This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Your search for Apache Kafka interview questions ends right here! Let us now dive directly into the Apache Kafka interview questions and answers and help you get started with your Big Data interview preparation! What are topics in Apache Kafka? A stream of messages that belong to a particular category is called a topic in Kafka.
If you’re looking for everything a beginner needs to know about using Apache Kafka for real-time data streaming, you’ve come to the right place. This blog post explores the basics about Apache Kafka and its uses, the benefits of utilizing real-time data streaming, and how to set up your data pipeline. Let's dive in.
Developers can download code bindings in their preferred language, which speeds up development and reduces errors in event processing logic. Sources include DynamoDB Streams, Kinesis, Amazon MQ, Amazon MSK, self-managed Kafka, and Amazon SQS. Filtering: Apply patterns to select specific events for processing.
Scala is 10x faster than Python , produces a smaller code size than Java, gives more robust programming capabilities than C++, and combines the advantages of two major programming paradigms, making it unique from several other programming languages. Scala is a general-purpose programming language released in 2004 as an improvement over Java.
Why do data scientists prefer Python over Java? Java vs Python for Data Science- Which is better? Which has a better future: Python or Java in 2023? This blog aims to answer all questions on how Java vs Python compare for data science and which should be the programming language of your choice for doing data science in 2023.
Use Kafka for real-time data ingestion, preprocess with Apache Spark, and store data in Snowflake. This architecture shows that simulated sensor data is ingested from MQTT to Kafka. The data in Kafka is analyzed with Spark Streaming API and stored in a column store called HBase.
Hands-on Flink Workshop: Implement Stream Processing | Register Now Login Contact Us Why Confluent Confluent vs. Apache Kafka® Learn more about how Confluent differs from Apache Kafka For Practitioners Discover the platform that is built and designed for those who build For Executives Unlock the value of data across your business Our Customers Explore (..)
Source Code: Build a Similar Image Finder Top 3 Open Source Big Data Tools This section consists of three leading open-source big data tools- Apache Spark , Apache Hadoop, and Apache Kafka. It provides high-level APIs for R, Python, Java, and Scala. Additionally, you will learn how to integrate Spark with Kafka and MongoDB.
You can retrieve the required content and can format and convert the content to download or display on the webpage. Transform into an AWS guru with these beginner-friendly projects - Here is your AWS Projects for Beginners PDF Free to Download ! You can begin with a simple app, such as a MI calculator.
Below are some fun Sci-Kit learn projects that will show you how to use the Scikit Learn library to build decision tree models or gradient boosting models like XGBoost- Loan Eligibility Prediction Project using Machine learning Build a Customer Churn Prediction Model using Decision Trees Scrapy With over 190,207 weekly downloads and 43.3k
How cool would it be to build your own burglar alarm system that can alert you before the actual event takes place simply by using a few network-connected cameras and analyzing the camera images with Apache Kafka ® , Kafka Streams, and TensorFlow? Uploading your images into Kafka. Setting up your burglar alarm.
A French commission released a 130 pages report untitled "Our AI: our ambition for France" You can download the French version and an English 16 pages summary. Obviously Benoit prefers Kestra, at the expense of writing YAML and running a Java application. Unlocking Kafka's potential: tackling tail latency with eBPF.
Apache-Kafka ® -based applications stand out for their ability to decouple producers and consumers using an event log as an intermediate layer. This article describes how to instrument Kafka-based applications with distributed tracing capabilities in order to make dataflows between event-based components more visible.
Only a little more than one month after the first release, we are happy to announce another milestone for our Kafka integration. Today, you can grab the Kafka Connect Neo4j Sink from Confluent Hub. . Neo4j extension – Kafka sink refresher. Testing the Kafka Connect Neo4j Sink. curl -X POST [link]. jar -f AVRO -e 100000.
In anything but the smallest deployment of Apache Kafka ® , there are often going to be multiple clusters of Kafka Connect and KSQL. Kafka Connect rebalances when connectors are added/removed, and this can impact the performance of other connectors on the same cluster. Streaming data into Kafka with Kafka Connect.
One of the most common integrations that people want to do with Apache Kafka ® is getting data in from a database. The existing data in a database, and any changes to that data, can be streamed into a Kafka topic. Here, I’m going to dig into one of the options available—the JDBC connector for Kafka Connect. Introduction.
Following part 1 and part 2 of the Spring for Apache Kafka Deep Dive blog series, here in part 3 we will discuss another project from the Spring team: Spring Cloud Data Flow , which focuses on enabling developers to easily develop, deploy, and orchestrate event streaming pipelines based on Apache Kafka ®. Command Line Shell.
As discussed in part 2, I created a GitHub repository with Docker Compose functionality for starting a Kafka and Confluent Platform environment, as well as the code samples mentioned below. We used Groovy instead of Java to write our UDFs, so we’ve applied the groovy plugin. gradlew composeUp. Note: When executing./gradlew
Previously in 3 Ways to Prepare for Disaster Recovery in Multi-Datacenter Apache Kafka Deployments , we provided resources for multi-datacenter designs, centralized schema management, prevention of cyclic repetition of messages, and automatic consumer offset translation to automatically resume applications.
When managing Apache Kafka ® clusters at scale, tasks that are simple on small clusters turn into significant burdens. In previous versions of Control Center, you could view and download broker configurations, which was good as far as it went. Relatedly, KIP-226 enabled dynamic broker reconfiguration since Apache Kafka 1.1.
Kafka can continue the list of brand names that became generic terms for the entire type of technology. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. What is Kafka?
Here in part 4 of the Spring for Apache Kafka Deep Dive blog series, we will cover: Common event streaming topology patterns supported in Spring Cloud Data Flow. Create and manage event streaming pipelines, including a Kafka Streams application using Spring Cloud Data Flow. java -jar spring-cloud-dataflow-shell-2.1.0.RELEASE.jar.
It offers a slick user interface for writing SQL queries to run against real-time data streams in Apache Kafka or Apache Flink. They no longer have to depend on any skilled Java or Scala developers to write special programs to gain access to such data streams. . SQL Stream Builder continuously runs SQL via Flink.
This is the first installment in a short series of blog posts about security in Apache Kafka. Secured Apache Kafka clusters can be configured to enforce authentication using different methods, including the following: SSL – TLS client authentication. We use the kafka-console-consumer for all the examples below.
The blog posts How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka and Using Apache Kafka to Drive Cutting-Edge Machine Learning describe the benefits of leveraging the Apache Kafka ® ecosystem as a central, scalable and mission-critical nervous system. For now, we’ll focus on Kafka.
In the previous posts in this series, we have discussed Kerberos , LDAP and PAM authentication for Kafka. In this post we will look into how to configure a Kafka cluster and client to use a TLS client authentication. TLS is assumed to be enabled for the Apache Kafka cluster, as it should be for every secure cluster.
Distributed transactions are very hard to implement successfully, which is why we’ll introduce a log-inspired system such as Apache Kafka ®. Building an indexing pipeline at scale with Kafka Connect. Moving data into Apache Kafka with the JDBC connector. For this use case, we are going to use it as a source connector.
When managing Apache Kafka ® clusters at scale, tasks that are simple on small clusters turn into significant burdens. In previous versions of Control Center, you could view and download broker configurations, which was good as far as it went. Relatedly, KIP-226 enabled dynamic broker reconfiguration since Apache Kafka 1.1.
In part 1 , we discussed an event streaming architecture that we implemented for a customer using Apache Kafka ® , KSQL from Confluent, and Kafka Streams. In part 3, we’ll explore using Gradle to build and deploy KSQL user-defined functions (UDFs) and Kafka Streams microservices. gradlew composeUp. The KSQL pipeline flow.
How we use Apache Kafka and the Confluent Platform. Apache Kafka ® is the central data hub of our company. At TokenAnalyst, we’re using Kafka for ingestion of blockchain data—which is directly pushed from our cluster of Bitcoin and Ethereum nodes—to different streams of transformation and loading processes.
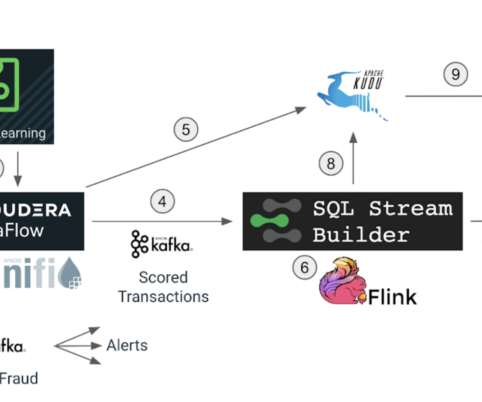
In this blog we will explore how we can use Apache Flink to get insights from data at a lightning-fast speed, and we will use Cloudera SQL Stream Builder GUI to easily create streaming jobs using only SQL language (no Java/Scala coding required). It provides flexible and expressive APIs for Java and Scala. Use case recap. Apache Flink.
Why do data scientists prefer Python over Java? Java vs Python for Data Science- Which is better? Which has a better future: Python or Java in 2021? This blog aims to answer all questions on how Java vs Python compare for data science and which should be the programming language of your choice for doing data science in 2021.
million downloads, 21,000 GitHub stars, and 1,600 code contributions. 2: The majority of Flink shops are in earlier phases of maturity We talked to numerous developer teams who had migrated workloads from legacy ETL tools, Kafka streams, Spark streaming, or other tools for the efficiency and speed of Flink. billion events/s.
In particular, the management and monitoring capabilities that we added to Confluent Control Center have evolved it into an indispensable tool for anyone working with Apache Kafka ®. Part 2: Managing Kafka Configurations at Scale with Confluent Control Center. Download Confluent Platform version 5.2
When it comes to the emerging serverless world, It makes sense to validate how Apache Kafka ® fits in considering that it is mission critical in 90 percent of companies. By persisting the streams in Kafka we then have a record of all system activity (a source of truth), and also a mechanism to drive reactions.
In 2015, Cloudera became one of the first vendors to provide enterprise support for Apache Kafka, which marked the genesis of the Cloudera Stream Processing (CSP) offering. Today, CSP is powered by Apache Flink and Kafka and provides a complete, enterprise-grade stream management and stateful processing solution. Who is affected?
HELK is a free threat hunting platform built on various components including the Elastic stack, Apache Kafka ® and Apache Spark. WHERE PARENT_PROCESS_PATH LIKE '%WmiPrvSE.exe%'; The results of the KSQL query can be written to a Kafka topic, which in turn can drive real-time monitoring or alerting dashboards and applications.
In particular, the management and monitoring capabilities that we added to Confluent Control Center have evolved it into an indispensable tool for anyone working with Apache Kafka ®. Part 2: Managing Kafka Configurations at Scale with Confluent Control Center. Download Confluent Platform version 5.2
However, as real-time queries are typically executed by those with unique skills like Scala or Java, there could be a mismatch between expertise and increasing workloads. If you want to learn more about SQL Stream Builder , download our Tech Brief or the datasheet. . For a live demo of this product, attend our webinar on 2nd June.
Your search for Apache Kafka interview questions ends right here! Let us now dive directly into the Apache Kafka interview questions and answers and help you get started with your Big Data interview preparation! How to study for Kafka interview? What is Kafka used for? What are main APIs of Kafka?
Download and use a sample application . You either clone this repository to your machine or download and use these sample applications. . Apache HBase (NoSQL), Java, Maven: Read-Write. Apache Phoenix (SQL), Java, Dropwizard: Stock ticker. Apache Phoenix (SQL), Java, Maven: Read-Write. openjdk". $ Password: **.
To avoid burdening mainframe databases with constant I/O instructions and acknowledgments and prevent latency issues, best practices call for the use of event streaming platforms like Kafka, Amazon Kinesis, Rabbit MQ, or others. Download Best Practice 1. Download our free e-book, Best Practices for Mainframe Modernization.
Integrations : Whylogs supports integrations with a variety of tools, frameworks and languages — Spark, Kafka, Pandas, MLFlow, GitHub actions, RAPIDS, Java, Docker, AWS S3 and more. GitHub - sarthak-sarbahi/whylogs-pyspark Start by downloading the sample data (CSV) from here. This is all we need to know about whylogs.
Hadoop common provides all Java libraries, utilities, OS level abstraction, necessary Java files and script to run Hadoop, while Hadoop YARN is a framework for job scheduling and cluster resource management. Skybox uses Hadoop to analyse the large volumes of image data downloaded from the satellites.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content