This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
No-code or low-code functionalities in data science have gained significant traction in recent years. These solutions are well-proven and matured, and they make data science more accessible to a wider range of people.
👋 Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover topics related to Big Tech and startups through the lens of engineering managers and senior engineers. In this article, we cover three out of seven topics from today’s subscriber-only issue Three Cloud Providers, Three Outages: Three Different Responses.
In today’s rapidly evolving digital landscape, seamless data, applications, and device integration are more pressing than ever. Enter Microsoft Fabric, a cutting-edge solution designed to revolutionize how we interact with technology. This article will explore the key features and benefits, identify the ideal users for this solution, and guide you on when and how to […] The post Introduction of Microsoft Fabric appeared first on Analytics Vidhya.
In Airflow, DAGs (your data pipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs. You’ll learn how to: Create a standardized process for debugging to quickly diagnose errors in your DAGs Identify common issues with DAGs, tasks, and connections Distinguish between Airflow-relate
cross-project dependencies ( credits ) Over the last few years, dbt has become a de facto standard enabling companies to collaborate easily on data transformations. With dbt, you can apply software engineering practices to SQL development. Managing your SQL patrimony has never been easier. So, yes, dbt is cool but there is a common pattern with it: you accumulate SQL queries.
Are you looking for a way to choose one task or another? Do you want to execute a task based on a condition? Do you have multiple tasks, but only one should be executed if a criterion is valid? You’ve come to the right place! The BranchPythonOperator does precisely what you are looking for. It’s common to have DAGs with different execution flows, and you want to follow only one, depending on a value or a condition.
Summary Databases are the core of most applications, whether transactional or analytical. In recent years the selection of database products has exploded, making the critical decision of which engine(s) to use even more difficult. In this episode Tanya Bragin shares her experiences as a product manager for two major vendors and the lessons that she has learned about how teams should approach the process of tool selection.
Summary Databases are the core of most applications, whether transactional or analytical. In recent years the selection of database products has exploded, making the critical decision of which engine(s) to use even more difficult. In this episode Tanya Bragin shares her experiences as a product manager for two major vendors and the lessons that she has learned about how teams should approach the process of tool selection.
👋 Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover topics related to Big Tech and startups through the lens of engineering managers and senior engineers. In this article, we cover three out of eight topics from today’s deepdive into tech scaleup Chronosphere. To get full issues twice a week, subscribe here.
Is there anything more Chad than Apache Airflow … and Rust? I think not you whimp. What two things do I love most? At the moment Rust and Airflow are at least somewhere at the top of that list. I wring my hands sometimes, wishing that things and technologies somehow come together into some bubbling […] The post The Ultimate Data Engineering Chadstack.
Do not get the title wrong! Having applyInPandasWithState in the PySpark API is huge! However, due to Python duck typing, some operations are more difficult and more risky to express in the code than in the strongly typed Scala API.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
Airflow Sensors are one of the most common tasks in data pipelines. Why? Because a Sensor waits for a condition to be true to complete. Do you need to wait for a file? Check if an SQL entry exists? Delay the execution of a DAG? That’s the few possibilities of the Airflow Sensors. If you want to make complex and robust data pipelines, you have to understand how Sensors work genuinely.
Summary Building streaming applications has gotten substantially easier over the past several years. Despite this, it is still operationally challenging to deploy and maintain your own stream processing infrastructure. Decodable was built with a mission of eliminating all of the painful aspects of developing and deploying stream processing systems for engineering teams.
👋 Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover topics related to Big Tech and startups through the lens of engineering managers and senior engineers. In this article, we cover two out of seven topics from today’s full issue on The Man Behind the Big Tech Comics. To get full issues twice a week, subscribe here.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
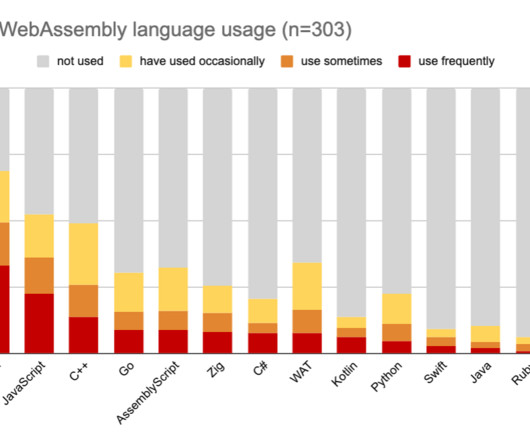
The State of WebAssembly 2023 survey has closed, the results are in … and they are fascinating! If you want the TL;DR; here are the highlights: Rust and JavaScript usage is continuing to increase, but some more notable changes are happening a little further down - with both Swift and Zig seeing a significant increase in adoption. When it comes to which languages developers ‘desire’, with Zig, Kotlin and C# we see that desirability exceeds current usage WebAssembly is still most often used for we
Overview In the rippled 1.12.0 release, the AMM amendment stands out as a significant feature in both size and scope. Since September 2022, the RippleX performance team has collaborated closely with the engineering team responsible for the AMM feature implementation. This report presents a thorough overview of our testing approach, findings, and key takeaways.
Summary The primary application of data has moved beyond analytics. With the broader audience comes the need to present data in a more approachable format. This has led to the broad adoption of data products being the delivery mechanism for information. In this episode Ranjith Raghunath shares his thoughts on how to build a strategy for the development, delivery, and evolution of data products.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
Python’s popularity has more than doubled in the past decade¹ and it is quickly becoming the preferred language for development across machine learning, application development, pipelines, and more. One of our goals at Snowflake is to ensure we continue to deliver a best-in-class platform for Python developers. Snowflake customers are already harnessing the power of Python through Snowpark , a set of runtimes and libraries that securely deploy and process non-SQL code directly in Snowflake.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
Think of how many times a day you use some type of search functionality across your devices and applications to discover information, find a contact, or a new job opportunity. The truth is we all depend on the ability to search for things online, and finding the right match to the information, organization, or to a job that maps to your skills and interests makes all the difference in our experiences and the knowledge we can gain.
Summary The insurance industry is notoriously opaque and hard to navigate. Max Cho found that fact frustrating enough that he decided to build a business of making policy selection more navigable. In this episode he shares his journey of data collection and analysis and the challenges of automating an intentionally manual industry. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
At Snowflake, we’re committed to helping customers effectively manage and optimize spend. To this effect, we’re excited to launch the public preview of Budgets on AWS today, which enables customers to set spending limits and receive notifications for Snowflake credit usage for either their entire Snowflake account or for a custom group of resources within an account.
1. Introduction 2. Six Steps for a Clean Data Warehouse 2.1. Understand the business 2.2. Make data easy to use with the appropriate data model 2.3. Good input data is necessary for a good data warehouse 2.4. Define Source of Truth (SOT) and trace its usage 2.5. Keep stakeholders in the loop for a more significant impact 2.6. Watch out for org-level red flags ?
Summary Artificial intelligence applications require substantial high quality data, which is provided through ETL pipelines. Now that AI has reached the level of sophistication seen in the various generative models it is being used to build new ETL workflows. In this episode Jay Mishra shares his experiences and insights building ETL pipelines with the help of generative AI.
With Airflow being the open-source standard for workflow orchestration, knowing how to write Airflow DAGs has become an essential skill for every data engineer. This eBook provides a comprehensive overview of DAG writing features with plenty of example code. You’ll learn how to: Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to Write DAGs that adapt to your data at runtime and set up alerts and notifications Scale you
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content