This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction. The Fulfillment Platform is a foundational Uber domain that enables the rapid scaling of new verticals. The platform handles billions of database transactions each day, ranging from user actions (e.g., a driver starting a trip) and system actions … The post Building Uber’s Fulfillment Platform for Planet-Scale using Google Cloud Spanner appeared first on Uber Engineering Blog.
I’m pleased to announce the release of Apache Kafka 3.0 on behalf of the Apache Kafka® community. Apache Kafka 3.0 is a major release in more ways than one. Apache […].
Taking notes helps you not to forget things, teaches you to express yourself, brainstorms your thoughts, research a topic, and so many more things. I used to take notes all my life. Maybe it’s because I’m Swiss, they say we are well organised. I used to write in OneNote for 10+ years. I have notebooks for my bachelor studies and every workplace I worked.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
By default, your tasks get executed once all the parent tasks succeed. this behaviour is what you expect in general. But what if you want something more complex? What if you would like to execute a task as soon as one of its parents succeeds? Or maybe you would like to execute a different set of tasks if a task fails? Or act differently according to if a task succeeds, fails or event gets skipped?
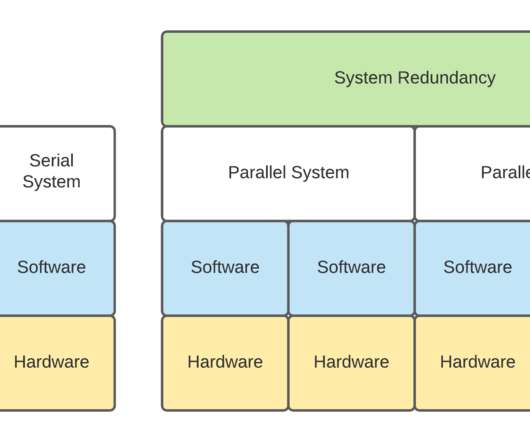
There are many ways that Apache Kafka has been deployed in the field. In our Kafka Summit 2021 presentation, we took a brief overview of many different configurations that have been observed to date. In this blog series, we will discuss each of these deployments and the deployment choices made along with how they impact reliability. In Part 1, the discussion is related to: Serial and Parallel Systems Reliability as a concept, Kafka Clusters with and without Co-Located Apache Zookeeper, and Kafka
Uber recently launched a new capability: Ads on UberEats. With this new ability came new challenges that needed to be solved at Uber, such as systems for ad auctions, bidding, attribution, reporting, and more. This article focuses on how we … The post Real-Time Exactly-Once Ad Event Processing with Apache Flink, Kafka, and Pinot appeared first on Uber Engineering Blog.
Uber recently launched a new capability: Ads on UberEats. With this new ability came new challenges that needed to be solved at Uber, such as systems for ad auctions, bidding, attribution, reporting, and more. This article focuses on how we … The post Real-Time Exactly-Once Ad Event Processing with Apache Flink, Kafka, and Pinot appeared first on Uber Engineering Blog.
The full inventory of three online Kafka Summits in 2021 is now complete. Kafka Summit Americas wrapped just yesterday. Being a part of the event team and the Program Committee, […].
1. Introduction 2. What is scaling & why do we need it? 3. Types of scaling 4. Choose your scaling strategy 5. Conclusion 6. Further reading 7. References 1. Introduction Choosing tools/frameworks to scale your data pipelines can be confusing. If you have struggled with Data pipelines that randomly crash Finding guides on how to scale your data pipelines from the ground up Then this post is for you.
Summary The promise of online services is that they will make your life easier in exchange for collecting data about you. The reality is that they use more information than you realize for purposes that are not what you intended. There have been many attempts to harness all of the data that you generate for gaining useful insights about yourself, but they are generally difficult to set up and manage or require software development experience.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
The more an enterprise wants to know about itself and its business prospects, the more data it needs to collect and analyze. Additionally, the more data it collects and stores, the better its ability to know customers, to find new ones, and to provide more of what they want to buy. Sounds simple, but a surprising majority of U.S. companies (about two-thirds, according to CIO.com ) are only now getting tuned in to become fully functioning data-driven enterprises by starting new initiatives, scali
Introduction. Uber’s GSS (Global Scaled Solutions) team runs scaled programs for diverse products and businesses, including but not limited to Eats, Rides, and Freight. The team transforms Uber’s ideas into agile, global solutions by designing and implementing scalable solutions. One … The post Streaming Real-Time Analytics with Redis, AWS Fargate, and Dash Framework appeared first on Uber Engineering Blog.
We’re pleased to announce ksqlDB 0.21.0! This release includes a major upgrade to ksqlDB’s foreign-key joins, the new data type BYTES, and a new ARRAY_CONCAT function. All of these features […].
Data organizations don’t always have the budget or schedule required for DataOps when conceived as a top-to-bottom, enterprise-wide transformational change. An essential part of the DataOps methodology is Agile Development , which breaks development into incremental steps. DataOps can and should be implemented in small steps that complement and build upon existing workflows and data pipelines.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Summary The accuracy and availability of data has become critically important to the day-to-day operation of businesses. Similar to the practice of site reliability engineering as a means of ensuring consistent uptime of web services, there has been a new trend of building data reliability engineering practices in companies that rely heavily on their data.
Groupon is modernizing with Vantage on AWS to better match its data & analytics with demands of its global business. The Cloud allows Groupon to better leverage infrastructure dollars, support more technology projects and capture opportunity.
Many customers looking at modernizing their pipeline orchestration have turned to Apache Airflow, a flexible and scalable workflow manager for data engineers. With 100s of open source operators, Airflow makes it easy to deploy pipelines in the cloud and interact with a multitude of services on premise, in the cloud, and across cloud providers for a true hybrid architecture. .
Problem. Uber deploys a few storage technologies to store business data based on their application model. One such technology is called Schemaless , which enables the modeling of related entries in one single row of multiple columns, as well as … The post Jellyfish: Cost-Effective Data Tiering for Uber’s Largest Storage System appeared first on Uber Engineering Blog.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
The rise of fully managed cloud services fundamentally changed the technology landscape and introduced benefits like increased flexibility, accelerated deployment, and reduced downtime. Confluent offers a portfolio of fully managed […].
By Alex Borysov , Ricky Gardiner Background At Netflix, we heavily use gRPC for the purpose of backend to backend communication. When we process a request it is often beneficial to know which fields the caller is interested in and which ones they ignore. Some response fields can be expensive to compute, some fields can require remote calls to other services.
Summary Python has beome the de facto language for working with data. That has brought with it a number of challenges having to do with the speed and scalability of working with large volumes of information.There have been many projects and strategies for overcoming these challenges, each with their own set of tradeoffs. In this episode Ehsan Totoni explains how he built the Bodo project to bring the speed and processing power of HPC techniques to the Python data ecosystem without requiring any
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
One of the most substantial big data workloads over the past fifteen years has been in the domain of telecom network analytics. Where does it stand today? What are its current challenges and opportunities? In a sense, there have been three phases of network analytics: the first was an appliance based monitoring phase; the second was an open-source expansion phase; and the third – that we are in right now – is a hybrid-data-cloud and governance phase.
Blog Building a Remote-First Culture Written by Amanda Bulger on Sep 15, 2021 This morning I was planning an offsite for our team – our first one since Datakin was founded during the pandemic – and I had a realization: I haven’t met most of these people in person yet! We’ve been working together for months and months, solving interesting problems and planning social events, but we have been restricted to knowing each other through a tiny box on a screen.
GraphQL and Apache Kafka® are sometimes troubled with misconceptions. One of the reasons for this is that people are often familiar with one but not the other. GraphQL is mostly […].
Written by Michael Possumato , Nick Tomlin , Jordan Andree , Andrew Shim , and Rahul Pilani. As we continue to grow here at Netflix, the needs of Revenue and Growth Engineering are rapidly evolving; and our tools must also evolve just as rapidly. The Revenue and Growth Tools (RGT) team decided to set off on a journey to build tools in an abstract manner to have solutions readily available within our organization.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
Summary Biology has been gaining a lot of attention in recent years, even before the pandemic. As an outgrowth of that popularity, a new field has grown up that pairs statistics and compuational analysis with scientific research, namely bioinformatics. This brings with it a unique set of challenges for data collection, data management, and analytical capabilities.
Below is our final post (5 of 5) on combining data mesh with DataOps to foster innovation while addressing the challenges of a data mesh decentralized architecture. We see a DataOps process hub like the DataKitchen Platform playing a central supporting role in successfully implementing a data mesh. DataOps excels at the type of workflow automation that can coordinate interdependent domains, manage order-of-operations issues and handle inter-domain communication.
The CDP Operational Database ( COD ) builds on the foundation of existing operational database capabilities that were available with Apache HBase and/or Apache Phoenix in legacy CDH and HDP deployments. Within the context of a broader data and analytics platform implemented in the Cloudera Data Platform ( CDP ), COD will function as highly scalable relational and non-relational transactional database allowing users to leverage big data in operational applications as well as the backbone of the a
The word machine learning is buzzing so loud that almost every IT professional has heard this term by now. With time, machine learning has become more applied, and every industry is leveraging it. Most software applications today have sophisticated machine learning algorithms in action behind the scenes - Welcome to the world of MLOps that makes these ML models successful in production.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content