This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Are you an aspiring data scientist or early in your data science career? If so, you know that you should use your programming, statistics, and machine learning skills—coupled with domain expertise—to use data to answer business questions. To succeed as a data scientist, therefore, becoming proficient in coding is essential. Especially for handling and analyzing.
There’s no question which technology everyone’s talking about in retail. Generative AI continues to promote incredible levels of interest with its promise of next-level productivity and new kinds of employee and customer experience. It’s all happening at light speed. When ChatGPT burst onto the scene, it gained hundreds of millions of users in a matter of months.
The launch of foundational models, popularly called Large Language Models (LLMs), created new ways of working – not just for the enterprises redefining the legacy ways of doing business, but also for the developers leveraging these models. The remarkable ability of these models to comprehend and respond in human-like language has given rise to.
The journey from a great idea for a Generative AI use case to deploying it in a production environment often resembles navigating a maze. Every turn presents new challenges—whether it’s technical hurdles, security concerns, or shifting priorities—that can stall progress or even force you to start over. Cloudera recognizes the struggles that many enterprises face when setting out on this path, and that’s why we started building Accelerators for ML Projects (AMPs).
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
Traditional static charts are useful, but interactive visuals offer more flexibility. They allow users to explore data, zoom in on details, and see changes over time. R has several packages that can be used to create interactive visualizations like tables, charts and maps. Getting Started To create interactive visualizations in R, you need.
Healthcare services are no longer limited to one-size-fits-all approaches applicable to every patient. Instead, there has been a gradual shift towards more individualized and patient-centered solutions. Accordingly, personalized healthcare aims to provide patients with treatments and medical assistance that are tailored to their unique health status, medical history, and lifestyle: simply put, tailored to their.
Healthcare services are no longer limited to one-size-fits-all approaches applicable to every patient. Instead, there has been a gradual shift towards more individualized and patient-centered solutions. Accordingly, personalized healthcare aims to provide patients with treatments and medical assistance that are tailored to their unique health status, medical history, and lifestyle: simply put, tailored to their.
Monte Carlo, the AI-first data observability platform, announced Tim Miller as the company’s first Chief Revenue Officer as it continues to bolster its leadership team. He will lead the company’s go-to-market operations worldwide, including business development, sales, and customer success. In this new role, Miller will drive Monte Carlo’s revenue strategies, operations, and growth initiatives, including the expansion of the company’s footprint across the enterprise and strategic markets.
Once again, I want to thank the Data Heros community. Last Friday, we discussed the challenges in bulk discovery and anonymization processes in data warehouses. The collective design choices and ideas lead to a comprehensive overview of thinking about designing data infrastructure with a privacy-first approach. Why care about privacy? Privacy and access management within data infrastructure is not just a best practice; it's a necessity.
Dear ThoughtSpot Community, I couldn't be more thrilled to announce that we're welcoming our new CEO to the ThoughtSpot family: Ketan Karkhanis. This marks a significant milestone in our journey, and I wanted to share why this is such an exciting development for all of us. A Time of Rapid Growth and Unprecedented Opportunity From day one, we have been focused on our mission—to make the world more fact-driven.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
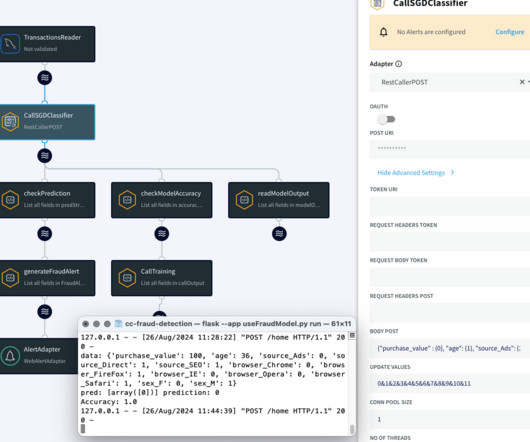
In today’s fast-paced financial landscape, detecting transaction fraud is essential for protecting institutions and their customers. This article explores how to leverage Striim and SGDClassifier to create a robust fraud detection system that utilizes real-time data streaming and machine learning. Problem Transaction fraud detection is a critical responsibility for the IT teams of financial institutions.
Key Takeaways: Trusted AI requires data integrity. For AI-ready data, focus on comprehensive data integration, data quality and governance, and data enrichment. A structured, business-first approach to AI is essential. Start with clear business use cases and ensure collaboration between business and IT teams for the greatest impact. Building data literacy across your organization empowers teams to make better use of AI tools.
In today’s fast-paced financial landscape, detecting transaction fraud is essential for protecting institutions and their customers. This article explores how to leverage Striim and SDGClassifier to create a robust fraud detection system that utilizes real-time data streaming and machine learning. Problem Transaction fraud detection is a critical responsibility for the IT teams of financial institutions.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



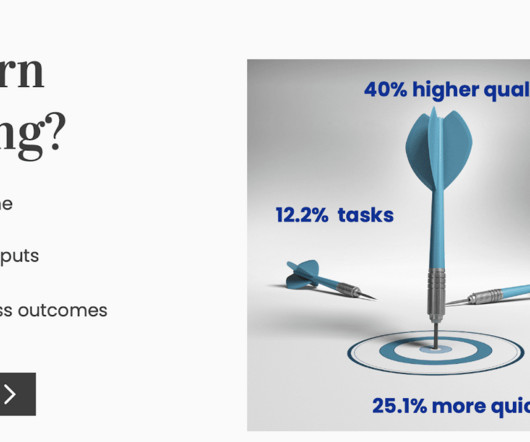


















Let's personalize your content