This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Generative AI is taking the world by storm – here’s what it means for data engineering and why data observability is critical for this groundbreaking technology to succeed. Maybe you’ve noticed the world has dumped the internet, mobile, social, cloud and even crypto in favor of an obsession with generative AI. But is there more to generative AI than a fancy demo on Twitter?
Introduction In today’s data-driven world, organizations across industries are dealing with massive volumes of data, complex pipelines, and the need for efficient data processing. Traditional data engineering solutions, such as Apache Airflow, have played an important role in orchestrating and controlling data operations in order to tackle these difficulties.
👋 Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. We cover one out of four topics in today’s subscriber-only The Scoop issue. If you’re not yet a full subscriber, you missed this week’s deep-dive on Agoda’s private cloud setup. To get the full issues, twice a week, subscribe here.
Summary Data transformation is a key activity for all of the organizational roles that interact with data. Because of its importance and outsized impact on what is possible for downstream data consumers it is critical that everyone is able to collaborate seamlessly. SQLMesh was designed as a unifying tool that is simple to work with but powerful enough for large-scale transformations and complex projects.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
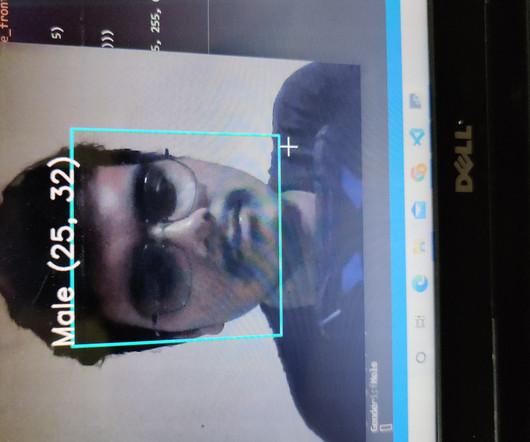
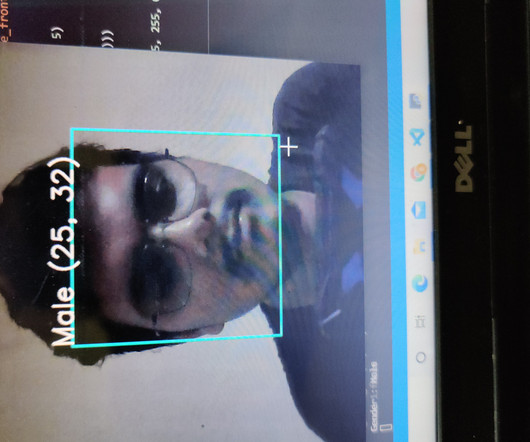
Artificial Intelligence has been witnessing monumental growth in bridging the gap between the capabilities of humans and machines. Researchers and enthusiasts alike, work on numerous aspects of the field to make amazing things happen. One of many such areas is the domain of Computer Vision.
Introduction We are thrilled to unveil the English SDK for Apache Spark, a transformative tool designed to enrich your Spark experience. Apache Spark™.
ChatGPT and data streaming can work together for any company. Learn a basic framework for using GPT-4 and streaming to build a real-world production application.
ChatGPT and data streaming can work together for any company. Learn a basic framework for using GPT-4 and streaming to build a real-world production application.
Introduction Meet Tajinder, a seasoned Senior Data Scientist and ML Engineer who has excelled in the rapidly evolving field of data science. Tajinder’s passion for unraveling hidden patterns in complex datasets has driven impactful outcomes, transforming raw data into actionable intelligence. In this article, we explore Tajinder’s inspiring success story.
👋 Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover topics related to Big Tech and startups through the lens of engineering managers and senior engineers. In this article, we cover one out of four topics from today’s subscriber-only The Scoop issue. To get full issues twice a week, subscribe here.
By Jennifer Shin , Tejas Shikhare , Will Emmanuel In 2022, a major change was made to Netflix’s iOS and Android applications. We migrated Netflix’s mobile apps to GraphQL with zero downtime, which involved a total overhaul from the client to the API layer. Until recently, an internal API framework, Falcor , powered our mobile apps. They are now backed by Federated GraphQL , a distributed approach to APIs where domain teams can independently manage and own specific sections of the API.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Co-authors: Shivansh Mundra , Gonzalo Aniano Porcile , Smit Marvaniya , Hany Farid A core part of what we do on the Trust Data Team at LinkedIn is create, deploy, and maintain models that detect and prevent many types of abuse. This spans the detection and prevention of fake accounts, account takeovers, and policy-violating content. We are constantly working to improve and increase the effectiveness of our anti-abuse defenses to protect the experiences of our members and customers.
1. Introduction 2. What is self-serve? 2.1. Components of a self-serve platform 3. Building a self-serve data platform 3.1. Creating dataset(s) 3.1.1. Gather requirements 3.1.2. Get data foundations right 3.2. Accessing data 3.3. Identify and remove dependencies 4. Conclusion 5. Further reading 6. References 1. Introduction Most companies want to build a self-serve data platform.
In a data-driven world, behind-the-scenes heroes like data engineers play a crucial role in ensuring smooth data flow. Imagine being an online shopper who suddenly receives irrelevant recommendations. A data engineer investigates the issue, identifies a glitch in the e-commerce platform’s data funnel, and swiftly implements seamless data pipelines.
👋 Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover topics related to Big Tech and startups through the lens of engineering managers and senior engineers. In this article, we cover one out of five topics from today’s subscriber-only The Scoop issue. To get full issues twice a week, subscribe here.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
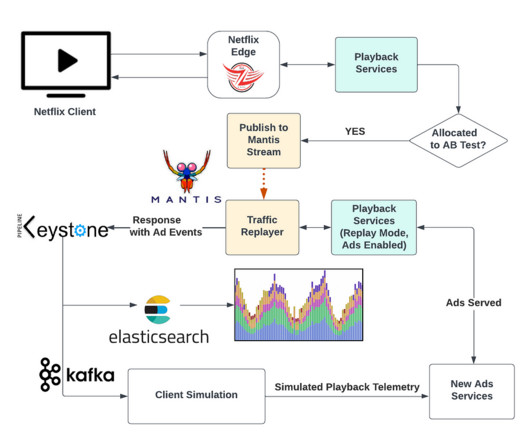
By Jose Fernandez , Ed Barker , Hank Jacobs Introduction In November 2022, we introduced a brand new tier — Basic with ads. This tier extended existing infrastructure by adding new backend components and a new remote call to our ads partner on the playback path. As we were gearing up for launch, we wanted to ensure it would go as smoothly as possible.
This article discusses the significance of large language and visual models in AI, their capabilities, potential synergies, challenges such as data bias, ethical considerations, and their impact on the market, highlighting their potential for advancing the field of artificial intelligence.
Surprised? You shouldn't. I've always been eager to learn, including 5 years ago when for the first time, I left my Apache Spark comfort zone to explore Apache Beam. Since then I had a chance to write some Dataflow streaming pipelines to fully appreciate this technology and work on AWS, GCP, and Azure. But there is some excitement for learning-from scratch I miss.
I’ve been a dog licking my wounds for some time now. Over on my Substack newsletter, I’ve been doing a small series on DSA (Data Structures and Algorithms). I tackled some of the easier stuff first, like Linked Lists, Binary Search, and the like. What’s more, I actually did most of it in Rust, since […] The post Exploring Graphs in Rust.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
Introduction In the era of data-driven decision-making, having accurate data modeling tools is essential for businesses aiming to stay competitive. As a new developer, a robust data modeling foundation is crucial for effectively working with databases. Properly configured data structures ensure a smoother workflow and prevent data loss or misplacement.
👋 Hi, this is Gergely with the monthly, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover challenges at Big Tech and startups through the lens of engineering managers and senior engineers. If you’re not a subscriber, you missed the issue on Shopify’s leveling split and a few others. Subscribe to get two full issues every week.
( credits ) Hey, this is the Data News. It's super hard to change habits, but it's how it is, the newsletter is going out on Saturday. I hope this edition finds you well. Summer is coming ☀️ Thank you all because we crossed the 3000 subscribers mark last week. Let's go for the 4000 before the end of the year 🤗 This is a almost-raw edition for this week.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
Shuffle is a permanent point in the What's new in Apache Spark series. Why? It's often one the most time consuming part of the jobs and knowing the improvement simply helps writing better pipelines.
Introduction We had an amazing opportunity to learn from Mr. Pavan. He is an experienced data engineer with a passion for problem-solving and a drive for continuous growth. Throughout the conversation, Mr. Pavan shares his journey, inspirations, challenges, and accomplishments. Thus, providing valuable insights into the field of data engineering. As we explore Mr.
GitHub surveyed 500 developers in the US for a sense of how they use AI coding tools. I examine the results and add context on how the survey was conducted.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
Summary Architectural decisions are all based on certain constraints and a desire to optimize for different outcomes. In data systems one of the core architectural exercises is data modeling, which can have significant impacts on what is and is not possible for downstream use cases. By incorporating column-level lineage in the data modeling process it encourages a more robust and well-informed design.
The newsletter, a metaphor ( credits ) Hello, after the good weather comes the storm. I'm now under the Berlin rain with 20° When I write in these conditions I feel like a tortured author writing a depressing novel while actually today I'll speak about the AI Act, Python, SQL and data platforms. Casual day at the office finally. Some personal news, next Monday and Tuesday I'll be at Berlin Buzzwords, if you're ping me, it would be a pleasure to meet and hang together.
Sometimes I think Data Engineering is the same as it was 10+ years ago when I started doing it, and sometimes I think everything has changed. It’s probably both. In some ways, the underlying concepts have not moved an inch, some certain truths and axioms still rule over us all like some distant landlord, requiring […] The post Old Dog Learn New Tricks?
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content