This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data remains an important foundation upon which businesses innovate, develop, and thrive in the fast-paced world of technology. The data industry is booming as more and more focus is shifting towards data-driven decisions. In the data ecosystem, Data Engineering is the domain that focuses on developing infrastructures that help efficient data collection, processing, and access. […] The post Must-Have Skills for Data Engineers in 2025 appeared first on WeCloudData.
Bidirectional Encoder Representations from Transformers, or BERT, is a game-changer in the rapidly developing field of natural language processing (NLP). Built by Google, BERT revolutionizes machine learning for natural language processing, opening the door to more intelligent search engines and chatbots. The design, capabilities, and impact of BERT on altering NLP applications across industries are explored in this blog.
A decade ago, Picnic set out to reinvent grocery shopping with a tech-first, customer-centric approach. What began as a bold experiment quickly grew into a high-scale operation, powered by continuous innovation and a willingness to challenge conventions. Along the way, weve learned invaluable lessons about scaling technology, fostering culture, and driving innovation.
Charles Wu, Software Engineer | Isabel Tallam, Software Engineer | Franklin Shiao, Software Engineer | Kapil Bajaj, Engineering Manager Overview Suppose you just saw an interesting rise or drop in one of your key metrics. Why did that happen? Its an easy question to ask, but much harder toanswer. One of the key difficulties in finding root causes for metric movements is that these causes can come in all shapes and sizes.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
The large model is officially a commodity. In just two short years, API-based LLMs have gone from incomprehensible to smartphone accessible. The pace of AI innovation is slowing. Real world use cases are coming into focus. Going forward, the value of your genAI applications will exist solely in the fitnessand reliabilityof your own first-party data.
The past six months has been something of a Doomsday scenario-esque countdown for TikTok, as the start date of its ban in the US crept ever closer. In the event, TikTok did indeed go offline for a few hours on 19 January, before President Trump gave the social network a stay of execution lasting 75 days. How has this uncertainty affected software engineers at the Chinese-owned social network?
Artificial Intelligence (AI) is at a turning point. For decades, conversations about Artificial General Intelligence (AGI) have been met with skepticism. Yet, recent breakthroughs in model architectures, memory management, and continual learning suggest that our machines are becoming ever more capable. This article traces a timeline of key innovations, illustrating how we have moved from simple language model reasoning to interactive , context-rich , and self-improving AI agents.
Artificial Intelligence (AI) is at a turning point. For decades, conversations about Artificial General Intelligence (AGI) have been met with skepticism. Yet, recent breakthroughs in model architectures, memory management, and continual learning suggest that our machines are becoming ever more capable. This article traces a timeline of key innovations, illustrating how we have moved from simple language model reasoning to interactive , context-rich , and self-improving AI agents.
Data scientists and Machine Learning engineers are both hot careers to follow with the recent advancement in technology. Both of these domains, data scientist vs machine learning engineer, are in high demand in any data-driven organization. Although data scientists and ML engineers share common ground in building models and handling data, they have differences in […] The post Data Scientist vs Machine Learning Engineer appeared first on WeCloudData.
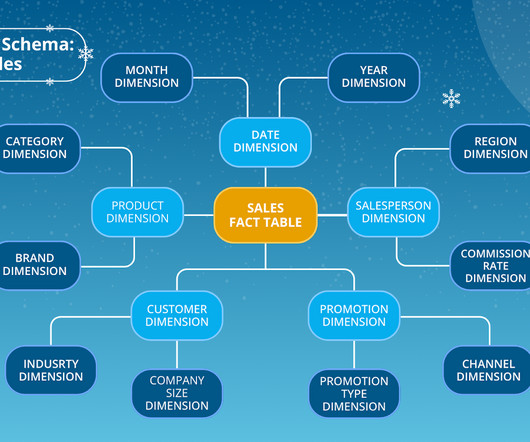
Think of your data warehouse like a well-organized library. The right setup makes finding information a breeze. The wrong one? Total chaos. Thats where data warehouse schemas come in. A data warehouse schema is a blueprint for how your data is structured and linkedusually with fact tables (for measurable data) and dimension tables (for descriptive attributes).
Learn how Confluent Champion Suguna motivates her team of engineers to solve complex problems for customerswhile challenging herself to keep growing as a manager.
AI is proving that its here to stay. While 2023 brought wonder and 2024 saw widespread experimentation, 2025 will be the year that the advertising, media and entertainment industry gets serious about AI's applications. But its complicated: AI proofs of concept are graduating from the sandbox to production, just as some of AIs biggest cheerleaders are turning a bit dour.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Using cloud managed services is often a love and hate story. On one hand, they abstract a lot of tedious administrative work to let you focus on the essentials. From another, they often have quotas and limits that you, as a data engineer, have to take into account in your daily work. These limits become even more serious when they operate in a latency-sensitive context, as the one of stream processing.
Geospatial data is everywhere in modern analytics. Consider this scenario: you’re a data analyst at a growing restaurant chain, and your CEO asks, “Where should we open our next location?” This seemingly simple question requires analyzing competitor locations, population density, traffic patterns, and demographicsall spatial data. Traditionally, answering this question would require expensive GIS (Geographic Information Systems) software or complex database setups.
In this episode of Unapologetically Technical, I interview Semih Salihoglu, Associate Professor at the University of Waterloo and co-founder and CEO of Kuzu. Semih is a researcher and entrepreneur with a background in distributed systems and databases. He shares his journey from a small city in Turkey to the hallowed halls of Yale University, where he studied computer science and economics.
If you’re working with AI/ML workloads(like me) and trying to figure out which data format to choose, this post is for you. Whether you’re a student, analyst, or engineer, knowing the differences between Apache Iceberg, Delta Lake, and Apache Hudi can save you a ton of headaches when it comes to performance, scalability, and real-time […] The post Apache Iceberg vs Delta Lake vs Hudi: Best Open Table Format for AI/ML Workloads appeared first on Analytics Vidhya.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
In 2024, our bug bounty program awarded more than $2.3 million in bounties, bringing our total bounties since the creation of our program in 2011 to over $20 million. As part of our defense-in-depth strategy , we continued to collaborate with the security research community in the areas of GenAI, AR/VR, ads tools, and more. We also celebrated the security research done by our bug bounty community as part of our annual bug bounty summit and many other industry events.
Established in 2023, Snowflakes Startup Accelerator offers early-stage startups unparalleled growth opportunities through hands-on support, extensive ecosystem access and resources that surpass what other platforms provide. To further meet the needs of early-stage startups, Snowflake is expanding the Startup Accelerator to now include up to a $200 million investment in startups building industry-specific solutions and growing their businesses on the Snowflake AI Data Cloud.
Fluss is a compelling new project in the realm of real-time data processing. I spoke with Jark Wu , who leads the Fluss and Flink SQL team at Alibaba Cloud, to understand its origins and potential. Jark is a key figure in the Apache Flink community, known for his work in building Flink SQL from the ground up and creating Flink CDC and Fluss. You can read the Q&A version of the conversation here, and don’t forget to listen to the podcast.
No Python, No SQL Templates, No YAML: Why Your Open Source Data Quality Tool Should Generate 80% Of Your Data Quality Tests Automatically As a data engineer, ensuring data quality is both essential and overwhelming. The sheer volume of tables, the complexity of the data usage, and the volume of work make manual test writing an impossible task to get done.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Part 1: Creating the Source of Truth for Impressions By: TulikaBhatt Imagine scrolling through Netflix, where each movie poster or promotional banner competes for your attention. Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. At Netflix, we call these images impressions, and they play a pivotal role in transforming your interaction from simple browsing into an immersive binge-watching experience, all tailo
Key Takeaways Trusted data is critical for AI success. Data integration ensures your AI initiatives are fueled by complete, relevant, and real-time enterprise data, minimizing errors and unreliable outcomes that could harm your business. Data integration solves key business challenges. It enables faster decision-making, boosts efficiency, and reduces costs by providing self-service access to data for AI models.
Weve previously described why we think its time to leave the leap second in the past. In todays rapidly evolving digital landscape, introducing new leap seconds to account for the long-term slowdown of the Earths rotation is a risky practice that, frankly, does more harm than good. This is particularly true in the data center space, where new protocols like Precision Time Protocol (PTP) are allowing systems to be synchronized down to nanosecond precision.
As analytics steps into the era of enterprise AI, customers requirements for a robust platform that is easy to use, connected and trusted for their current and future data needs remain unchanged. "Serverless computing" has enabled customers to use cloud capabilities without provisioning, deploying and managing either hardware or software resources.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
Introduction Using Playwright snapshots with mocked data can significantly improve the speed at which UI regression is carried out. It facilitates rapid automated inspection of UI elements across the three main browsers (Chromium, Firefox, Webkit). You can tie multiple assertions to one snapshot, which greatly increases efficiency for UI testing. This type of efficiency is pivotal in a rapidly scaling GUI application.
Announcing DataOps Data Quality TestGen 3.0: Open-Source, Generative Data Quality Software. Now With Actionable, Automatic, Data Quality Dashboards Imagine a tool that can point at any dataset, learn from your data, screen for typical data quality issues, and then automatically generate and perform powerful tests, analyzing and scoring your data to pinpoint issues before they snowball.
1. Introduction 2. Split your SQL into smaller parts 2.1. Start with a baseline validation to ensure that your changes do not change the output too much 2.2. Split your CTAs/Subquery into separate functions (or models if using dbt) 2.3. Unit test your functions for maintainability and evolution of logic 3. Conclusion 4. Required reading 1. Introduction If you’ve been in the data space long enough, you would have come across really long SQL scripts that someone had written years ago.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
Were sharing how Meta built support for data logs, which provide people with additional data about how they use our products. Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand. Users have a variety of tools they can use to manage and access their information on Meta platforms.
If you want to add rocket fuel to your organization, invest in employee education and training. While it may not be the first strategy that comes to mind, its one of the most effective ways to drive widespread business benefits, from increased efficiency to greater employee satisfaction and it deserves to be a top priority. Training couldnt be more relevant or pressing in our new AI normal, which is advancing at unprecedented speeds.
Key Takeaways: New AI-powered innovations in the Precisely Data Integrity Suite help you boost efficiency, maximize the ROI of data investments, and make confident, data-driven decisions. These enhancements improve data accessibility, enable business-friendly governance, and automate manual processes. The Suite ensures that your business remains data-driven and competitive in a rapidly evolving landscape.
Read Time: 2 Minute, 55 Second Monitoring and optimizing cloud costs is a key challenge for businesses operating in cloud environments. Snowflake provides detailed usage insights, but integrating this data with AWS CloudWatch using External Functions allows organizations to track cost in real-time, set up alerts, and optimize warehouse utilization. What if we could integrate Snowflake warehouse cost tracking with AWS CloudWatch?
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content