This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Meta is always looking for ways to enhance its access tools in line with technological advances, and in February 2024 we began including data logs in the Download Your Information (DYI) tool. Data logs include things such as information about content you’ve viewed on Facebook. What are data logs?
But this can be many megabytes (or even gigabytes) in size because DWARF debug data contains much more than the symbol information. This data needs to be downloaded then parsed. Strobelight also delays symbolization until after profiling and stores rawdata to disk to prevent memory thrash on the host.
Extract and Load This phase includes VDK jobs calling the Europeana REST API to extract rawdata. This operation is a batch process because it downloadsdata only once and does not require streamlining. Please note that you need a free API key to downloaddata from Europeana. link] Summary Congratulations!
Ingestion Pipelines : Handling data from cloud storage and dealing with different formats can be efficiently managed with the accelerator. Feature Engineering : Creating and deriving features from rawdata to enhance model performance in machine learning tasks is another area where the Snowpark Migration Accelerator excels.
For the code to work, the data in it’s CSV format should be placed into the data subfolder. The dataset can be downloaded from: [link]. Data Ingestion. The rawdata is in a series of CSV files. Install the requirements from a terminal session with: “`code. pip install -r requirements.txt.
And even when we manage to streamline the data workflow, those insights aren’t always accessible to users unfamiliar with antiquated business intelligence tools. That’s why ThoughtSpot and Fivetran are joining forces to decrease the amount of time, steps, and effort required to go from rawdata to AI-powered insights.
The goal of dimensional modeling is to take rawdata and transform it into Fact and Dimension tables that represent the business. Choose one, and download and install the database using one of the following links: Download DuckDB Download PostgreSQL You must have Python 3.8
The full pipeline is broken out into two stages, the first takes in the initial data set and filters for recent fiction (within the last 10 years). This resulted in about 250k books, and around 70k with cover images available to download and embed in the second stage. First we pull out the relevant columns from the rawdata file.
Empowering Data-Driven Decisions: Whether you run a small online store or oversee a multinational corporation, the insights hidden in your data are priceless. Airbyte ensures that you don’t miss out on those insights due to tangled data integration processes. Download Docker Desktop from here as a prerequisite.
Informatica Informatica is a leading industry tool used for extracting, transforming, and cleaning up rawdata. Features: Gives accurate insights and transforms rawdata Good data maintenance and monitoring Automated deployments Can execute multiple processes simultaneously 7.
According to the 2023 Data Integrity Trends and Insights Report , published in partnership between Precisely and Drexel University’s LeBow College of Business, 77% of data and analytics professionals say data-driven decision-making is the top goal of their data programs. That’s where data enrichment comes in.
It was released as a standalone product in July 2015 after adding more features including enterprise-level data connectivity and security options, apart from its original Excel features like Power Query, Power Pivot, and Power View. Microsoft developed it and combines business analytics, data visualization, and best practices.
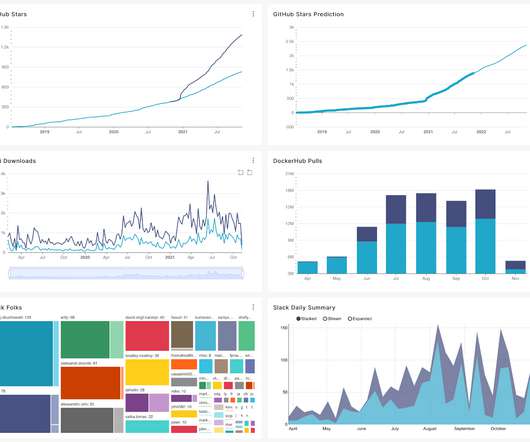
I can visit the GitHub page for a project and see the number of stars, or look at a package on PyPI when I need to know how many downloads it's gotten. You need to collect the data that's important to your business and study how it changes over time. It used to be that when you wanted to consume a bit of tech, you'd download a file.
A big challenge is to support and manage multiple semantically enriched data models for the same underlying data, e.g., into a graph data model to trace value flow or into a MapReduce-compatible data model of the UTXO-based Bitcoin blockchain.
The specific graphical techniques used in EDA tasks are quite simple, for example: Plotting rawdata to gain relevant insight. Simple statistics, such as mean and standard deviation plots, are plotted on rawdata. For better results, concentrate the analysis on specific sections of the data.
The same relates to those who buy annotated sound collections from data providers. But if you have only rawdata meaning recordings saved in one of the audio file formats you need to get them ready for machine learning. Audio data labeling. Building an app for snore and teeth grinding detection.
DE Zoomcamp 2.2.1 – Introduction to Workflow Orchestration Following last weeks blog , we move to data ingestion. We already had a script that downloaded a csv file, processed the data and pushed the data to postgres database. This week, we got to think about our data ingestion design.
or later Visual C++ Redistributable for Visual Studio 2017 or later Downloading and Installing DAX Studio To download and install DAX Studio, follow these steps: Go to the DAX Studio website at [link]. Click on the Download button on the home page. Click on the Installer link to download the DAX Studio installer.
Knowing data lineage inherently increases your level of trust in the reporting you use to make the right decisions. The dbt DAG has long served as the map of your data flows, tracing the flow from rawdata to ready-to-query data mart. Look at that lineage!
But this data is not that easy to manage since a lot of the data that we produce today is unstructured. In fact, 95% of organizations acknowledge the need to manage unstructured rawdata since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses.
As enterprise usage of data analytics grows, the field has become a significant area of IT expenditure. The collection and preparation of data used for analytics are achieved by building data pipelines that ingest rawdata and transform it into useful formats leveraging cloud data platforms like Snowflake, Databricks, and Google BigQuery.
While the numbers are impressive (and a little intimidating), what would we do with the rawdata without context? The tool will sort and aggregate these rawdata and transport them into actionable, intelligent insights. This is made possible by automated data extraction from servers, computers, and clouds.
Tableau Prep has brought in a new perspective where novice IT users and power users who are not backward faithfully can use drag and drop interfaces, visual data preparation workflows, etc., simultaneously making rawdata efficient to form insights. Find the installer on the Product Downloads and Release Notes page.
There’s also some static reference data that is published on web pages. ?After Wrangling the data. With the rawdata in Kafka, we can now start to process it. Since we’re using Kafka, we are working on streams of data. After we scrape these manually, they are produced directly into a Kafka topic.
A wholesale migration delivered in months In 2020, C&A explored Gartner’s Magic Quadrant in search of a data platform that would allow it to reduce costs and complexity, scale with growth, and put data to work in a more meaningful way. All the necessary data for our loyalty program was made available in record time,” said Bauer.
Using Hive, developers can connect.xls files to Hadoop and download the data for analysis or they can even run reports from BI tool. The end users of Hive don’t have to bother about writing a Java MapReduce code nor do they have to worry about - whether the data is coming from a table.
Keeping data in data warehouses or data lakes helps companies centralize the data for several data-driven initiatives. While data warehouses contain transformed data, data lakes contain unfiltered and unorganized rawdata. Download the dataset and store it in HDFS.
The rawdata of the performance tests can be found on GitHub or online via the background tab. When interoperability with Java and Confluent Schema Registry is not required, there are many other options that can be used for data serialization. Every 20 seconds, parts of the system are measured for CPU and memory use.
They simplify data processing for our brains and give readers a quick overview of past, present, and future performance by helping the user to visualize otherwise complex and weighty rawdata. Step 1: Integrate your data You must first gather rawdata and clean it up so it is analytics-ready before you can build any dashboards.
From RawData to Insights: Simplifying Data Validation and Enrichment Businesses that want to be more data-driven are increasingly in need of data that provides answers to their everyday questions. Ready to learn more about data integrity and ESG now? And, see examples of big real-world results.
Of high value to existing customers, Cloudera’s Data Warehouse service has a unique, separated architecture. . Cloudera’s Data Warehouse service allows rawdata to be stored in the cloud storage of your choice (S3, ADLSg2). Your data warehouse is ready. Architecture overview. Separate storage.
Some of the most significant ones are: Mining data: Data mining is an essential skill expected from potential candidates. Mining data includes collecting data from both primary and secondary sources. Data organization: Organizing data includes converting the rawdata into meaningful and beneficial forms.
To start this machine learning project, download the Credit Risk Dataset. Load the dataset into a data frame and remove rows of data NaN values. You can download the Brazilian Public Dataset to get started. Also, convert the categorical values into numerical values using Label encoding.
In this post, we’ll look at 7 essential data quality tests you need right now to validate your data, plus some of the ways you can apply those tests today to start building out your data quality motion. Download our Data Quality Testing 101 eBook So, what is data quality testing anyway?
Embeddings are numerical representations of words, phrases, and other data forms.Now, any kind of rawdata can be processed through an AI-powered embedding model into embeddings as shown in the picture below. Scroll to the bottom and choose File Upload under Sample Data to upload your data. Click on Start.
Within no time, most of them are either data scientists already or have set a clear goal to become one. Nevertheless, that is not the only job in the data world. And, out of these professions, this blog will discuss the data engineering job role. Upload it to Azure Data lake storage manually.
We will now describe the difference between these three different career titles, so you get a better understanding of them: Data Engineer A data engineer is a person who builds architecture for data storage. They can store large amounts of data in data processing systems and convert rawdata into a usable format.
Data Lake vs Data Warehouse - Data Timeline Data lakes retain all data, including data that is not currently in use. Hence, data can be kept in data lakes for all times, to be usfurther analyse the data. Rawdata is allowed to flow into a data lake, sometimes with no immediate use.
ButterFree : A tool to build feature stores to help transform rawdata into feature stores. Retrieving images/analyses from Jupyter Notebooks to a presentation can be a tedious process prone to errors. However, there are ways to speed up the process of EDA effectively.
To build such ML projects, you must know different approaches to cleaning rawdata. You can download the Yelp dataset that has around 8,635,403 reviews from 160,585 businesses with 200,000 pictures. Retailers like Walmart, IKEA, Big Basket, Big Bazaar leverage sales forecasting for sale predictions of product requirements.
This decision is rarely an easy one – while customers of the data team often say they want access to rawdata, they usually mean they want access to highly curated, trustworthy data delivered in a way they can easily manipulate. Self-serve solutions (e.g.
You can start off with the 12/768 (BERT-Base) model, which can be downloaded from this link - [link] 5. One possible way of achieving this is training a CNN with the MFCC spectrograms obtained from the rawdata. Developing your own intent recognition system will, therefore, be a brilliant project to undertake.
Encoder Network Purpose : Encodes the input data xx into a latent representation zz by learning the parameters μencodermu_{text{encoder}} and σencodersigma_{text{encoder}} of the approximate posterior distribution q(z∣x)q(z|x). Architecture : Input: Rawdata xx (e.g., image pixels or text embeddings).
Data cleansing does not involve deleting any existing information from the database, it just enhances the quality of data so that it can be used for analysis. Here are some solved data cleansing code snippets that you can use in your interviews or projects. Involves analysing rawdata from existing datasets.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content