


Evaluating Methods for Calculating Document Similarity
KDnuggets
DECEMBER 21, 2023
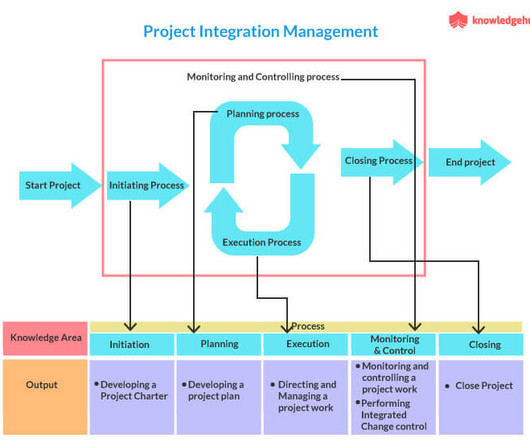
The blog covers methods for representing documents as vectors and computing similarity, such as Jaccard similarity, Euclidean distance, cosine similarity, and cosine similarity with TF-IDF, along with pre-processing steps for text data, such as tokenization, lowercasing, removing punctuation, removing stop words, and lemmatization.








































Let's personalize your content