This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A Marketing Tech Campaign by Artem Shtatnov and Ravi Srinivas Ranganathan In an earlier blog post , we provided a high-level overview of some of the applications in the Marketing Technology team that we build to enable scale and intelligence in driving our global advertising, which reaches users on sites like The New York Times, Youtube, and thousands of others.
Summary As more companies and organizations are working to gain a real-time view of their business, they are increasingly turning to stream processing technologies to fullfill that need. However, the storage requirements for continuous, unbounded streams of data are markedly different than that of batch oriented workloads. To address this shortcoming the team at Dell EMC has created the open source Pravega project.
Uber, like most large technology companies, relies extensively on metrics to effectively monitor its entire stack. From low-level system metrics, such as memory utilization of a host, to high-level business metrics, including the number of Uber Eats orders in a … The post The Billion Data Point Challenge: Building a Query Engine for High Cardinality Time Series Data appeared first on Uber Engineering Blog.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Data analytics priorities have shifted this year. Growth factors and business priority are ever changing. Don’t blink or you might miss what leading organizations are doing to modernize their analytic and data warehousing environments. Business intelligence (BI), an umbrella term coined in 1989 by Howard Dresner, Chief Research Officer at Dresner Advisory Services, refers to the ability of end-users to access and analyze enterprise data.
In this guest post, Holden Karau , Apache Spark Committer , provides insights on how to create multi-language pipelines with Apache Spark and avoid rewriting spaCy into Java. She has already written a complementary blog post on using spaCy to process text data for Domino. Karau is a Developer Advocate at Google as well as a co-author on High Performance Spark and Learning Spark.
Netflix OSS and Spring Boot?—?Coming Full Circle Taylor Wicksell, Tom Cellucci, Howard Yuan, Asi Bross, Noel Yap, and David Liu In 2007, Netflix started on a long road towards fully operating in the cloud. Much of Netflix’s backend and mid-tier applications are built using Java, and as part of this effort Netflix engineering built several cloud infrastructure libraries and systems?
Netflix OSS and Spring Boot?—?Coming Full Circle Taylor Wicksell, Tom Cellucci, Howard Yuan, Asi Bross, Noel Yap, and David Liu In 2007, Netflix started on a long road towards fully operating in the cloud. Much of Netflix’s backend and mid-tier applications are built using Java, and as part of this effort Netflix engineering built several cloud infrastructure libraries and systems?
Summary Processing high velocity time-series data in real-time is a complex challenge. The team at PipelineDB has built a continuous query engine that simplifies the task of computing aggregates across incoming streams of events. In this episode Derek Nelson and Usman Masood explain how it is architected, strategies for designing your data flows, how to scale it up and out, and edge cases to be aware of.
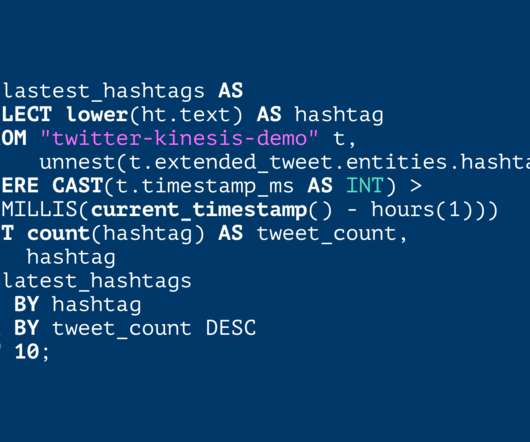
We live in a world where diverse systems—social networks, monitoring, stock exchanges, websites, IoT devices—all continuously generate volumes of data in the form of events, captured in systems like Apache Kafka and Amazon Kinesis. One can perform a wide variety of analyses, like aggregations, filtering, or sampling, on these event streams, either at the record level or over sliding time windows.
Photo credit: Carol Yepes Last month Pandora announced a public podcast beta in conjunction with the Podcast Genome Project. This rollout introduced many exciting features to our current mobile application offerings, including fully integrated and native podcast support. Ironically, one of the most interesting features and perhaps our biggest engineering win with this iteration is something that’s transparent to our end users: the inclusion of a new audio playback sequencer used exclusively for
Project Highlights ExternalDNS version 0.5.9 is ready for testing. This project allows you to control DNS records dynamically via Kubernetes resources in a DNS provider-agnostic way. ExternalDNS also successfully made its way to the Kubernetes Incubator. Check out the list of changes in this new release. Zalando-Incubator welcomed two brand new open source projects 1) Darty - a data dependency manager for data science projects.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
This blog post provides highlights and a full written transcript from the panel, “ Data Science Versus Engineering: Does It Really Have To Be This Way? ” with Amy Heineike , Paco Nathan , and Pete Warden at Domino HQ. Topics discussed include the current state of collaboration around building and deploying models, tension points that potentially arise, as well as practical advice on how to address these tension points.
In the previous blog posts in this series, we introduced the N etflix M edia D ata B ase ( NMDB ) and its salient “Media Document” data model. In this post we will provide details of the NMDB system architecture beginning with the system requirements?—?these will serve as the necessary motivation for the architectural choices we made. A fundamental requirement for any lasting data system is that it should scale along with the growth of the business applications it wishes to serve.
Summary Apache Spark is a popular and widely used tool for a variety of data oriented projects. With the large array of capabilities, and the complexity of the underlying system, it can be difficult to understand how to get started using it. Jean George Perrin has been so impressed by the versatility of Spark that he is writing a book for data engineers to hit the ground running.
Simon Whiteley and I will be back at #SQLBits 2019 talking about hashtag#DataEngineering and #DataScience in Databricks. We will look at #ApacheSpark #Python #Engineering & #MachineLearning in this full day training day. Register Now Have you looked at Azure DataBricks yet? No! Then you need to. Why you ask, there are many reasons. The number 1, knowing how to use Apache Spark will earn you more money.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Standards and open source are closely linked. Open source allows you to stay on the cutting edge, to have the latest and most innovative technologies at your disposal at all times. No one company is going to outpace the rate at which an open source community produces innovative new software. In spirit and by definition, open source excludes all things proprietary.
When we surveyed the market, we saw the need for a solution that could perform fast SQL queries on fluid JSON data , including arrays and nested objects: Best architecture to convert JSON to SQL? What are the ways to run SQL on JSON data without predefining schemas? I need database to take JSON and execute SQL. What are my options? The Challenge of SQL on JSON Some form of ETL to transform JSON to tables in SQL databases may be workable for basic JSON data with fixed fields that are known up fro
by Corey Grunewald & Matt Jaquish Since 2013, the user experience of playing videos on the Netflix website has changed very little. During this period, teams at Netflix have rolled out amazing video playback features , but the visual design and user controls of the playback UI have remained the same. The visual design and user controls of playback have been the same since 2013.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
Summary Distributed systems are complex to build and operate, and there are certain primitives that are common to a majority of them. Rather then re-implement the same capabilities every time, many projects build on top of Apache Zookeeper. In this episode Patrick Hunt explains how the Apache Zookeeper project was started, how it functions, and how it is used as a building block for other distributed systems.
The “micro frontends” idea has been around for a while now, with great resources such as this Tom Söderlund article , which includes a list of current existing implementations. In this article, I would like to take an in-depth look at the reference implementation using fragments: explain what it tries to achieve, where it falls short and possible solutions to those limitations.
by Joel Sole, Liwei Guo, Andrey Norkin, Mariana Afonso, Kyle Swanson, Anne Aaron “This is my advice to people: Learn how to cook, try new recipes, learn from your mistakes, be fearless, and above all have fun”? —?Julia Child (American chef, author, and television personality) At Netflix, we are continually refining the recipes we use to serve your favorite shows and movies at the best possible quality.
by Deva Jayaraman , Shashi Madappa , Sridhar Enugula , and Ioannis Papapanagiotou EVCache has been a fundamental part of the Netflix platform (we call it Tier-1), holding Petabytes of data. Our caching layer serves multiple use cases from signup, personalization, searching, playback, and more. It is comprised of thousands of nodes in production and hundreds of clusters all of which must routinely scale up due to the increasing growth of our members.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
Hi Greg, thank you for joining us today. I would like to start off by asking you to tell us about your background and what kicked off your 20-year career in relational database technology? Greg Rahn: I first got introduced to SQL relational database systems while I was in undergrad. I was a student system administrator for the campus computing group and at that time they were migrating the campus phone book to a new tool, new to me, known as Oracle.
Data may be the world’s most valuable resource , but the global big data talent shortage can hinder the ability of organizations to capitalize on that potential. Talent will be the key factor in linking innovation, competitiveness, and growth in the 21st century. Governments around the globe, grappling with high rates of unemployment, are eying programs to deliver big data skills training and certification to citizens that address both problematic unemployment and entice organizations to maintai
Summary Every business needs a pipeline for their critical data, even if it is just pasting into a spreadsheet. As the organization grows and gains more customers, the requirements for that pipeline will change. In this episode Christian Heinzmann, Head of Data Warehousing at Grubhub, discusses the various requirements for data pipelines and how the overall system architecture evolves as more data is being processed.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content