This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You can also add metadata on models (in YAML). You have to define sources in YAML files. ℹ️ I want to mention that the dbt documentation is one of the best tools documentation out there. The documentation, as I said earlier, is top of the notch. macros — a way to create re-usable functions.
Not every solution out there is built the same, and if youve ever tried to wrangle documentation from scratch, you know how painful a clunky tool can be. Next, look for automatic metadata scanning. Its like a time machine for your documentation. Its built for large-scale metadata management and deep lineage tracking.
Unstructured text is everywhere in business: customer reviews, support tickets, call transcripts, documents. Meanwhile, operations teams use entity extraction on documents to automate workflows and enable metadata-driven analytical filtering.
Other examples include retailers who integrate product photo metadata with transaction histories to gain deeper insights of how visuals influence purchase decisions. Healthcare organizations can improve patient outcomes by correlating imaging metadata with treatment protocols and demographics. for comprehensive visual analysis.
Overall, data must be easily accessible to AI systems, with clear metadata management and a focus on relevance and timeliness. Expect autonomous agents, document digestion and AI as its own killer app.
Unlock value of unstructured documents with AI-enabled automated data extraction and integration Businesses of all kinds are flooded with documents every day — invoices, receipts, notices, forms and more — and yet getting and using the information therein remains manual, time-consuming and error-prone.
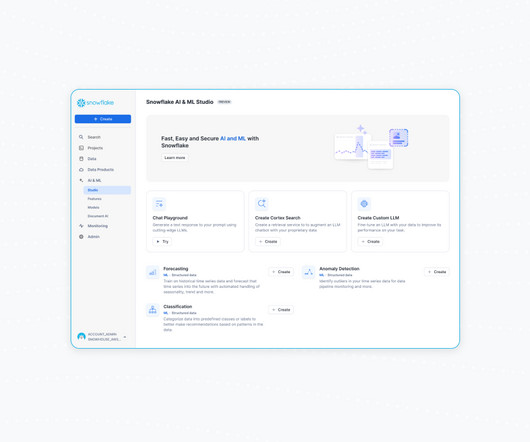
Snowflake Cortex Search, a fully managed search service for documents and other unstructured data, is now in public preview. It supports “fuzzy” search — the service takes in natural language queries and returns the most relevant text results, along with associated metadata.
With this public preview, those external catalog options are either “GLUE”, where Snowflake can retrieve table metadata snapshots from AWS Glue Data Catalog, or “OBJECT_STORE”, where Snowflake retrieves metadata snapshots directly from the specified cloud storage location. With these three options, which one should you use?
These tools can be called by LLM systems to learn about your data and metadata. and receive accurate information based on your dbt project's documentation and structure. The dbt MCP server provides access to a set of tools that operate on top of your dbt project. Business users can ask questions like "What customer data do we have?"
For more information on this and other examples please visit the Dataflow documentation page." This logic consists of the following parts: DDL code, table metadata information, data transformation and a few audit steps. Attributes are set via Metacat , which is a Netflix internal metadata management platform.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Select Star is a data discovery platform that automatically analyzes & documents your data.
That is done via a careful examination of all metadata repositories describing data sources. Once those repositories have been carefully studied, the identified data sources must be scanned by a data catalog, so that a metadata mirror of these data sources are made discoverable for the operations team.
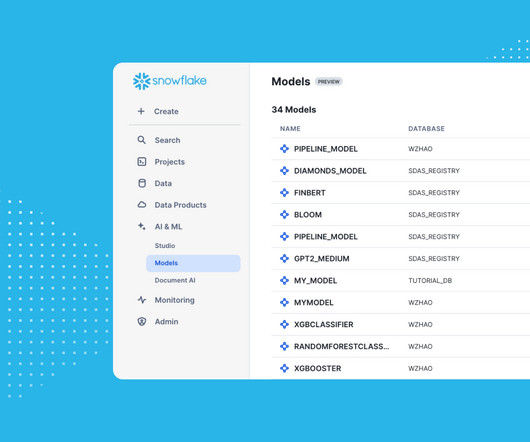
Snowpark ML Operations: Model management The path to production from model development starts with model management, which is the ability to track versioned model artifacts and metadata in a scalable, governed manner. The Snowpark Model Registry API provides simple catalog and retrieval operations on models.
When building applications on change data capture (CDC) data using Elasticsearch, you’ll want to architect the system to handle frequent updates or modifications to the existing documents in an index. When a user searches for a show, ie “political thriller”, they are returned a set of relevant results based on keywords and other metadata.
Since the previous stable version ( 0.3.1 ), efforts have been made on three principal fronts: tooling (in particular the language server), the core language semantics (contracts, metadata, and merging), and the surface language (the syntax and the stdlib). The | symbol attaches metadata to fields.
We built an asset management platform (AMP), codenamed Amsterdam , in order to easily organize and manage the metadata, schema, relations and permissions of these assets. It provides simple APIs for creating indices, indexing or searching documents, which makes it easy to integrate. are stored in secure storage layers.
The Snowflake Model Registry , in general availability, provides a centralized repository to manage all models and their related artifacts and metadata. Teams can visually interact with Feature Store objects and their metadata from a new UI (private preview) in Snowsight. Ask the Community!
Review the Upgrade document topic for the supported upgrade paths. Document the number of dev/test/production clusters. Document the operating system versions, database versions, and JDK versions. Review the JDK versions and determine if a JDK version change is needed and if so follow the documentation here to upgrade.
One reason why all the engineering documentation fails and quickly becomes outdated is that it is always written from the author's perspective. Unlike coding, we never (or rarely) apply a code review process for documentation. [link] Grab: Facilitating Docs-as-Code implementation for users unfamiliar with Markdown.
and he/she has different actions to execute (reading, calling a vision API, transform, create metadata, store them, etc…). The data domain Discovery portal with all the metadata on the data life cycle 4.Federated TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality.
Metadata Caching. This is used to provide very low latency access to table metadata and file locations in order to avoid making expensive remote RPCs to services like the Hive Metastore (HMS) or the HDFS Name Node, which can be busy with JVM garbage collection or handling requests for other high latency batch workloads. Next Steps.
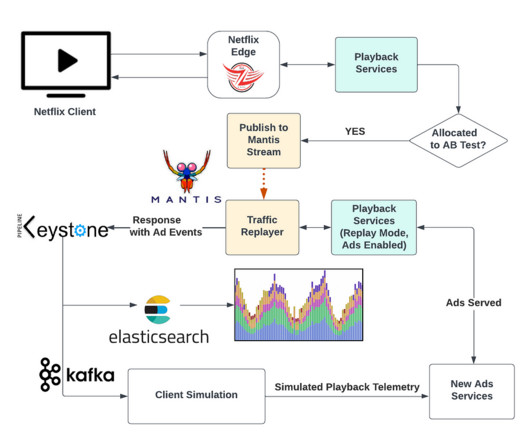
The replay traffic environment generated responses containing a standard playback manifest, a JSON document containing all the necessary information for a Netflix device to start playback. It also included metadata about ads, such as ad placement and impression-tracking events.
Not only do we have a unique vantage point into the challenges faced by data analysts, we also possess rich metadata that feeds into Snowflake’s dedicated text-to-SQL model that Copilot leverages in combination with Mistral’s technology. This vast amount of data fuels the development of Copilot, surpassing typical large language models.
The official design document for liquid clustering is here. link] Picnic: Open-sourcing dbt-score: lint model metadata with ease! The more metadata there is, the more readability of the model. It is often challenging as developers are not incentivized to produce quality metadata.
For example, customers who need a centralized store of data in large volume and variety – including JSON, text files, documents, images, and video – have built their data lake with Snowflake. For public preview or generally available features, please read the release notes and documentation to learn more and get started.
This opens new moves in the data modeler’s playbook, and can allow for fact tables to store multiple grains at once when needed dynamic schemas : since the advent of map reduce, with the growing popularity of document stores and with support for blobs in databases, it’s becoming easier to evolve database schemas without executing DML.
In the demo, you’ll see how Rockset delivers search results in 15 milliseconds over thousands of documents. Organizations have continued to accumulate large quantities of unstructured data, ranging from text documents to multimedia content to machine and sensor data. Why use vector search?
Generative AI presents enterprises with the opportunity to extract insights at scale from unstructured data sources, like documents, customer reviews and images. Cortex Search can scale to millions of documents with subsecond latency, using fully managed vector embedding and retrieval.
In this way, DotSlash simplifies the work of cross-platform releases: In this example, the workflow DotSlash runs through when executing node looks like: See the How DotSlash Works documentation for details. See the Generating DotSlash Files at Meta documentation for details. Because of how #! node --version.
We can extract documentation from them, get completion in the LSP, use nickel query , and so on. Metadata can be attached to record fields, giving them more expressive power and the ability to better describe an interface for a partial configuration. You need to provide arguments first. But query doesn’t work on functions!
The solution to discoverability and tracking of data lineage is to incorporate a metadata repository into your data platform. The metadata repository serves as a data catalog and a means of reporting on the health and status of your datasets when it is properly integrated into the rest of your tools.
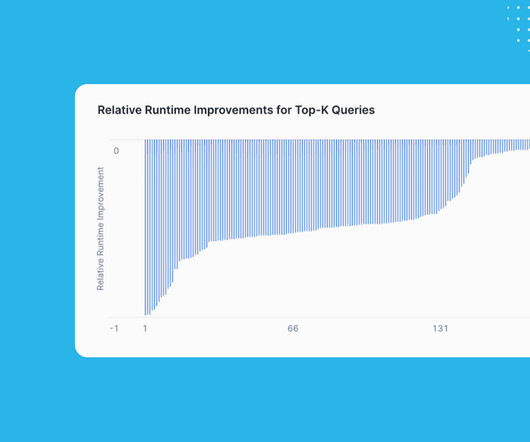
Before Snowflake starts executing the query, we look at the metadata of the partitions to determine whether the contents of a given partition are likely to end up in the final result. For a list of key performance improvements by year and month, visit Snowflake Documentation. Snowflake starts processing those partitions first.
The interface was designed such that a minimal amount of metadata was needed to construct a pipeline object which performs a given capability. The steep learning curve for developers when using streaming which required detailed documentation. We called this the Open Beta phase of the project.
It means defining that data by documenting relationships between creator and context (like customers and their orders), establishing clear business definitions (what exactly counts as an “active user”?), and maintaining metadata about data freshness, quality, and lineage (more on that in a moment).
Data Documentation 101: Why? — Marie wrote best practices for establishing complete and reliable data documentation. The first advice is about the documentation readers: data team, business users or other stakeholders. Data warehouses are mutable, this is one of the many root causes proposed by Lucas.
Then, Glue writes the job's metadata into the embedded AWS Glue Data Catalog. AWS Glue then creates data profiles in the catalog, a repository for all data assets' metadata, including table definitions, locations, and other features. Why Use AWS Glue? being data exactly matches the classifier, and 0.0 doesn't match the classifier.
Data and Metadata: Data inputs and data outputs produced based on the application logic. Also included, business and technical metadata, related to both data inputs / data outputs, that enable data discovery and achieving cross-organizational consensus on the definitions of data assets.
Atlas / Kafka integration provides metadata collection for Kafa producers/consumers so that consumers can manage, govern, and monitor Kafka metadata and metadata lineage in the Atlas UI. x, as well as documented rollback procedures to help customers with their move to CDP PvC Base, as mentioned in the blog introduction. .
Finally, not to be overlooked are the metadata and documentation required to ensure the product can easily be used. Metadata and data should be easy to find for both humans and computers. Machine-readable metadata is essential for automatic discovery of data sets and services.
In this blog, we’ll highlight the key CDP aspects that provide data governance and lineage and show how they can be extended to incorporate metadata for non-CDP systems from across the enterprise. Atlas provides open metadata management and governance capabilities to build a catalog of all assets, and also classify and govern these assets.
Fine-grained personal access token that allows Read access to metadata and Read and Write access to code and commit statuses. For more information, explore our developer documentation on the new version control REST APIs for Git. vcs/git/config/create REST API v2.0 We'd love to hear your feedback.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. images, documents, etc.) Atlan is the metadata hub for your data ecosystem. images, documents, etc.) Stale dashboards?
Expanding this type-based schema with some additional metadata allowed us to autogenerate the UI for whatever configuration parameters a component needs. To do so, we generalized what we alreadyhad: The components that we built already had a schema defining what input they needed. To configure pages, we already had our own DSL.
Customers who have chosen Google Cloud as their cloud platform can now use CDP Public Cloud to create secure governed data lakes in their own cloud accounts and deliver security, compliance and metadata management across multiple compute clusters. Google Cloud Storage buckets – in the same subregion as your subnets .
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content