This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A few months ago I wrote a blog post about event skew and how dangerous it is for a stateful streaming job. Since it was a high-level explanation, I didn't cover Apache Spark Structured Streaming deeply at that moment. Now the watermark topic is back to my learning backlog and it's a good opportunity to return to the event skew topic and see the dangers it brings for Structured Streaming stateful jobs.
Y Combinator founder Paul Graham advises startup founders to live in the future, then build whats missing. I had the privilege of glimpsing the future through a series of interviews with investors on the bleeding edge of the AI landscape. Insights from these candid conversations laid the foundation for Startup 2025: Building a Business in the Age of AI, the AI startup report that Snowflake is publishing today.
The Critical Role of AI Data Engineers in a Data-Driven World How does a chatbot seamlessly interpret your questions? How does a self-driving car understand a chaotic street scene? The answer lies in unstructured data processing—a field that powers modern artificial intelligence (AI) systems. Unlike neatly organized rows and columns in spreadsheets, unstructured data—such as text, images, videos, and audio—requires advanced processing techniques to derive meaningful insights.
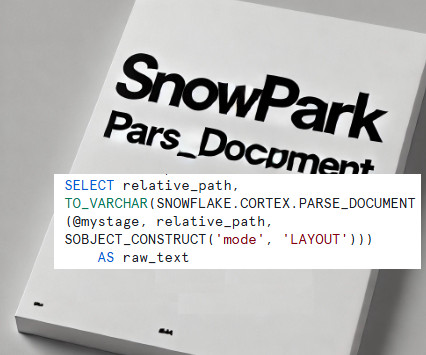
Read Time: 2 Minute, 33 Second Snowflakes PARSE_DOCUMENT function revolutionizes how unstructured data, such as PDF files, is processed within the Snowflake ecosystem. Traditionally, this function is used within SQL to extract structured content from documents. However, Ive taken this a step further, leveraging Snowpark to extend its capabilities and build a complete data extraction process.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Rust is a systems programming language that offers high performance and safety. Python programmers will find Rust's syntax familiar but with more control over memory and performance.
DareData will close 2024 with a 5% revenue growth compared to 2023. At first glance, given the rapid growth in our market, one might be tempted to classify this year as underwhelming. However, 2024 has been a transformative year for us. We started the year as a 100% consulting business. Consulting is highly dependent on people, and in small boutique firms like ours, this often means being heavily reliant on the partners.
Over the last three geospatial-centric blog posts, weve covered the basics of what geospatial data is, how it works in the broader world of data and how it specifically works in Snowflake based on our native support for GEOGRAPHY , GEOMETRY and H3. Those articles are great for dipping your toe in, getting a feel for the water and maybe even wading into the shallow end of the pool.
Large-scale computation is a major back end and infrastructure challenge for Uber to solve as we scale. We applied a compute engine called Ray in Ubers marketplace to improve computation efficiency and engineering productivity.
Imagine a world where you could simply tell your data infrastructure what you want it to achieve, rather than meticulously configuring every detail. This is precisely what Jeff Chou, Co-founder and CEO of Sync, discussed in the latest daily.dev webinar. This innovative concept is being made real through Gradient, the AI agent for data infrastructure from Sync.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Over the last three geospatial-centric blog posts, weve covered the basics of what geospatial data is, how it works in the broader world of data and how it specifically works in Snowflake based on our native support for GEOGRAPHY , GEOMETRY and H3. Those articles are great for dipping your toe in, getting a feel for the water and maybe even wading into the shallow end of the pool.
With the ever-growing focus on GenAI, many legacy BI tools have failed to invest in the analyst. By focusing solely on AI experiences for business teams, theyve alienated data teams, relegating analysts to disjointed tools and data silos. When in reality, businesses still need people who can help decision-makers assess messy data to diagnose and evaluate business problems.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content