create customized treatment plans, automate documentation and perform predictive health analytics.
In this edition, we talk to Richard Meng, co-founder and CEO of ROE AI , a startup that empowers data teams to extract insights from unstructured, multimodal data including documents, images and web pages using familiar SQL queries. Many financial services organizations rely on documents for a wealth of insights.
It stores and retrieves large amounts of data, including photos, movies, documents, and other files, in a durable, accessible, and scalable manner. Introduction S3 is Amazon Web Services cloud-based object storage service (AWS).
That type of volume can easily put a strain on the doctors, who not only serve the patients but also need to document each visit carefully — from summaries to diagnoses to medication orders. Its emergency departments get nearly 2 million visits per year, which amounts to more than 5,000 a day.
and how to apply it on your own document base without complex orchestration, integrations or infrastructure to manage. Get hands-on with tools like pandas, Document AI and Snowflake Notebooks Up-close, hands-on sessions and demos — created for builders, by builders — is what sets this event apart from other dev conferences. Efficiency!)
Whether we are analyzing IoT data streams, managing scheduled events, processing document uploads, responding to database changes, etc. Azure functions allow developers […] The post How to Develop Serverless Code Using Azure Functions? appeared first on Analytics Vidhya.
We built this AMP for two reasons: To add an AI application prototype to our AMP catalog that can handle both full document summarization and raw text block summarization. AMPs are all about helping you quickly build performant AI applications. More on AMPs can be found here.
This person wrote up a neat document that was well thought out, and sent it around to other senior staff engineers. But there was a problem, this engineer took an existing document that other engineers had written a few months before, copy-pasted it, changed a few words, and presented it as their own work.
Unlock value of unstructured documents with AI-enabled automated data extraction and integration Businesses of all kinds are flooded with documents every day — invoices, receipts, notices, forms and more — and yet getting and using the information therein remains manual, time-consuming and error-prone.
Several times throughout various testimonies, we’ve seen a document written by Sam Bankman-Fried, in which he describes his thinking that Alameda Research should be shut down. That document was, ultimately, how Singh learned in September 2022 that Alameda Research had taken billions of dollars of customer funds from FTX.
” They write the specification, code, tests it, and write the documentation. Edits documentation the chief programmer writes, and makes it production-ready. Brooks suggests the set up below, borrowed from Harlan Mills, could work well: The chief programmer. Brooks calls this person “the surgeon.” The copilot.
To analyze complex documents : Cortex AI enables financial companies to analyze quarterly reports, prospectuses and financial statements by extracting structured data from text, tables, and chart descriptions. Sonnet excels at document understanding with an impressive 90.3% Sonnet, as well as Metas Llama 4 Scout, and Open AIs GPT-4.1
The process requires a lot of documentation. With AI-powered text-processing capabilities, agents and underwriters can more quickly and effectively parse documents, identify gaps or mistakes and expedite the home-buying experience for customers.
In this document, we covered: The product The market The go-to-market (GTM) plan Our competitors … and many other things! With the plan in place, we sent this document – rather than the usual pitch deck – over to the VCs. Our approach was unorthodox, but worked!
See more details in the documentation. See more details in the documentation. All customer accounts are automatically provisioned to have access to default CPU and GPU compute pools that are only in use during an active notebook session and automatically suspended when inactive.
When you read the documentation on platform as a service (PaaS) offerings, youll often see references to features that are not supported in certain versions of the service, along with outage windows for planned maintenance none of these are an issue with Snowflake.
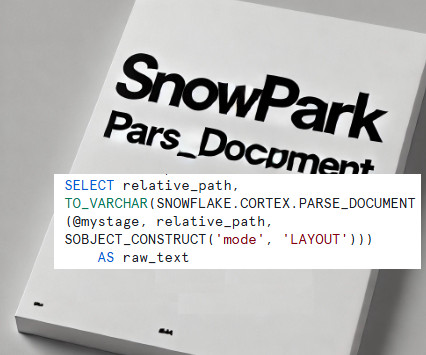
Traditionally, this function is used within SQL to extract structured content from documents. This blog explores how you can leverage the power of PARSE_DOCUMENT with Snowpark, showcasing a use case to extract, clean, and process data from PDF documents. Why Use PARSE_DOC? Why Use PARSE_DOCUMENT ?
Consider these examples from the updated documentation: You can choose the right level of runtime configurability versus fixed deployments by mixing Parameters and Configs. Take a look at two interesting examples of this pattern in the documentation. Try it athome It couldnt be easier to get started with Configs!Just
Metric definitions are often scattered across various databases, documentation sites, and code repositories, making it difficult for analysts and data scientists to find reliable information quickly.
After experiencing numerous data quality challenges, they created Anomalo, a no-code platform for validating and documenting data warehouse information. While working together, they bonded over their shared passion for data. For years, Anomalo has made it easy for Snowflake customers to monitor any Snowflake table or view.
An overview on “What is RAG” by edureka Retrieval This is the act of getting data from somewhere outside the computer, usually a database, knowledge base, or document store. In RAG, retrieval is the process of looking for useful data (like text or documents) based on what the user or system asks for or types in.
Pull requests, documentation updates, social media posts, and everything in between are what build connections in our communities. By sharing our technologies, we aim to move the industry forward while allowing other companies and individuals to use our solutions to scale more quickly and build great products.
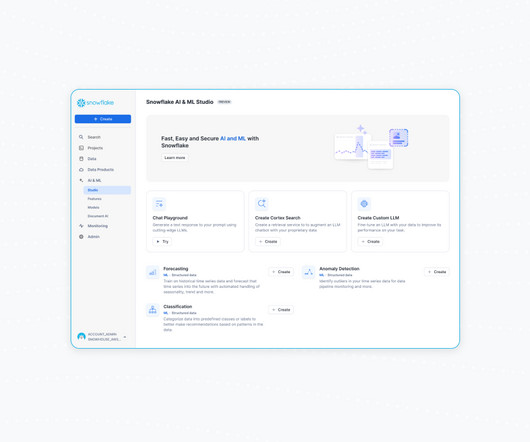
Snowflake Cortex Search, a fully managed search service for documents and other unstructured data, is now in public preview. For document- or chunk-level access controls, you can use metadata filtering to ensure that the service only returns the results that the client is authorized to view.
Establish documentation 4. Start by creating SLAs to ensure different engineering teams and their stakeholders are confident that everyones speaking the same language, caring about the same metrics, and sharing a commitment to clearly documented expectations. Establish documentation Data products have many benefits (see above!),
Expect autonomous agents, document digestion and AI as its own killer app. And data strategy must evolve to make sure that AI initiatives are aligned with business goals and are effectively instilling a data-driven culture in the organization.
A lot of people use LangChain to do things like chatbots, answering questions, analyzing documents, and automating logic. Document loaders for processing PDFs, web pages, and other content. Document loaders for PDFs, web pages, or text files. Data Integration Document Loaders : Process text, PDFs, web pages, and more.
Documentation: Many datasets are not accompanied by clear or up-to-date documentation. And even when there is documentation, people dont read it. Within your operations, stress the need to get and read documentation. This makes de-coding the data a challenge that may prevent potentially valuable data from being usable.
Generative AI presents enterprises with the opportunity to extract insights at scale from unstructured data sources, like documents, customer reviews and images. Cortex Search can scale to millions of documents with subsecond latency, using fully managed vector embedding and retrieval.
tl;dr You may not believe it, but Nix documentation is getting better. Table of contents Overview Motivation Statistics Retrospective Thoughts on future work Acknowledgements Overview This is a retrospective of my and many other people’s work on documentation in the Nix ecosystem between October 2022 and March 2024.
Protecting sensitive or proprietary data such as source code, PII, internal documents, wikis, code bases, and other sensitive data sets, along with prompts, used to contextualize the LLMs is particularly important. Figure 1: Visual Question Answering Challenge data types and results.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content