This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We are excited to share our latest research paper Retrieve, Annotate, Evaluate, Repeat — Leveraging Multimodal LLMs for Large-Scale Product Retrieval Evaluation. We introduce a novel approach to large-scale product retrieval evaluation using Multimodal Large Language Models (MLLMs). Evaluated on 20,000 examples, our method shows how MLLMs can help automate the relevance assessment of retrieved products, achieving levels of accuracy comparable to human annotators and enabling scalable evaluation
Why Future-Proofing Your Data Pipelines Matters Data has become the backbone of decision-making in businesses across the globe. The ability to harness and analyze data effectively can make or break a company’s competitive edge. But when data processes fail to match the increased demand for insights, organizations face bottlenecks and missed opportunities.
After a couple of years recapping the excitement of the Snowflake and Databricks conference keynotes, it was beyond time to give the same treatment to the fourth annual IMPACT conference. So let’s take a closer look at the keynote delivered by Monte Carlo co-founder and chief technology officer, Lior Gavish, as he took the virtual stage to share the “vision and mission driving Monte Carlo into 2025.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
Check out these 5 KDnuggets cheat sheets designed for the data science beginner, covering from introductory coding through to data cleaning, exploration, manipulation, and modeling.
When the Generative AI boom first ignited, every enterprise rushed to deploy the technology. For many, that excitement remains. But companies are also.
Key Takeaways: Automation adoption is gaining momentum as a core component of digital transformation strategies – but integration and multi-dimensional complexity remain top challenges. Most companies are now using SAP ® S/4HANA, which significantly affects how they use their SAP ® ERP system and the software client user interfaces they choose to deploy.
Many AI use cases now depend on transforming unstructured inputs into structured data. Developers are increasingly relying on LLMs to extract structured data.
Databricks Lakehouse is an open data management architecture which combines the scalability, cost-effectiveness, and flexibility of data lakes with the data management and ACID transactions of data warehouses. Databricks Lakehouse is the best of both worlds of data lakes and data warehouses. It enables machine learning and business intelligence on all data with more reliability.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Providence Health's extensive network spans 50+ hospitals and numerous other facilities across multiple states, presenting many challenges in predicting patient volume and daily.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



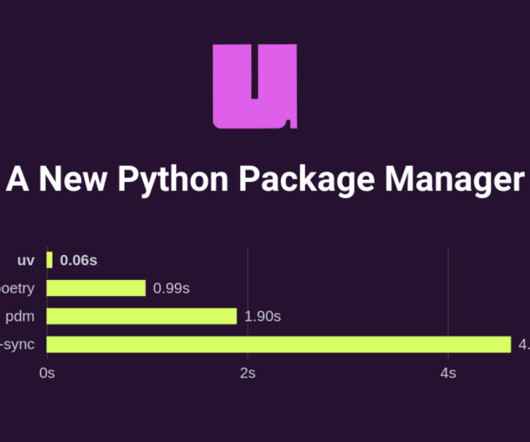



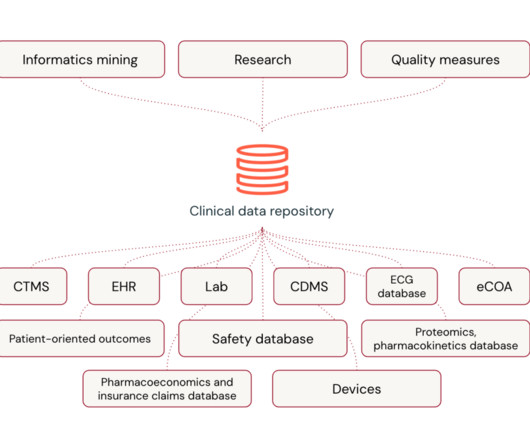






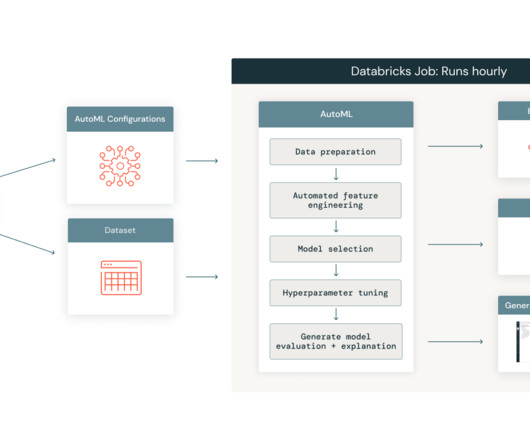






Let's personalize your content